 6 将MySql数据迁移到TiDB
6 将MySql数据迁移到TiDB
# 1 MySQL环境准备
# 1.1 MySQL测试数据库
Mysql 官方提供了了一套名为:Employees Sample Database 的测试库(该测试库含有6个表,总计4百万数据记录)
# 表结构
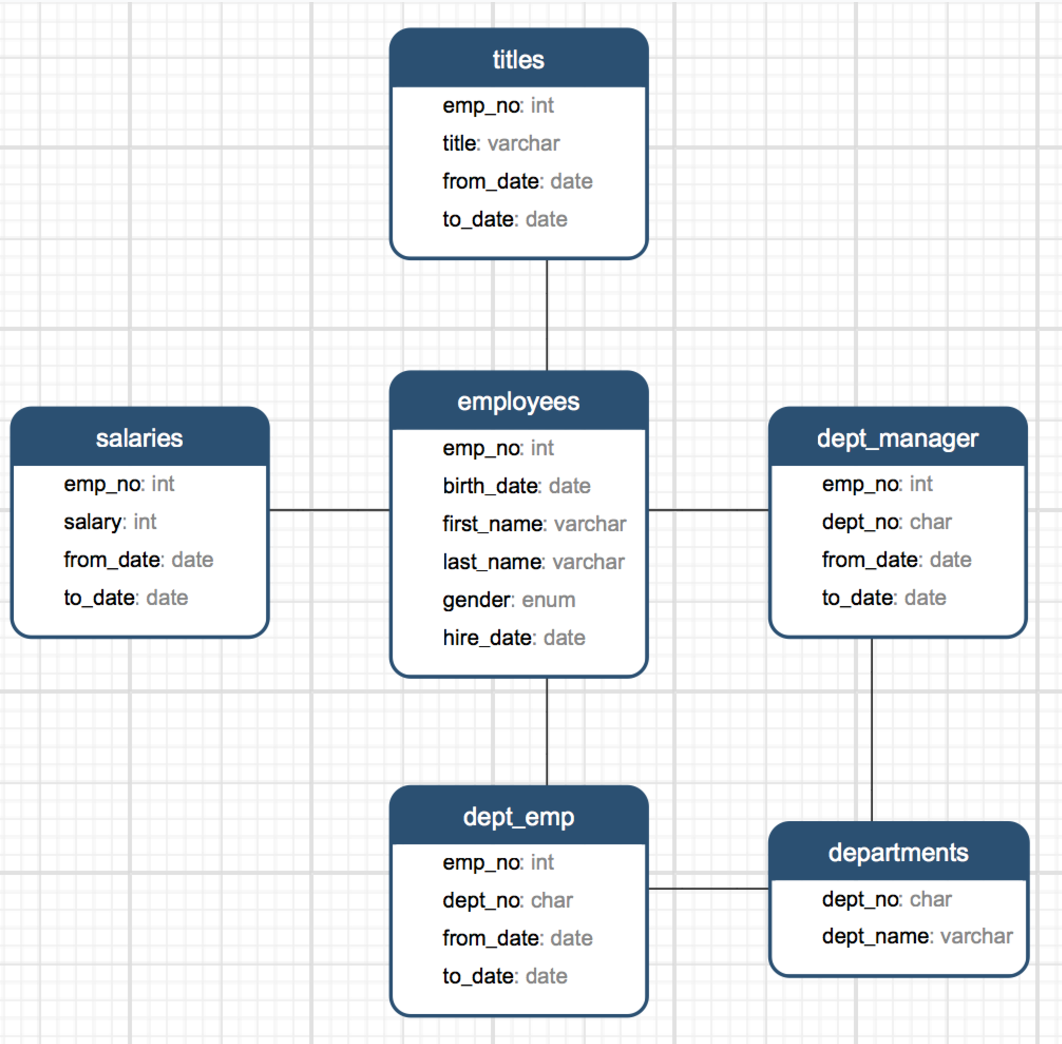
# 1.1.1 导入数据
下载后解压
test_db-master.zip,然后登录 mysql 导入即可
[mysqld]
########bin-log settings########
#show variables like 'log_%';
log_bin=mysql-bin
server_id=1
binlog_format=ROW
# 创建MySQL数据库
[root@linux30 tidb]# docker run --name mysql-tidb -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /opt/tidb/mysql:/opt -v /opt/tidb/etc/mysql:/etc/mysql mysql:5.7.38
b59ff5c7a4836a2f13c4863842fa73a87c2980efa5537c06c0946d35d47dc392
[root@linux30 tidb]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b59ff5c7a483 mysql:8.0.22 "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp mysql-tidb
[root@linux30 tidb]# docker exec -it mysql-tidb bash
root@b59ff5c7a483:/# cd /opt/test_db-master/ && ls
Changelog images load_salaries1.dump sakila test_versions.sh
README.md load_departments.dump load_salaries2.dump show_elapsed.sql
employees.sql load_dept_emp.dump load_salaries3.dump sql_test.sh
employees_partitioned.sql load_dept_manager.dump load_titles.dump test_employees_md5.sql
employees_partitioned_5.1.sql load_employees.dump objects.sql test_employees_sha.sql
root@b59ff5c7a483:/opt/test_db-master# mysql -uroot -p123456 < employees.sql
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
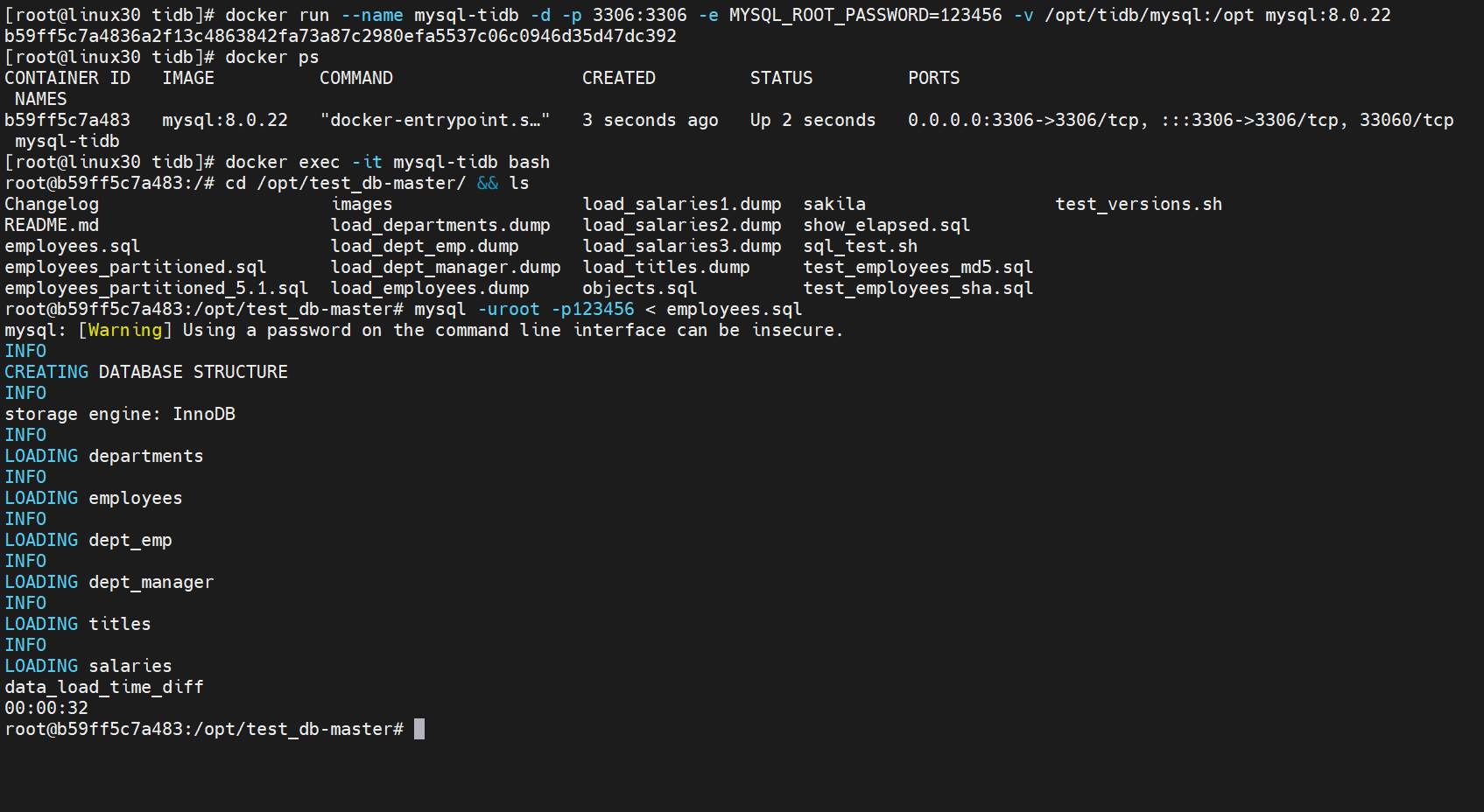
# 1.1.2 验证是否成功
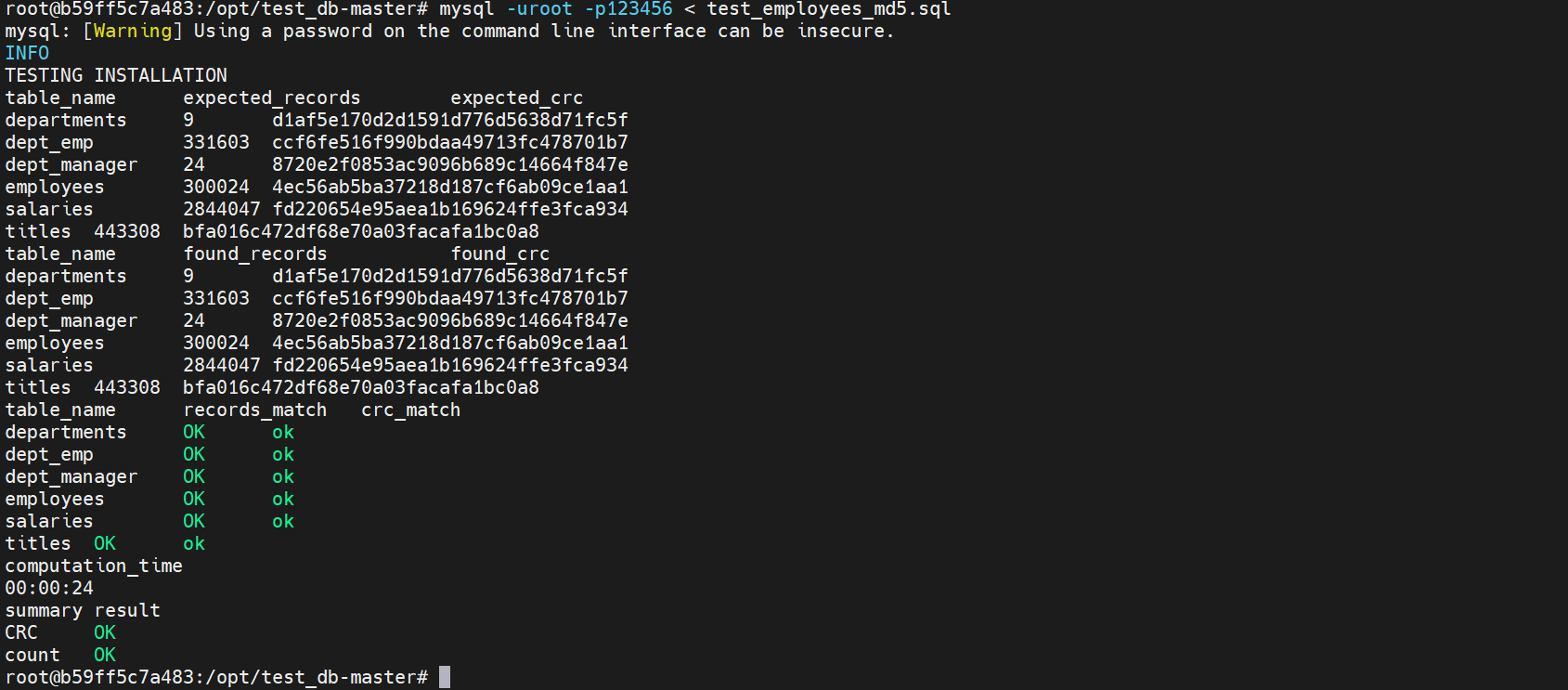
root@b59ff5c7a483:/opt/test_db-master# mysql -uroot -p123456 < test_employees_md5.sql
# 2 DM数据迁移
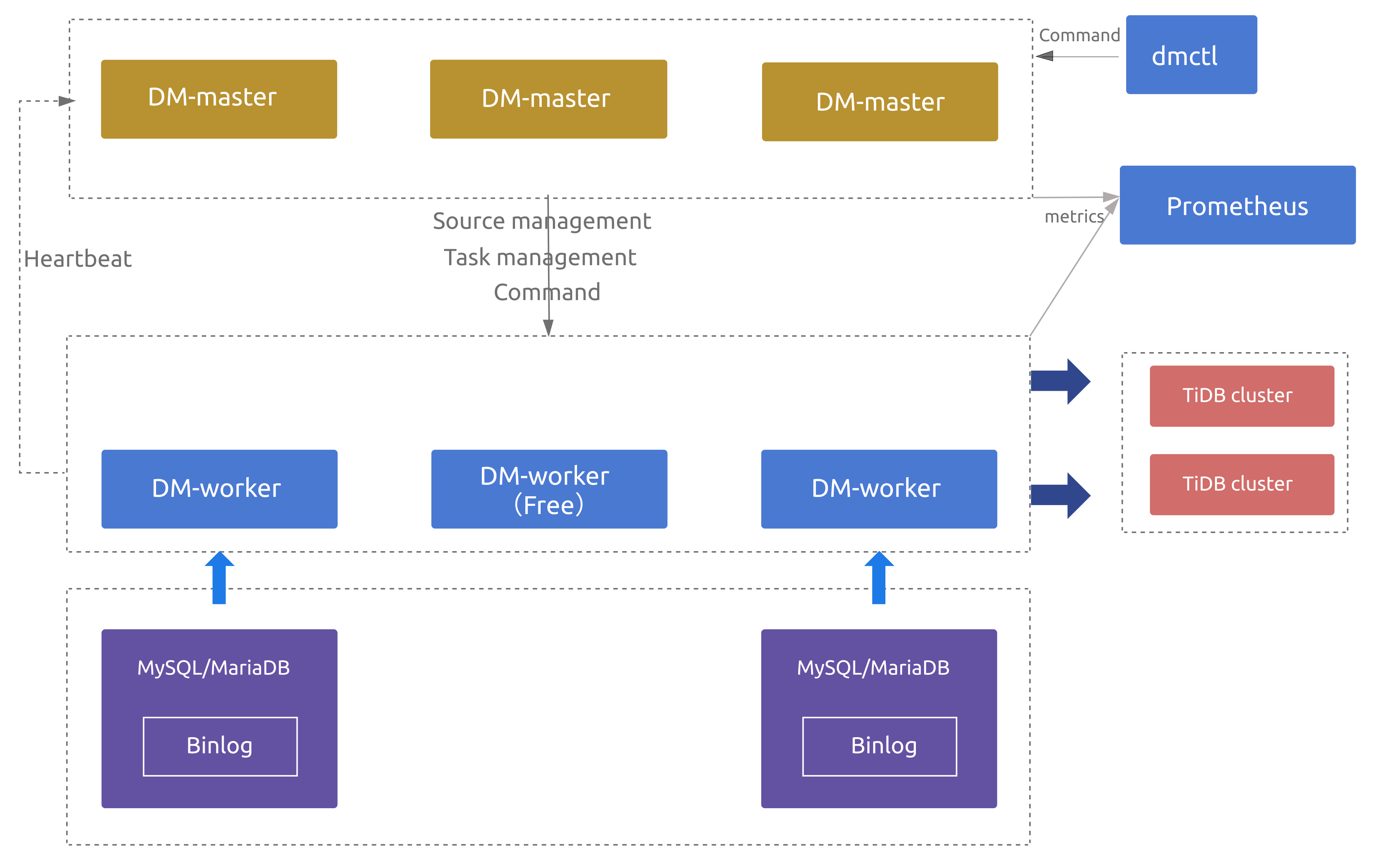
# 2.1 TiUP DM 组件简介
TiDB Data Migration (DM) 是一体化的数据迁移任务管理工具,支持从与 MySQL 协议兼容的数据库(MySQL、MariaDB、Aurora MySQL)到 TiDB 的数据迁移,DM 工具旨在降低数据迁移的运维成本。
# 2.1.1 基本功能
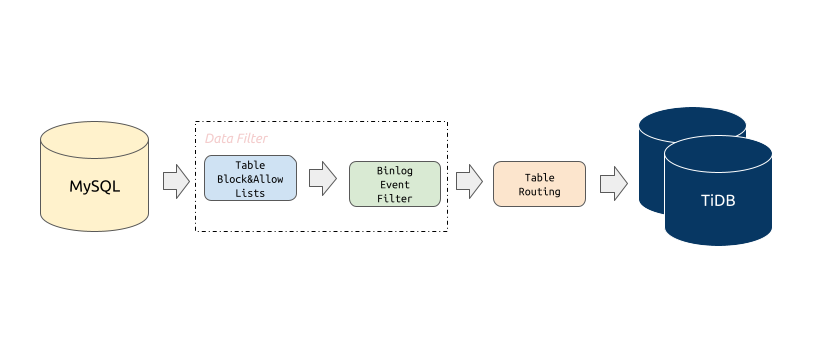
Block & allow lists
上游数据库实例表的黑白名单过滤规则,可以用来过滤或者只迁移某些
database/table的所有操作。
Block & Allow Lists 的过滤规则类似于 MySQL replication-rules-db/replication-rules-table,用于过滤或指定只迁移某些数据库或某些表的所有操作。
block-allow-list: # 如果 DM 版本 <= v2.0.0-beta.2 则使用 black-white-list。
rule-1:
do-dbs: ["test*"] # 非 ~ 字符开头,表示规则是通配符;v1.0.5 及后续版本支持通配符规则。
do-tables:
- db-name: "test[123]" # 匹配 test1、test2、test3。
tbl-name: "t[1-5]" # 匹配 t1、t2、t3、t4、t5。
- db-name: "test"
tbl-name: "t"
rule-2:
do-dbs: ["~^test.*"] # 以 ~ 字符开头,表示规则是正则表达式。
ignore-dbs: ["mysql"]
do-tables:
- db-name: "~^test.*"
tbl-name: "~^t.*"
- db-name: "test"
tbl-name: "t"
ignore-tables:
- db-name: "test"
tbl-name: "log"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
do-dbs:要迁移的库的白名单,类似于 MySQL 中的replicate-do-db。ignore-dbs:要迁移的库的黑名单,类似于 MySQL 中的replicate-ignore-db。do-tables:要迁移的表的白名单,类似于 MySQL 中的replicate-do-table。ignore-tables:要迁移的表的黑名单,类似于 MySQL 中的replicate-ignore-table。
以上参数值以
~开头时均支持使用正则表达式来匹配库名、表名。
Binlog event filter
Binlog event filter 是比迁移表黑白名单更加细粒度的过滤规则,可以指定只迁移或者过滤掉某些
schema / table的指定类型 binlog,比如INSERT、TRUNCATE TABLE。
Binlog Event Filter 用于过滤源数据库中特定表的特定类型操作,比如过滤掉表 test.sbtest 的 INSERT 操作或者过滤掉库 test 下所有表的 TRUNCATE TABLE 操作。
filters:
rule-1:
schema-pattern: "test_*"
table-pattern: "t_*"
events: ["truncate table", "drop table"]
sql-pattern: ["^DROP\\s+PROCEDURE", "^CREATE\\s+PROCEDURE"]
action: Ignore
2
3
4
5
6
7
schema-pattern/table-pattern:对匹配上的上游 MySQL/MariaDB 实例的表的 binlog events 或者 DDL SQL 语句通过以下规则进行过滤。events:binlog events 数组,仅支持从以下Event中选择一项或多项。Event 分类 解释 all 代表包含下面所有的 events all dml 代表包含下面所有 DML events all ddl 代表包含下面所有 DDL events none 代表不包含下面所有 events none ddl 代表不包含下面所有 DDL events none dml 代表不包含下面所有 DML events insert DML insert DML event update DML update DML event delete DML delete DML event create database DDL create database event drop database DDL drop database event create table DDL create table event create index DDL create index event drop table DDL drop table event truncate table DDL truncate table event rename table DDL rename table event drop index DDL drop index event alter table DDL alter table event sql-pattern:用于过滤指定的 DDL SQL 语句,支持正则表达式匹配,例如上面示例中的"^DROP\\s+PROCEDURE"。
Table routing
Table routing 提供将上游 MySQL/MariaDB 实例的某些表迁移到下游指定表的功能。
Table Routing 是将源数据库的表迁移到下游指定表的路由功能,比如将源数据表 test.sbtest1 的数据同步到 TiDB 的表 test.sbtest2。它也是分库分表合并迁移所需的一个核心功能。
routes:
rule-1:
schema-pattern: "test_*"
table-pattern: "t_*"
target-schema: "test"
target-table: "t"
rule-2:
schema-pattern: "test_*"
target-schema: "test"
2
3
4
5
6
7
8
9
# 2.1.2 使用限制
数据库版本
- 5.5
<MySQL 版本<8.0 - MariaDB 版本
>=10.1.2
DDL 语法兼容性
- 目前,TiDB 部分兼容 MySQL 支持的 DDL 语句。因为 DM 使用 TiDB parser 来解析处理 DDL 语句,所以目前仅支持 TiDB parser 支持的 DDL 语法
- DM 遇到不兼容的 DDL 语句时会报错。要解决此报错,需要使用 dmctl 手动处理,要么跳过该 DDL 语句,要么用指定的 DDL 语句来替换它
# 2.2 TiUP安装 DM组件
# 2.2.1 安装TiUP DM 组件
[root@linux30 tidb]# tiup install dm
# 2.2.2 更新 TiUP DM 组件
如果已经安装,则更新 TiUP DM 组件至最新版本:
[root@linux30 tidb]# tiup update --self && tiup update dm
预期输出
Update successfully!字样。

# 2.3 TiUP部署 DM组件
# 2.3.1 编辑初始化配置
需要根据不同的集群拓扑,编辑 TiUP 所需的集群初始化配置文件。
新建一个配置文件
topology.yaml,部署 1 个 DM-master、1个 DM-worker 的配置如下
[root@linux30 tidb]# vi topology.yaml
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/opt/tidb/tidb-deploy/dm"
data_dir: "/opt/tidb/tidb-data/dm"
# arch: "amd64"
master_servers:
- host: 192.168.10.30
worker_servers:
- host: 192.168.10.30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意:
- 如果不需要确保 DM 集群高可用,则可只部署 1 个 DM-master 节点,且部署的 DM-worker 节点数量不少于上游待迁移的 MySQL/MariaDB 实例数。
- 如果需要确保 DM 集群高可用,则推荐部署 3 个 DM-master 节点,且部署的 DM-worker 节点数量大于上游待迁移的 MySQL/MariaDB 实例数(如 DM-worker 节点数量比上游实例数多 2 个)。
# 2.3.2 部署命令格式
通过 TiUP 进行集群部署可以使用密钥或者交互密码方式来进行安全认证:
- 如果是密钥方式,可以通过
-i或者--identity_file来指定密钥的路径; - 如果是密码方式,可以通过
-p进入密码交互窗口; - 如果已经配置免密登录目标机,则不需填写认证。
tiup dm deploy dm-test ${version} ./topology.yaml --user root [-p] [-i /home/root/.ssh/gcp_rsa]
以上部署命令中:
- 通过 TiUP DM 部署的集群名称为
dm-test。 --user root:通过 root 用户登录到目标主机完成集群部署,该用户需要有 ssh 到目标机器的权限,并且在目标机器有 sudo 权限。也可以用其他有 ssh 和 sudo 权限的用户完成部署。-i及-p:非必选项,如果已经配置免密登录目标机,则不需填写,否则选择其一即可。-i为可登录到目标机的 root 用户(或--user指定的其他用户)的私钥,也可使用-p交互式输入该用户的密码。
预期日志结尾输出会有
Deployed clusterdm-testsuccessfully关键词,表示部署成功。
# 2.3.3 检查最新版本DM组件
部署版本为
${version},可以通过执行tiup list dm-master来查看 TiUP 支持的最新版本
[root@linux30 tidb]# tiup list dm-master
我们发现有个版本是v5.3.0
# 2.3.4 执行部署命令
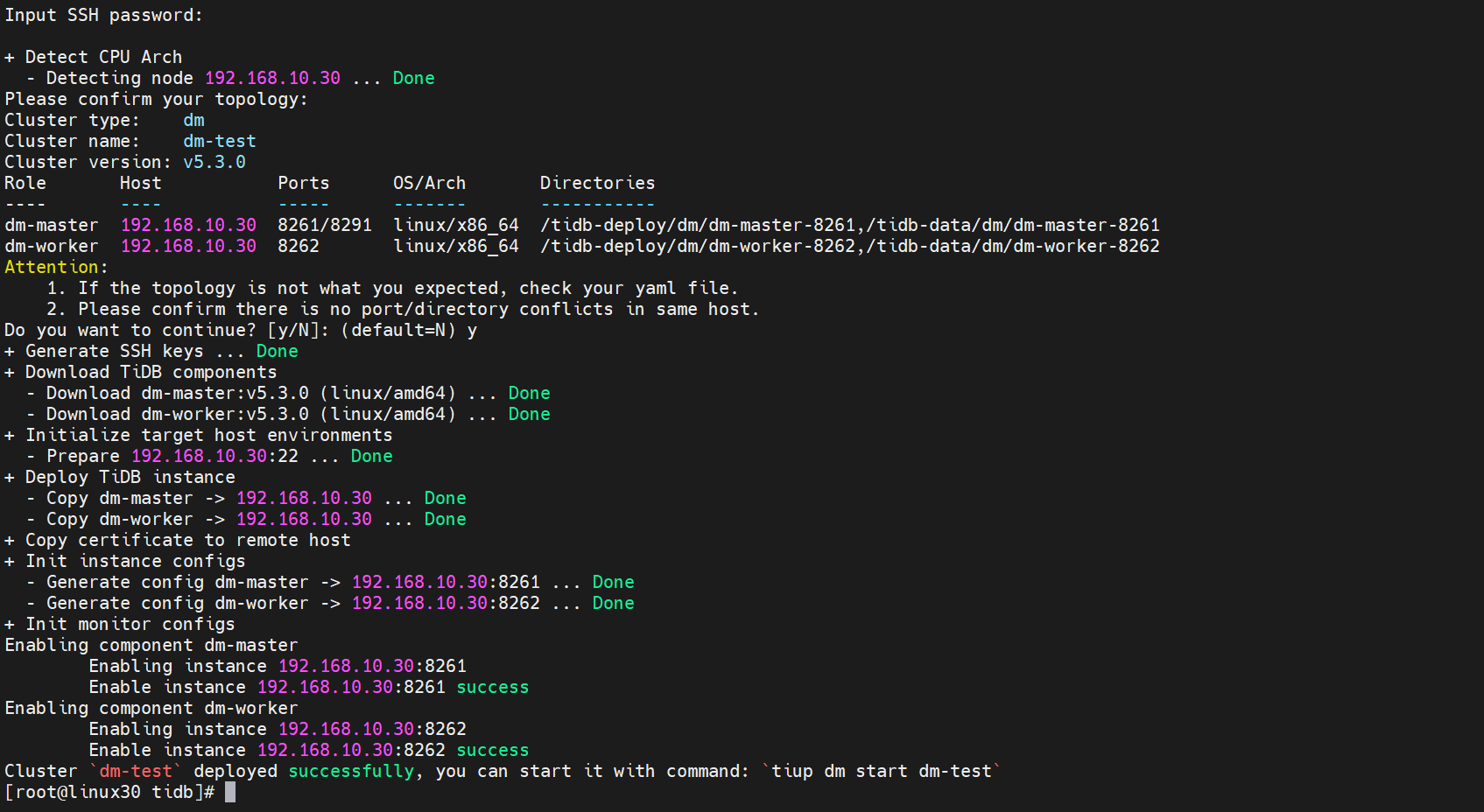
[root@linux30 tidb]# tiup dm deploy dm-test 5.3.0 ./topology.yaml --user root -p
出现如下界面,选择y继续,输入密码后继续安装
继续安装后,安装完成后输出
deployed successfully代表安装完成
# 2.3.5 TiUP 查看集群情况
TiUP 支持管理多个 DM 集群,该命令会输出当前通过 TiUP DM 管理的所有集群信息,包括集群名称、部署用户、版本、密钥信息等
[root@linux30 tidb]# tiup dm list

# 2.3.6 检查部署的 DM 集群
执行如下命令检查
dm-test集群情况
[root@linux30 tidb]# tiup dm display dm-test
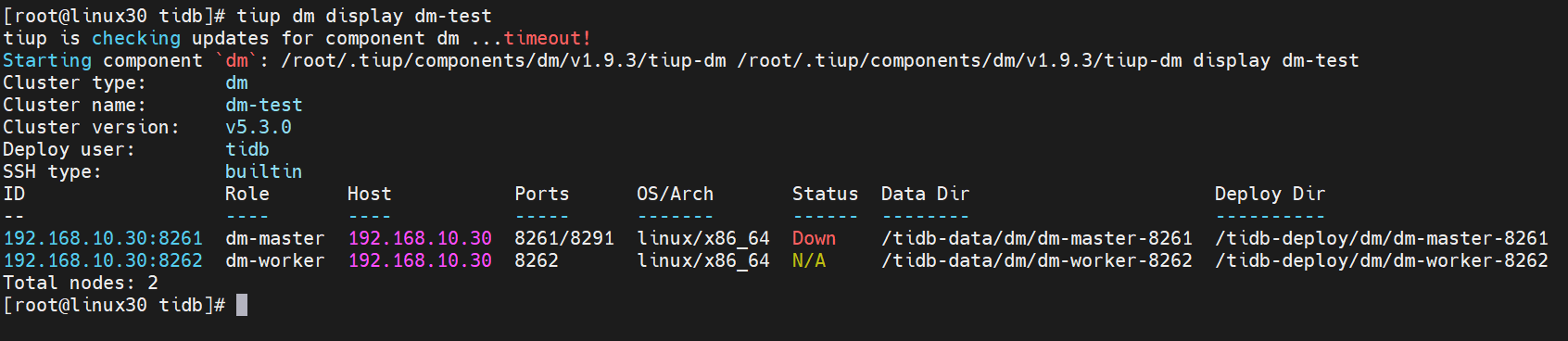
预期输出包括 dm-test 集群中实例 ID、角色、主机、监听端口和状态(由于还未启动,所以状态为 Down/inactive)、目录信息。
# 2.3.7 启动集群
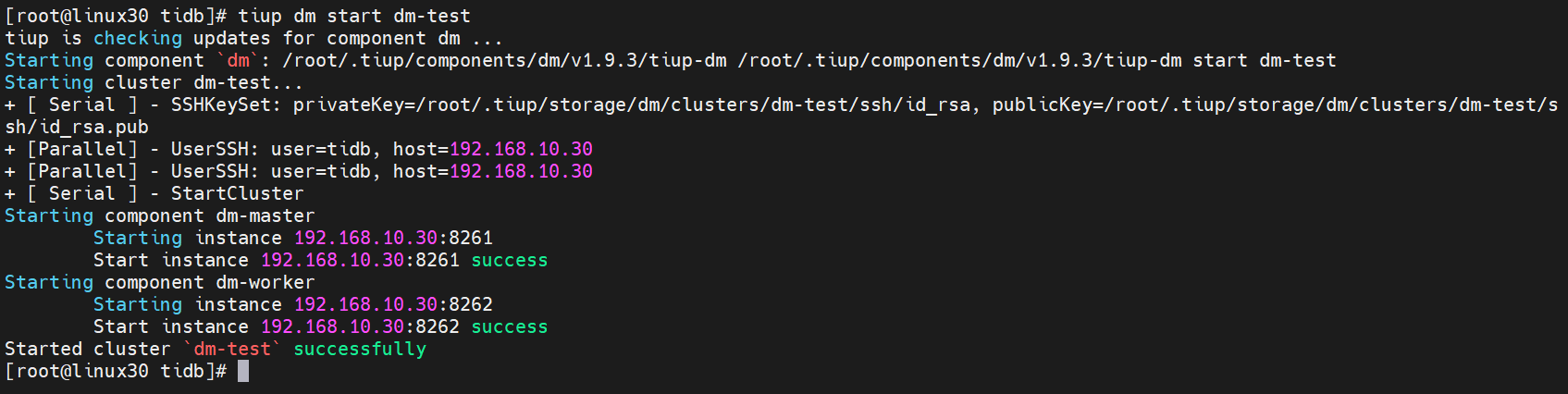
预期结果输出
Started clusterdm-testsuccessfully表示启动成功。
[root@linux30 tidb]# tiup dm start dm-test
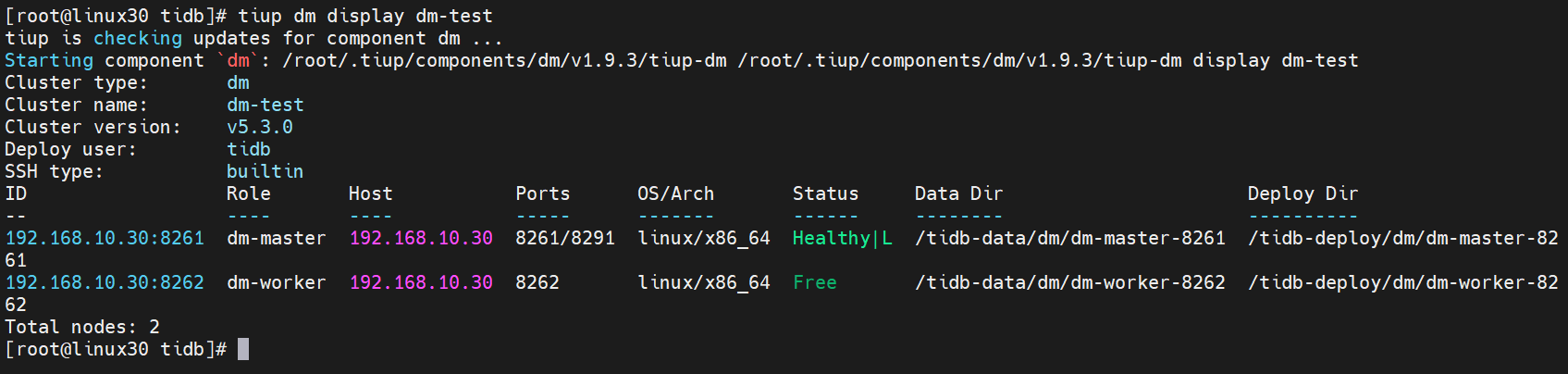
# 2.3.8 验证集群运行状态
在输出结果中,如果 Status 状态信息为
Up,说明集群状态正常。
[root@linux30 tidb]# tiup dm display dm-test
# 2.4 安装dmctl 运维组件
dmctl 是用来运维 DM 集群的命令行工具,支持交互模式和命令模式。
# 2.4.1 检查dmctl最新版本
通过如下命令可用查看
dmctl版本列表
[root@linux30 tidb]# tiup list dmctl
我们发现一个版本是
v5.3.0
# 2.4.2 安装dmctl组件
通过如下命令可用安装dmctl组件,冒号后面是需要安装的版本号
[root@linux30 tidb]# tiup install dmctl:v5.3.0

# 2.5 使用 DM 迁移数据
# 2.4.1 需要的权限
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
- REPLICATION SLAVE
# 2.4.2 MySQL服务授权
#创建tidb用户密码是 tidb并授权外部所以IP可以访问
mysql> CREATE USER 'tidb'@'%' IDENTIFIED BY 'tidb';
Query OK, 0 rows affected (0.02 sec)
# 授权SELECT,RELOAD,LOCK TABLES,REPLICATION CLIENT 权限给tidb用户
mysql> GRANT SELECT,RELOAD,LOCK TABLES,REPLICATION CLIENT,REPLICATION SLAVE ON *.* TO 'tidb'@'%';
Query OK, 0 rows affected (0.01 sec)
# 刷新数据库
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.01 sec)
2
3
4
5
6
7
8
9
# 2.4.3 打开mysql的binlog
因为DM同步需要MySQL开启binlog日志,修改my.cnf配置文件,并重启
[mysqld]
########bin-log settings########
#show variables like 'log_%';
log_bin=mysql-bin
server_id=1
binlog_format=ROW
2
3
4
5
6
# 2.4.4 MySQL检查
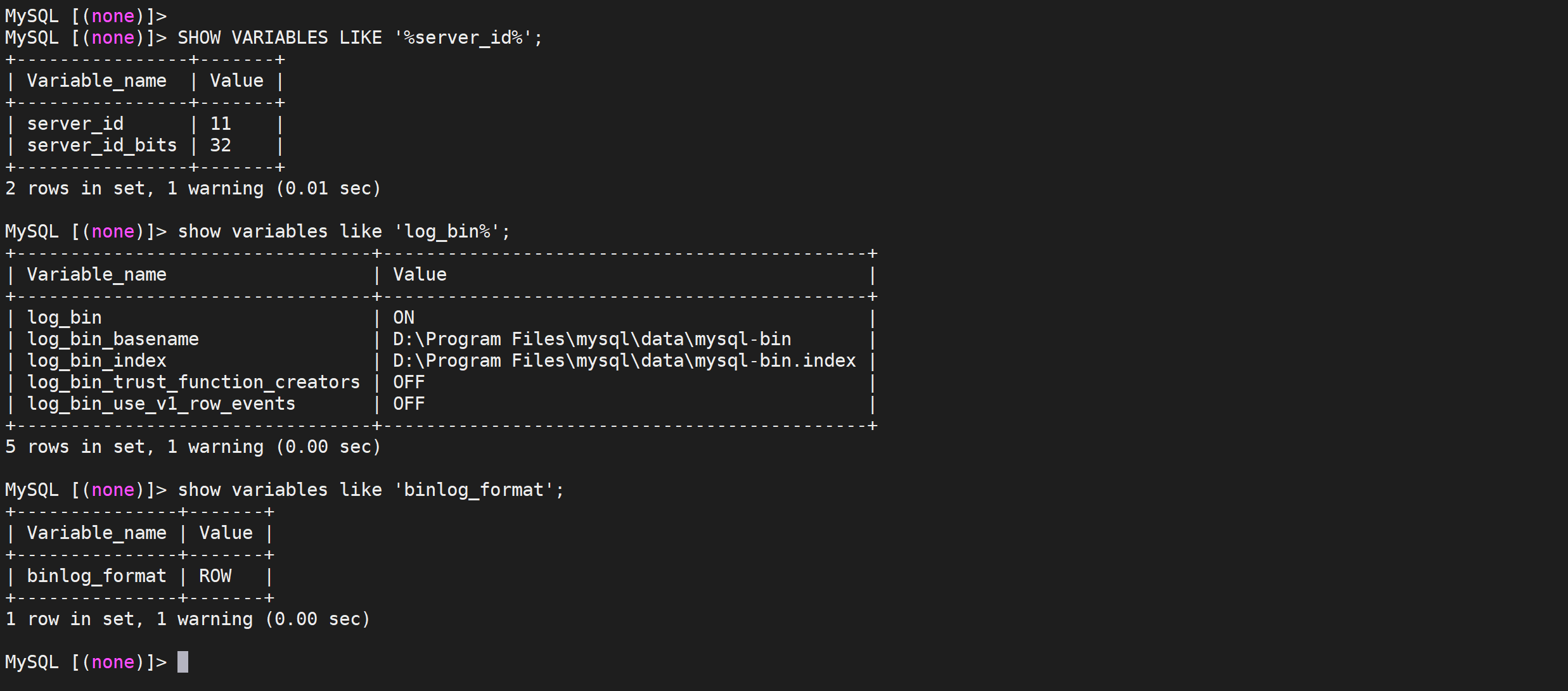
SHOW VARIABLES LIKE '%server_id%';
show variables like 'log_bin%';
show variables like 'binlog_format';
2
3
# 2.4.5 加密数据库密码
在 DM 相关配置文件中,推荐使用经 dmctl 加密后的密码,对于同一个原始密码,每次加密后密码不同。
[root@linux30 tidb]# tiup dmctl -encrypt 'tidb'

加密后的密码是:
l5nO6geu58/BjrOOZpAtAkAjsn/q
# 2.4.6 检查集群信息
使用 TiUP 部署 DM 集群后,相关配置信息如下:
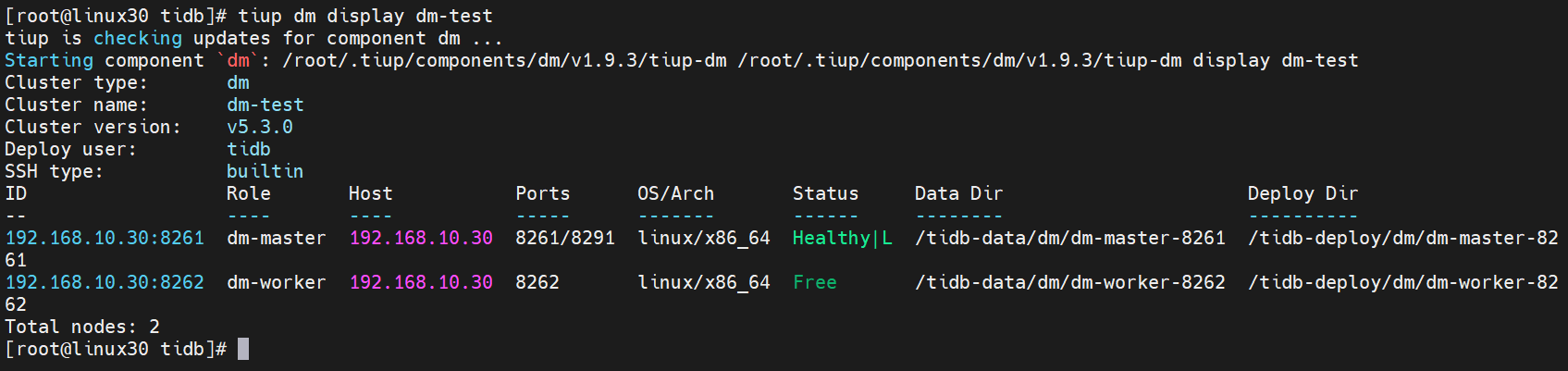
- DM 集群相关组件配置信息
| 组件 | 主机 | 端口 |
|---|---|---|
| dm_worker | 192.168.10.30 | 8262 |
| dm_master | 192.168.10.30 | 8261 |
- 上下游数据库实例相关信息
| 数据库实例 | 主机 | 端口 | 用户名 | 加密密码 |
|---|---|---|---|---|
| 上游 MySQL | 192.168.10.30 | 3306 | tidb | l5nO6geu58/BjrOOZpAtAkAjsn/q |
| 下游 TiDB | 192.168.10.30 | 4000 | root |
# 2.4.7 创建数据源
将 MySQL 的相关信息写入到
mysql.yaml中
[root@linux30 tidb]# vi mysql.yaml
# MySQL1 Configuration.
source-id: "mysql-replica"
# DM-worker 是否使用全局事务标识符 (GTID) 拉取 binlog。使用前提是在上游 MySQL 已开启 GTID 模式。
enable-gtid: false
from:
host: "192.168.10.30"
user: "tidb"
password: "l5nO6geu58/BjrOOZpAtAkAjsn/q"
port: 3306
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2.4.8 MySql数据源加入到DM集群
在终端中执行下面的命令,使用
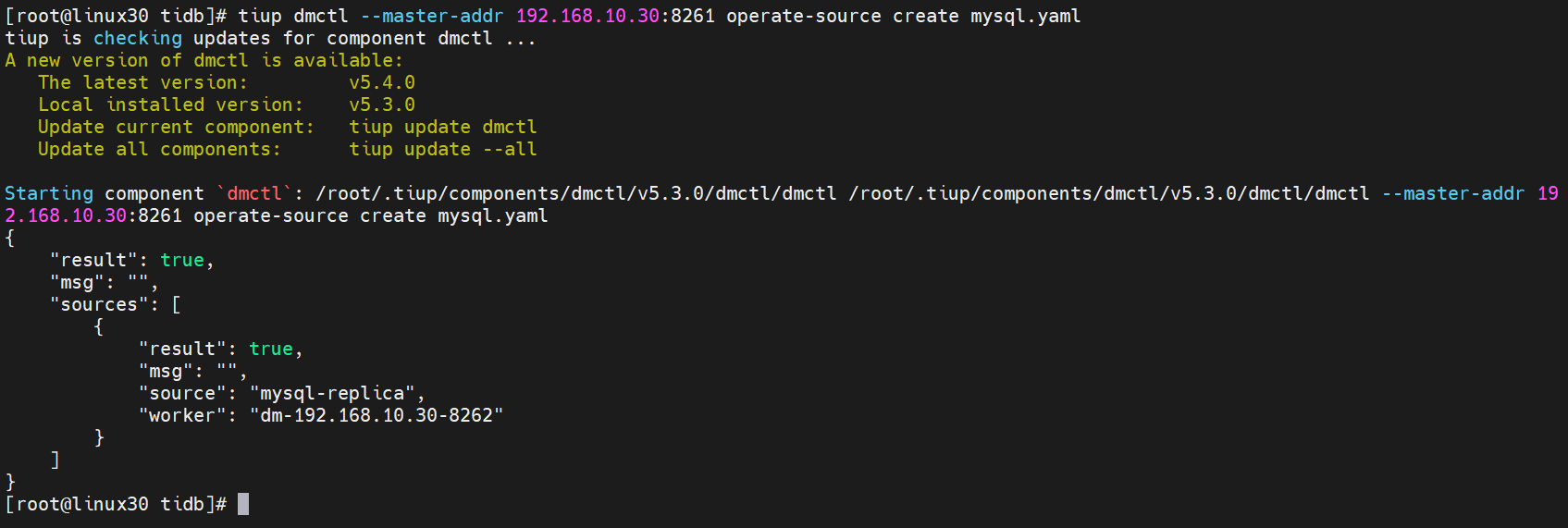
tiup dmctl将 MySQL 的数据源配置加载到 DM 集群中:
[root@linux30 tidb]# tiup dmctl --master-addr 192.168.10.30:8261 operate-source create mysql.yaml
出现如下界面返回
true表示添加到集群成功
# 2.4.9 配置任务
假设需要将 MySQL实例的
employees库的 所有 表以全量+增量的模式迁移到下游 TiDB 的employees库 编辑任务配置文件sync_task.yaml
[root@linux30 tidb]# vi sync_task.yaml
# 任务名,多个同时运行的任务不能重名。
name: "tidb_sync"
# 全量+增量 (all) 迁移模式。
task-mode: "all"
# 下游 TiDB 配置信息。
target-database:
host: "192.168.10.30"
port: 4000
user: "root"
password: ""
# 黑白名单全局配置,各实例通过配置项名引用。
#block-allow-list: # 如果 DM 版本 <= v2.0.0-beta.2 则使用 black-white-list。
# global:
# do-tables: # 需要迁移的上游表的白名单。
# - db-name: "test_db" # 需要迁移的表的库名。
# tbl-name: "test_table" # 需要迁移的表的名称。
block-allow-list:
ba-rule1:
do-dbs: ["employees"]
# 当前数据迁移任务需要的全部上游 MySQL 实例配置。
mysql-instances:
# 上游实例或者复制组 ID,参考 `inventory.ini` 的 `source_id` 或者 `dm-master.toml` 的 `source-id 配置`。
- source-id: "mysql-replica"
# 需要迁移的库名或表名的黑白名单的配置项名称,用于引用全局的黑白名单配置,全局配置见下面的 `block-allow-list` 的配置。
block-allow-list: "ba-rule1"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 2.4.10 MySQL 实例配置前置检查
为了提前发现数据迁移任务的一些配置错误,DM 中增加了前置检查功能:
- 启动数据迁移任务时,DM 自动检查相应的权限和配置。
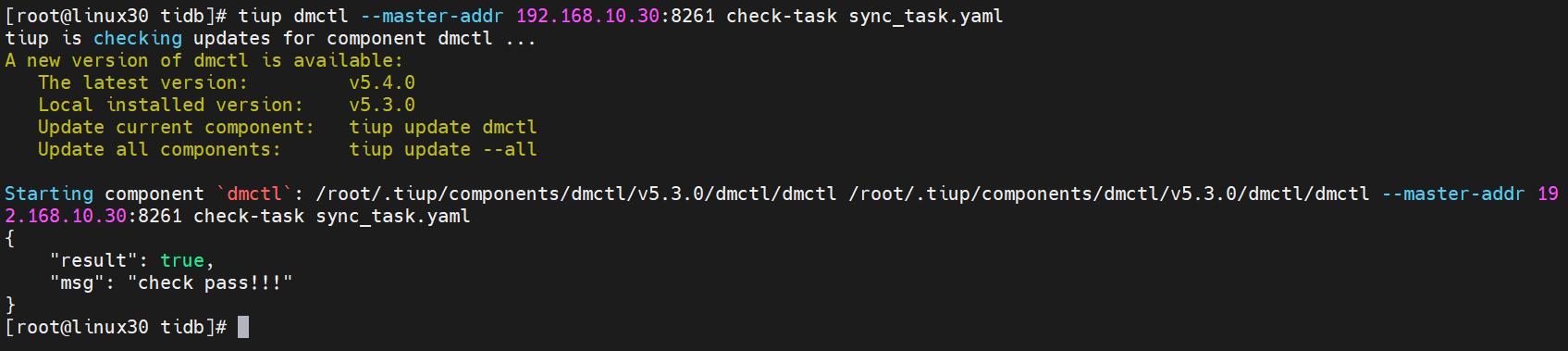
check-task命令用于对上游 MySQL 实例配置是否满足 DM 要求进行前置检查。
[root@linux30 tidb]# tiup dmctl --master-addr 192.168.10.30:8261 check-task sync_task.yaml
如果出现返回结果是true表示检查成功
# 2.4.11 开启任务
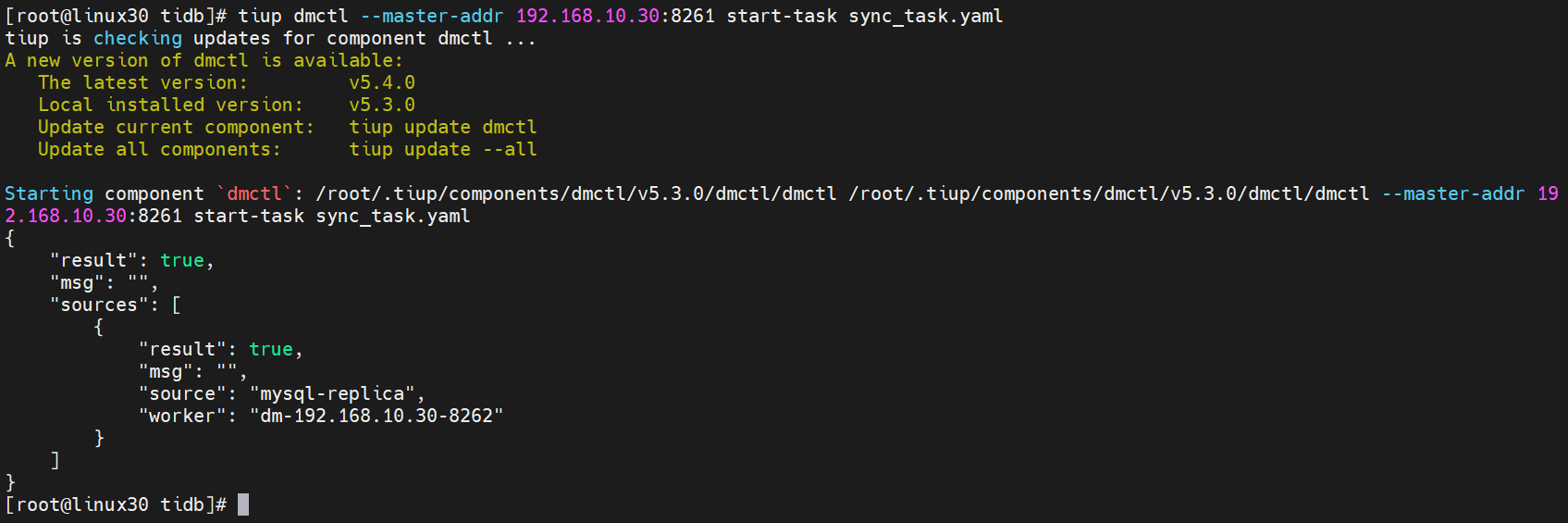
使用
tiup dmctl执行以下命令启动数据迁移任务。其中,sync_task.yaml是之前编辑的配置文件。
[root@linux30 tidb]# tiup dmctl --master-addr 192.168.10.30:8261 start-task sync_task.yaml
返回结果为true表示启动成功
# 2.4.12 查询任务
如需了解 DM 集群中是否存在正在运行的迁移任务及任务状态等信息,可使用
tiup dmctl执行以下命令进行查询:
[root@linux30 tidb]# tiup dmctl --master-addr 192.168.10.30:8261 query-status
query-status命令的查询结果、任务状态与子任务状态

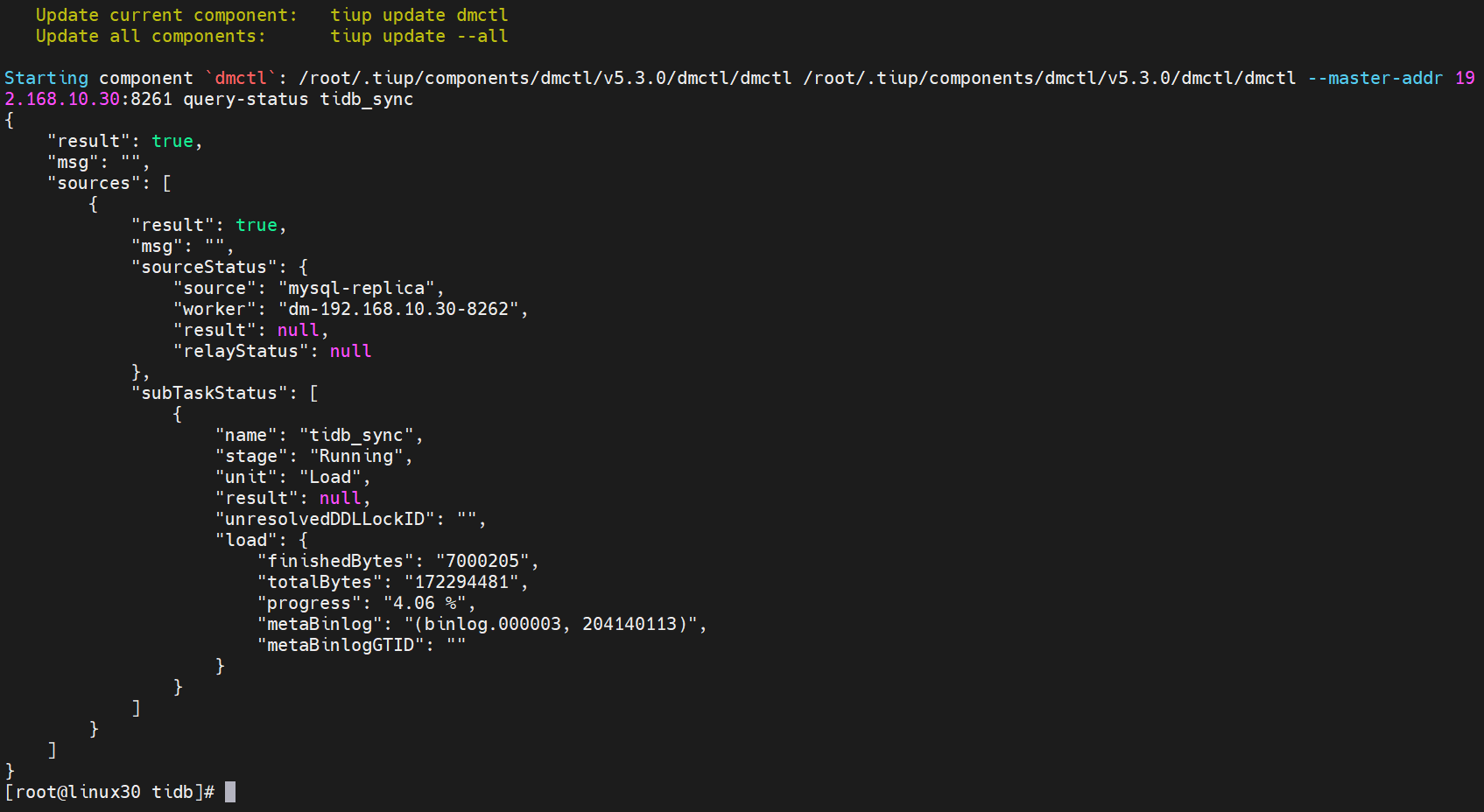
# 2.4.13 查询迁移详情
[root@linux30 tidb]# tiup dmctl --master-addr 192.168.10.30:8261 query-status tidb_sync
任务详情如下
同步文本详情如下
{
"result": true, # 查询是否成功
"msg": "", # 查询失败原因描述
"sources": [ # 上游 MySQL 列表
{
"result": true,
"msg": "",
"sourceStatus": { # 上游 MySQL 的信息
"source": "mysql-replica",
"worker": "dm-192.168.64.152-8262",
"result": null,
"relayStatus": null
},
"subTaskStatus": [ # 上游 MySQL 所有子任务的信息
{
"name": "tidb_sync", # 子任务名称
"stage": "Running", # 子任务运行状态,包括 “New”,“Running”,“Paused”,“Stopped” 以及 “Finished”
"unit": "Sync", # DM 的处理单元,包括 “Check”,“Dump“,“Load” 以及 “Sync”
"result": null, # 子任务失败时显示错误信息
"unresolvedDDLLockID": "", # sharding DDL lock ID,可用于异常情况下手动处理 sharding DDL lock
"sync": { # 当前 `Sync` 处理单元的迁移信息
"totalEvents": "0", # 该子任务中迁移的 binlog event 总数
"totalTps": "0", # 该子任务中每秒迁移的 binlog event 数量
"recentTps": "0", # 该子任务中最后一秒迁移的 binlog event 数量
"masterBinlog": "(mysql-bin.000001, 154)", # 上游数据库当前的 binlog position
"masterBinlogGtid": "", # 上游数据库当前的 GTID 信息
"syncerBinlog": "(mysql-bin.000001, 154)", # 已被 `Sync` 处理单元迁移的 binlog position
"syncerBinlogGtid": "", # 使用 GTID 迁移的 binlog position
"blockingDDLs": [ # 当前被阻塞的 DDL 列表。该项仅在当前 DM-worker 所有上游表都处于 “synced“ 状态时才有数值,此时该列表包含的是待执行或待跳过的 sharding DDL 语句
],
"unresolvedGroups": [ # 没有被解决的 sharding group 信息
],
"synced": true, # 增量复制是否已追上上游。由于后台 `Sync` 单元并不会实时刷新保存点,当前值为 “false“ 并不一定代表发生了迁移延迟
"binlogType": "remote"
}
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 2.5 检查全量同步
# 2.5.1 登录TIDB
登录TiDB 查看数据库是否同步
[root@linux30 tidb]# mysql -uroot -p -P 4000 -h 192.168.10.30

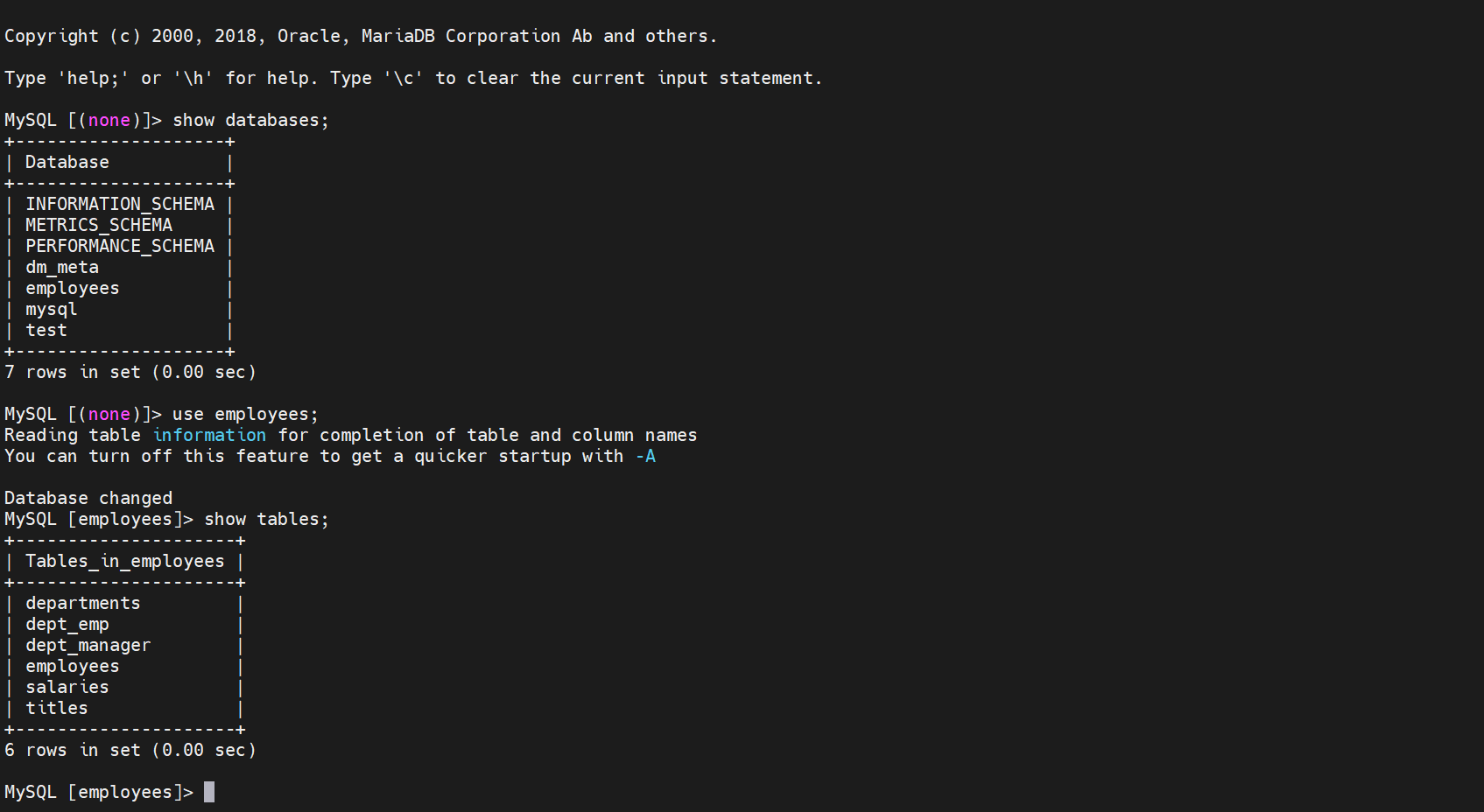
# 2.5.2 查看employees数据库
show databases;
use employees;
show tables;
2
3
我们发现数据库已经同步
# 2.6 测试增量同步
# 2.6.1 插入MySQL数据
部门表插入一条数据
mysql> INSERT INTO employees.`departments`(dept_no,dept_name)VALUES('d010','test dept');
Query OK, 1 row affected (0.01 sec)
2
# 2.6.2 更新MySQL数据
将
dept_emp中的d001改为d010
UPDATE employees.dept_emp SET dept_no='d010' WHERE dept_no='d001';
共 20211 行受到影响

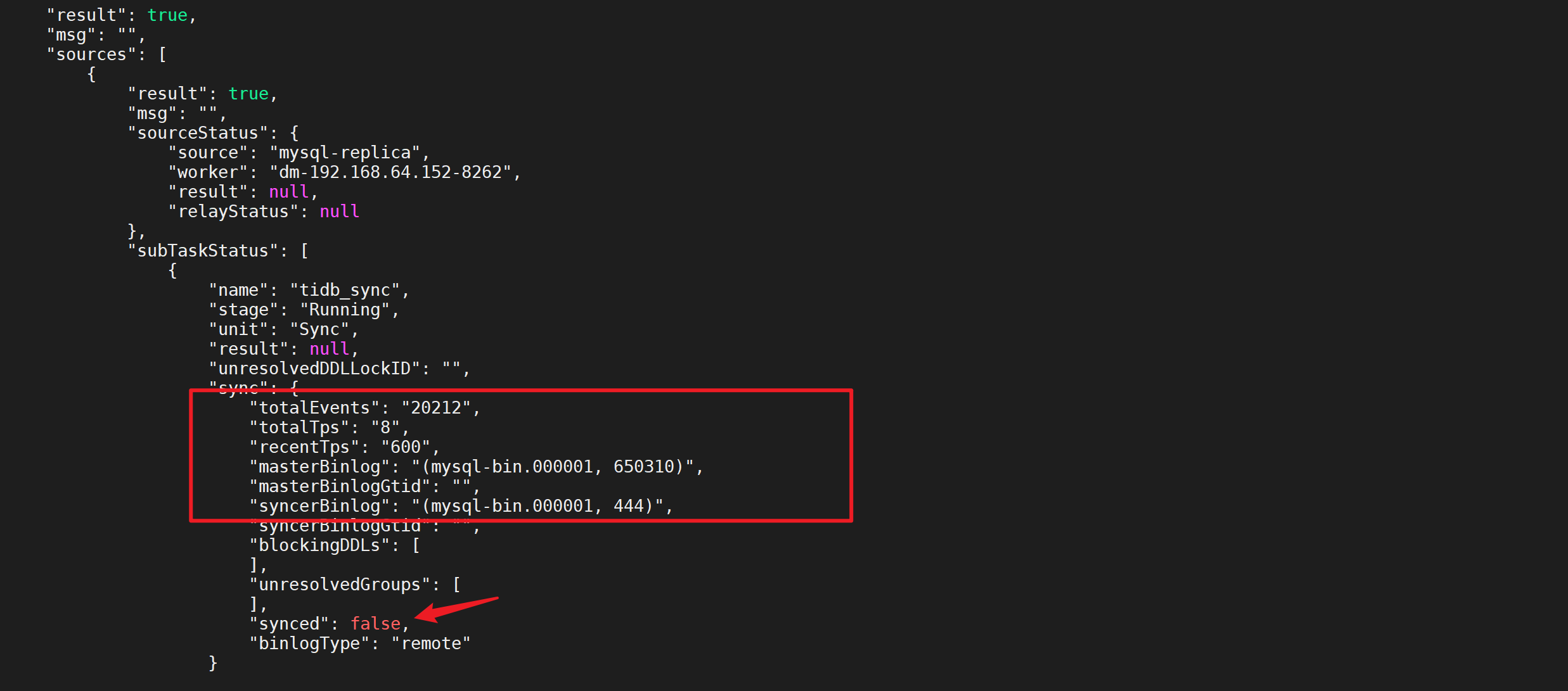
# 2.6.3 查看DM的任务状态
[root@linux30 tidb]# tiup dmctl --master-addr 192.168.10.30:8261 query-status tidb_sync
“synced”: false正在同步
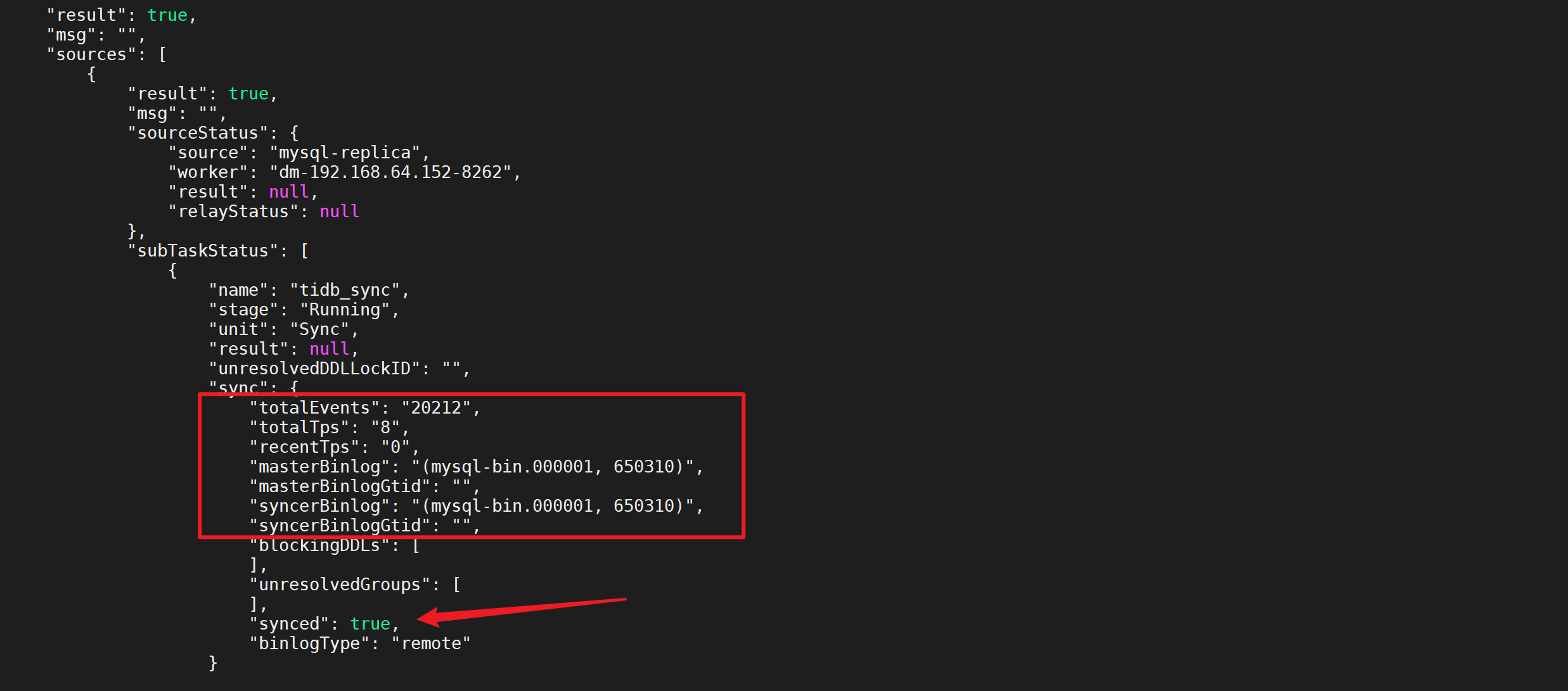
稍等后在进行查看任务状态,发现已经同步完成
# 2.6.4 检查增量同步数据
登录MySQL后检查MySQL中的数据是否同步到TiDB
[root@linux30 tidb]# mysql -uroot -p -P 4000 -h 192.168.10.30
MySQL [employees]> use employees;
MySQL [employees]> SELECT COUNT(1) FROM dept_emp WHERE dept_no='d010';
+----------+
| COUNT(1) |
+----------+
| 20211 |
+----------+
1 row in set (0.01 sec)
2
3
4
5
6
7
8
9
我们发现
d010的更新数据都已经同步过来了
# 5.7 DM的其他操作
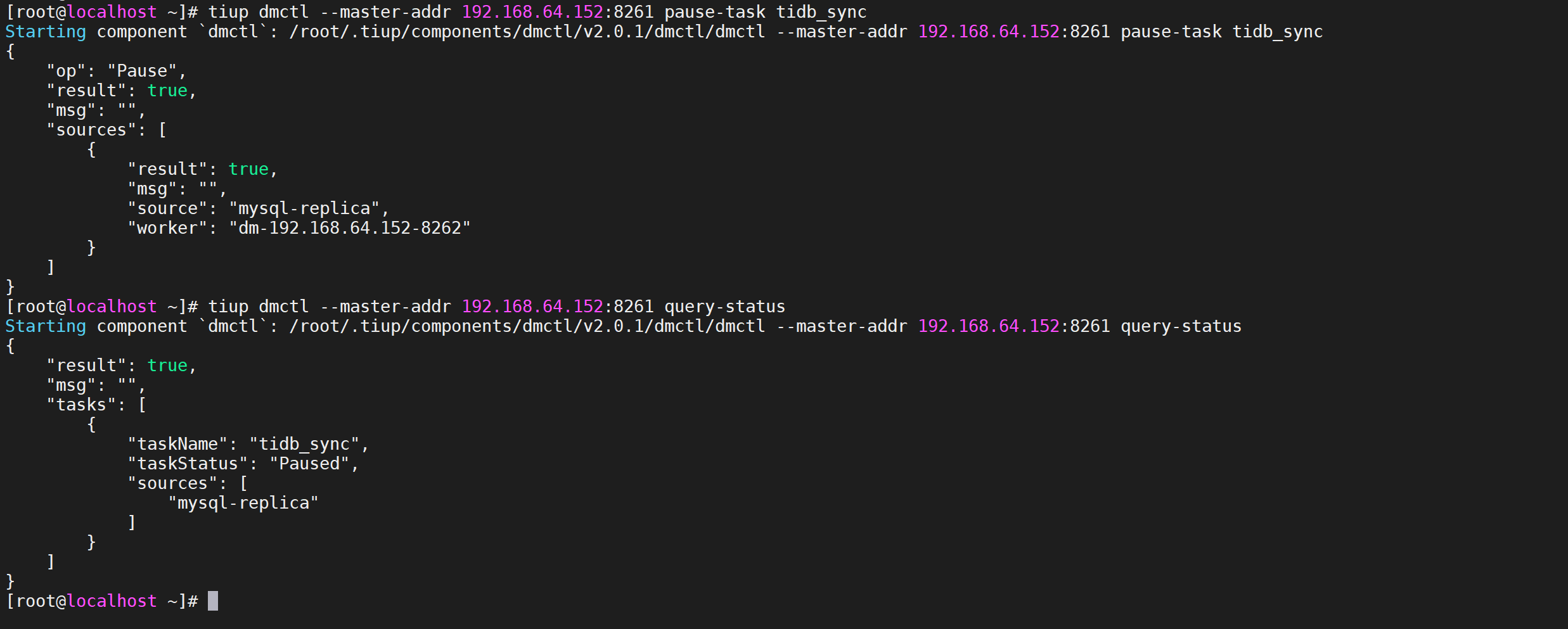
# 2.7.1 暂停数据迁移任务
pause-task命令用于暂停数据迁移任务。有关
pause-task与stop-task的区别如下
- 使用
pause-task仅暂停迁移任务的执行,但仍然会在内存中保留任务的状态信息等,且可通过query-status进行查询;使用stop-task会停止迁移任务的执行,并移除内存中与该任务相关的信息,且不可再通过query-status进行查询,但不会移除已经写入到下游数据库中的数据以及其中的 checkpoint 等dm_meta信息。 - 使用
pause-task暂停迁移任务期间,由于任务本身仍然存在,因此不能再启动同名的新任务,且会阻止对该任务所需 relay log 的清理;使用stop-task停止任务后,由于任务不再存在,因此可以再启动同名的新任务,且不会阻止对 relay log 的清理。 pause-task一般用于临时暂停迁移任务以排查问题等;stop-task一般用于永久删除迁移任务或通过与start-task配合以更新配置信息。
tiup dmctl --master-addr 192.168.64.152:8261 pause-task tidb_sync
# 2.7.2 恢复数据迁移任务
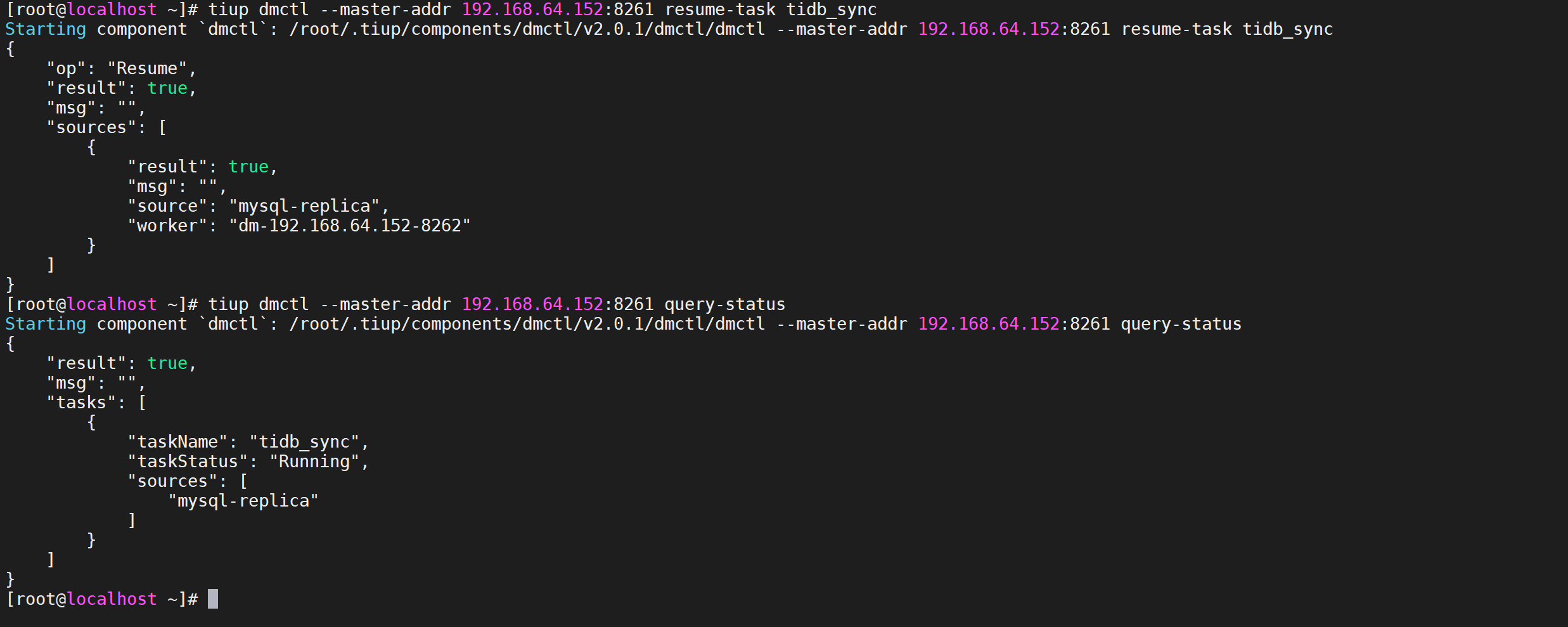
resume-task命令用于恢复处于Paused状态的数据迁移任务,通常用于在人为处理完造成迁移任务暂停的故障后手动恢复迁移任务。
tiup dmctl --master-addr 192.168.64.152:8261 resume-task tidb_sync
# 2.7.3 停止数据迁移任务
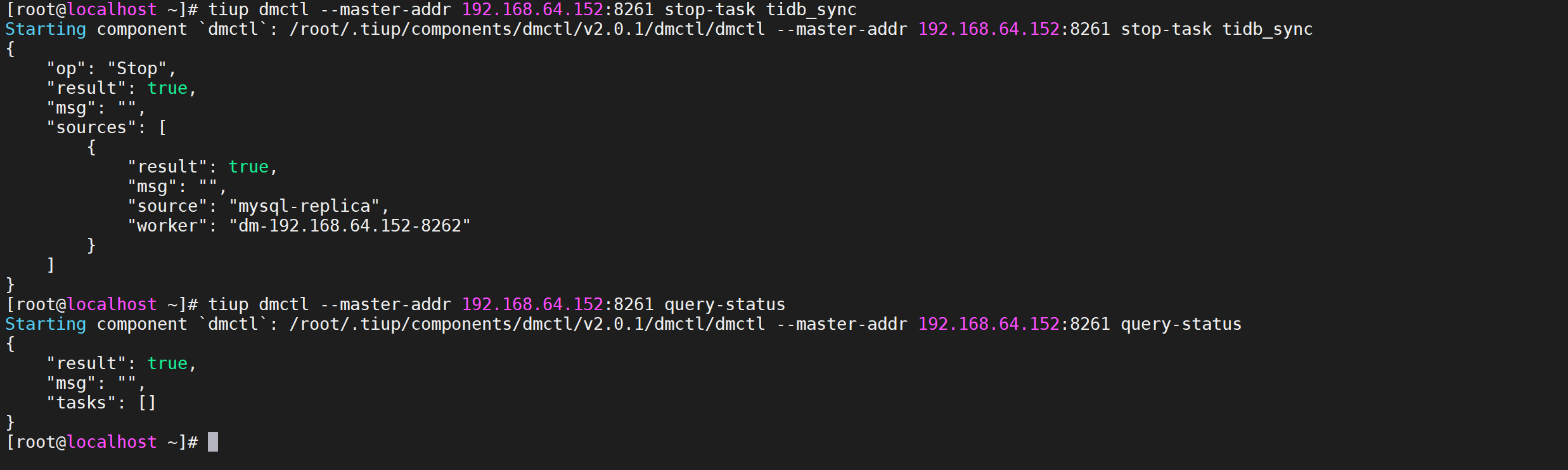
stop-task命令用于停止数据迁移任务
tiup dmctl --master-addr 192.168.64.152:8261 stop-task tidb_sync
# 3 全量数据迁移
# 3.1 下载安装TiDB工具包
安装包位置在
https://download.pingcap.org/tidb-toolkit-{version}-linux-amd64.tar.gz
- {version}:为 Dumpling 的版本号,可以通过 Dumpling Release (opens new window) 查看当前已发布版本
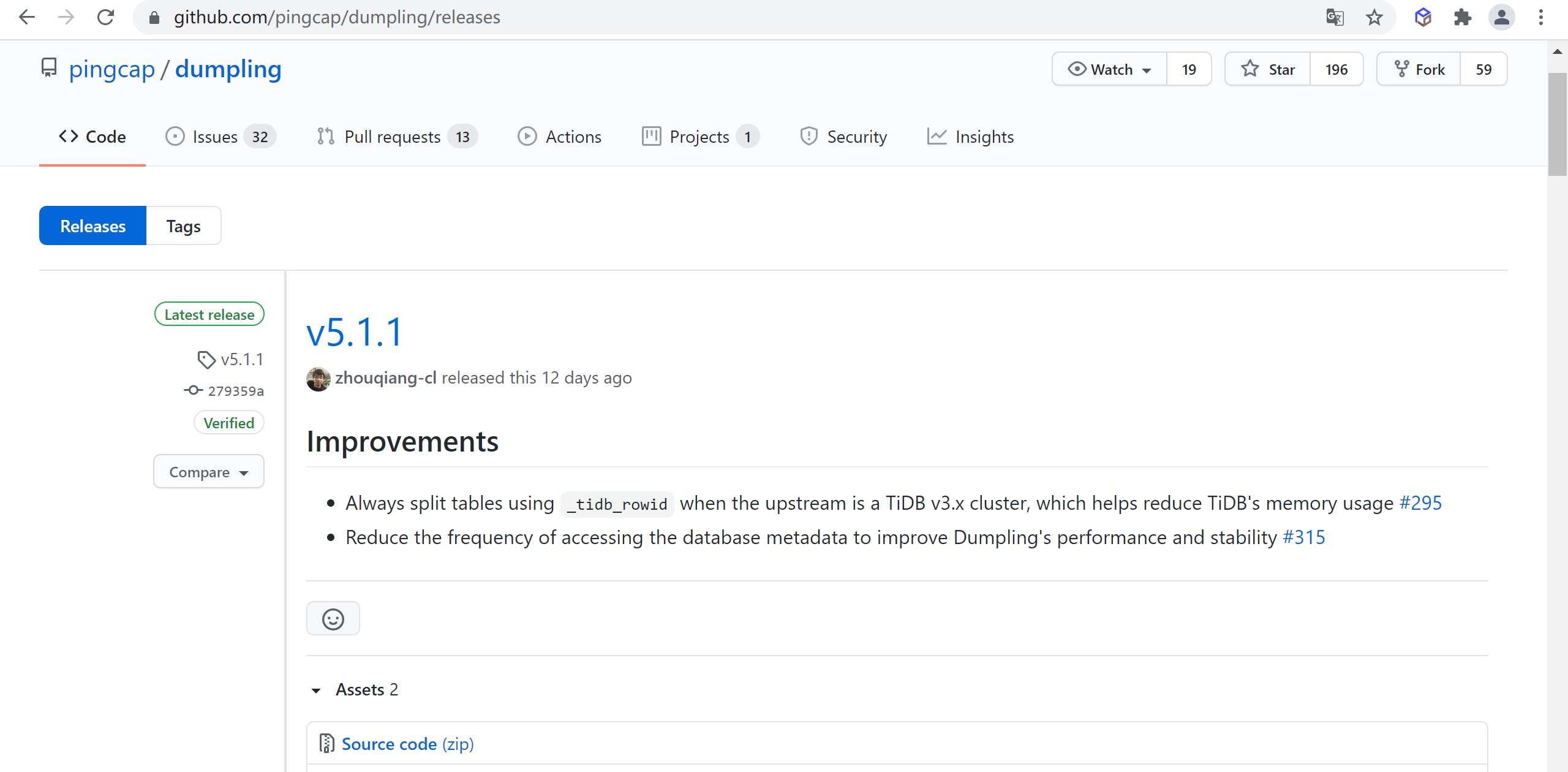
# 3.1.1 检查最新版本
通过 Dumpling Release (opens new window) 查看当前已发布版本,检查发现Dumpling当前版本是
4.0.11
# 3.1.2 下载tidb-toolkit
# 下载工具包
wget https://download.pingcap.org/tidb-toolkit-v5.0.6-linux-amd64.tar.gz
# 解压文件
tar -zxvf tidb-toolkit-v5.0.6-linux-amd64.tar.gz
2
3
4
# 3.2 Dumpling导出数据
# 3.2.1 Dumpling工具简介
Dumpling是使用 go 开发的数据备份工具,项目地址可以参考Dumpling(opens new window)。Dumpling命令参数列表
| 主要选项 | 用途 | 默认值 |
|---|---|---|
-V 或 --version | 输出 Dumpling 版本并直接退出 | |
-B 或 --database | 导出指定数据库 | |
-T 或 --tables-list | 导出指定数据表 | |
-f 或 --filter | 导出能匹配模式的表,语法可参考 table-filter (opens new window) | *.*(导出所有库表) |
--case-sensitive | table-filter 是否大小写敏感 | false,大小写不敏感 |
-h 或 --host | 连接的数据库主机的地址 | "127.0.0.1" |
-t 或 --threads | 备份并发线程数 | 4 |
-r 或 --rows | 将 table 划分成 row 行数据,一般针对大表操作并发生成多个文件。 | |
-L 或 --logfile | 日志输出地址,为空时会输出到控制台 | "" |
--loglevel | 日志级别 {debug,info,warn,error,dpanic,panic,fatal} | "info" |
--logfmt | 日志输出格式 {text,json} | "text" |
-d 或 --no-data | 不导出数据,适用于只导出 schema 场景 | |
--no-header | 导出 csv 格式的 table 数据,不生成 header | |
-W 或 --no-views | 不导出 view | true |
-m 或 --no-schemas | 不导出 schema,只导出数据 | |
-s 或 --statement-size | 控制 INSERT SQL 语句的大小,单位 bytes | |
-F 或 --filesize | 将 table 数据划分出来的文件大小,需指明单位(如 128B, 64KiB, 32MiB, 1.5GiB) | |
--filetype | 导出文件类型(csv/sql) | "sql" |
-o 或 --output | 导出文件路径 | "./export-${time}" |
-S 或 --sql | 根据指定的 sql 导出数据,该选项不支持并发导出 | |
--consistency | flush: dump 前用 FTWRL snapshot: 通过 TSO 来指定 dump 某个快照时间点的 TiDB 数据 lock: 对需要 dump 的所有表执行 lock tables read 命令 none: 不加锁 dump,无法保证一致性 auto: 对 MySQL 使用 --consistency flush;对 TiDB 使用 --consistency snapshot | "auto" |
--snapshot | snapshot tso,只在 consistency=snapshot 下生效 | |
--where | 对备份的数据表通过 where 条件指定范围 | |
-p 或 --password | 连接的数据库主机的密码 | |
-P 或 --port | 连接的数据库主机的端口 | 4000 |
-u 或 --user | 连接的数据库主机的用户名 | "root" |
--dump-empty-database | 导出空数据库的建库语句 | true |
--ca | 用于 TLS 连接的 certificate authority 文件的地址 | |
--cert | 用于 TLS 连接的 client certificate 文件的地址 | |
--key | 用于 TLS 连接的 client private key 文件的地址 | |
--csv-delimiter | csv 文件中字符类型变量的定界符 | '"' |
--csv-separator | csv 文件中各值的分隔符 | ',' |
--csv-null-value | csv 文件空值的表示 | "\N" |
--escape-backslash | 使用反斜杠 (\) 来转义导出文件中的特殊字符 | true |
--output-filename-template | 以 golang template (opens new window) 格式表示的数据文件名格式 支持 | '..' |
--status-addr | Dumpling 的服务地址,包含了 Prometheus 拉取 metrics 信息及 pprof 调试的地址 | ":8281" |
--tidb-mem-quota-query | 单条 dumpling 命令导出 SQL 语句的内存限制,单位为 byte。对于 v4.0.10 或以上版本,若不设置该参数,默认使用 TiDB 中的 mem-quota-query 配置项值作为内存限制值。对于 v4.0.10 以下版本,该参数值默认为 32 GB | 34359738368 |
--params | 为需导出的数据库连接指定 session 变量,可接受的格式: "character_set_client=latin1,character_set_connection=latin1" |
# 3.2.2 导出需要的权限
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
# 3.2.3 创建用户并授权
#创建tidb用户密码是 tidb并授权外部所以IP可以访问
CREATE USER 'tidb'@'%' IDENTIFIED BY 'tidb';
# 授权SELECT,RELOAD,LOCK TABLES,REPLICATION CLIENT 权限给tidb用户
GRANT SELECT,RELOAD,LOCK TABLES,REPLICATION CLIENT ON *.* TO 'tidb'@'%';
# 刷新数据库
FLUSH PRIVILEGES;
2
3
4
5
6
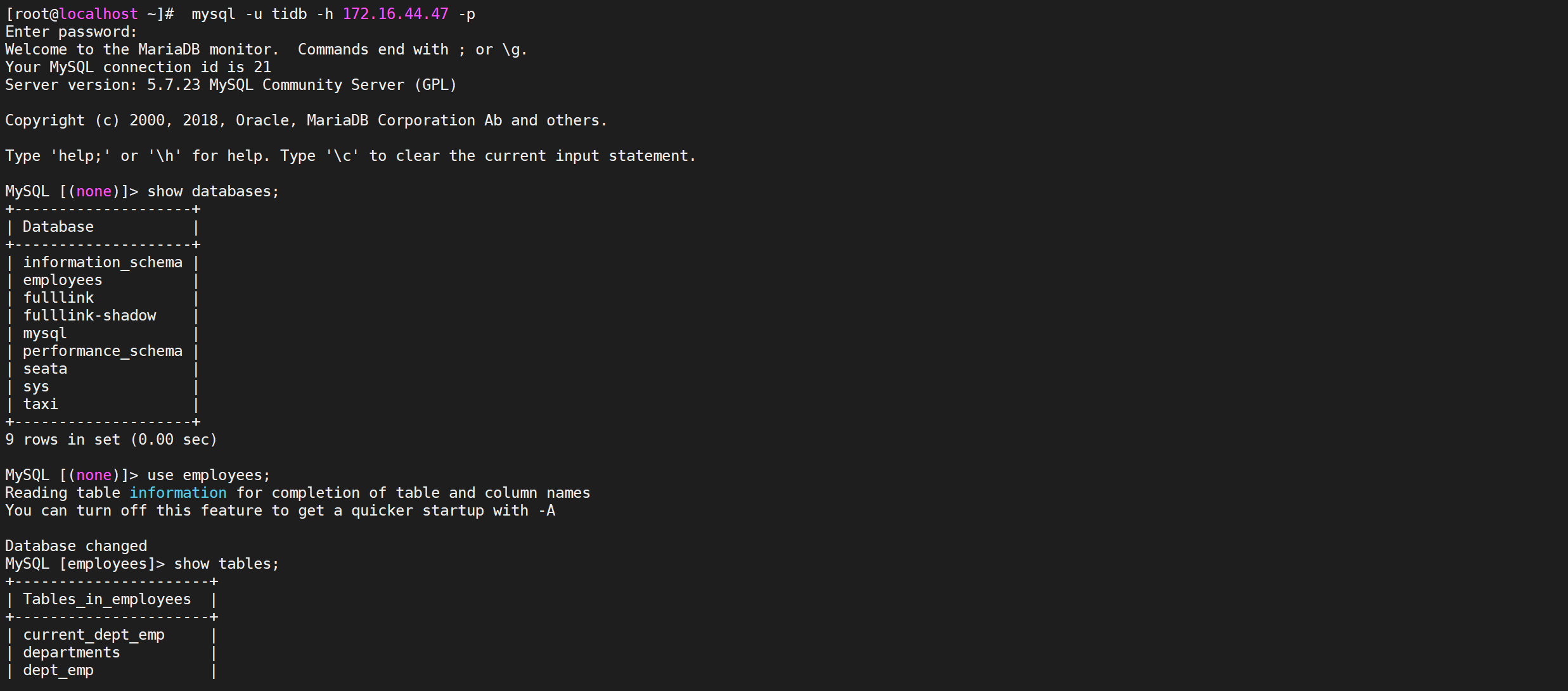
# 3.2.4 验证数据库
mysql -u tidb -h 172.16.44.47 -p
show databases;
show tables;
2
3
# 3.2.5 导出sql文件
Dumpling 默认导出数据格式为 sql 文件。也可以通过设置
--filetype sql导出数据到 sql 文件:
./bin/dumpling -h 172.16.44.47 -P 3306 -B employees -u tidb -p tidb --filetype sql --threads 10 -o /tmp/test -F 256MiB
执行命令后从mysql中导出了文件

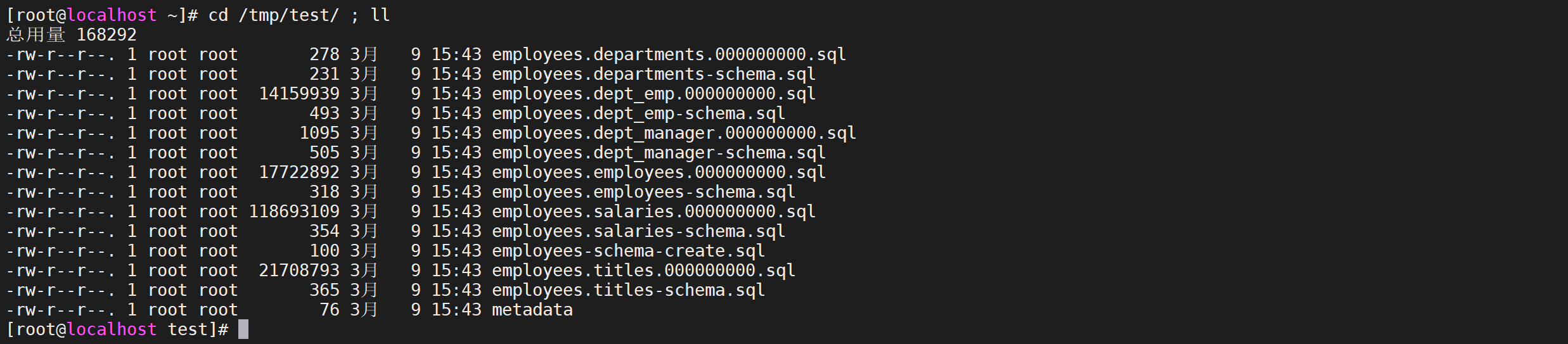
# 3.2.6 查看导出文件
cd /tmp/test/ ; ll
# 3.3 TiDB Lightning导入数据
# 3.3.1 TiDB Lightning简介
TiDB Lightning 是一个将全量数据高速导入到 TiDB 集群的工具。
TiDB Lightning 有以下两个主要的使用场景:一是大量新数据的快速导入;二是全量备份数据的恢复。目前,Lightning 支持 Dumpling 或 CSV 输出格式的数据源。你可以在以下两种场景下使用 Lightning:
- 迅速导入大量新数据。
- 恢复所有备份数据。
# 3.3.2 TiDB Lightning 整体架构
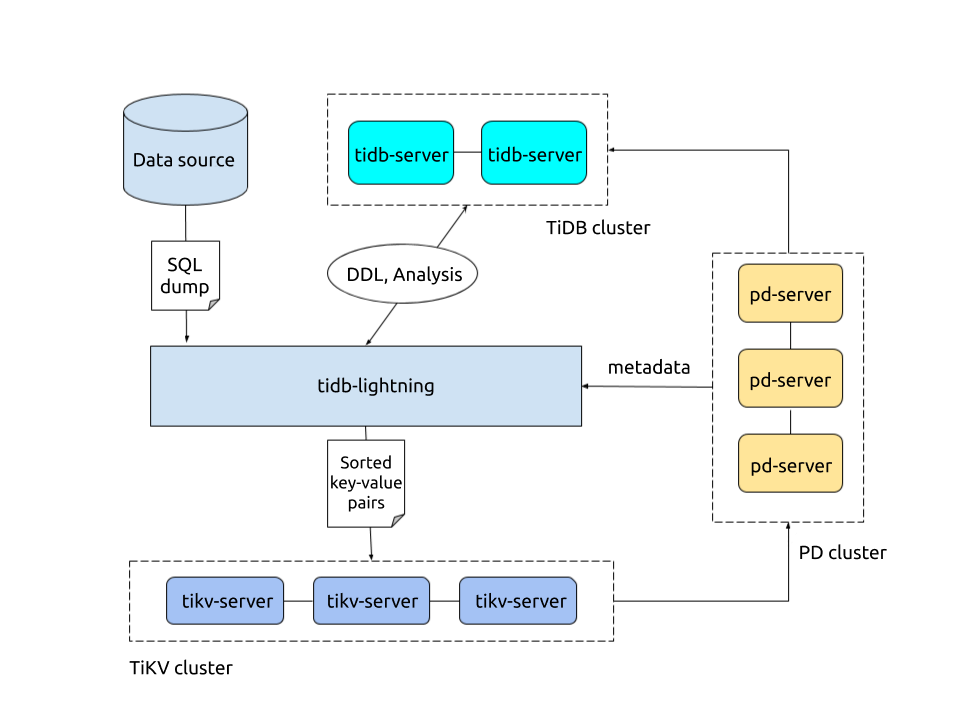
# 3.3.3 配置tidb-lightning.toml
vi tidb-lightning.toml
[lightning]
# 日志
level = "info"
file = "tidb-lightning.log"
[tikv-importer]
# 选择使用的 local 后端
backend = "local"
# 设置排序的键值对的临时存放地址,目标路径需要是一个空目录
"sorted-kv-dir" = "/tmp/sorted-kv-dir"
[mydumper]
# 源数据目录。
data-source-dir = "/tmp/test/"
[tidb]
# 目标集群的信息
host = "192.168.64.152"
port = 4000
user = "root"
password = ""
# 表架构信息在从 TiDB 的“状态端口”获取。
status-port = 10080
# 集群 pd 的地址
pd-addr = "192.168.64.152:2379"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 3.3.4 执行导入命令
./bin/tidb-lightning -config tidb-lightning.toml
出现错误不需要理会,等待导入完成
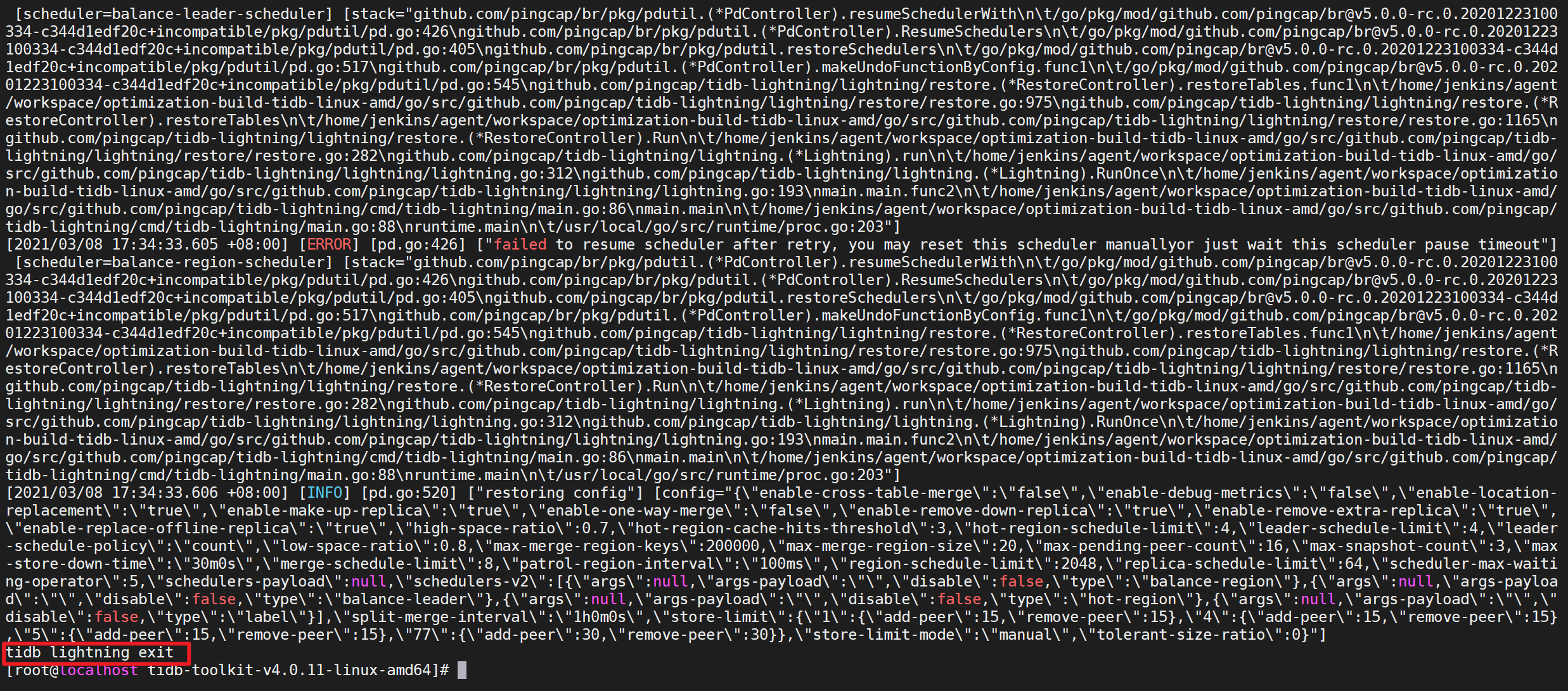
导入完毕后,TiDB Lightning 会自动退出。若导入成功,日志的最后一行会显示
tidb lightning exit。
# 3.3.5 检查是否导入成功
登录TiDB检查导入是否成功
mysql -u root -P 4000 -h 192.168.64.152
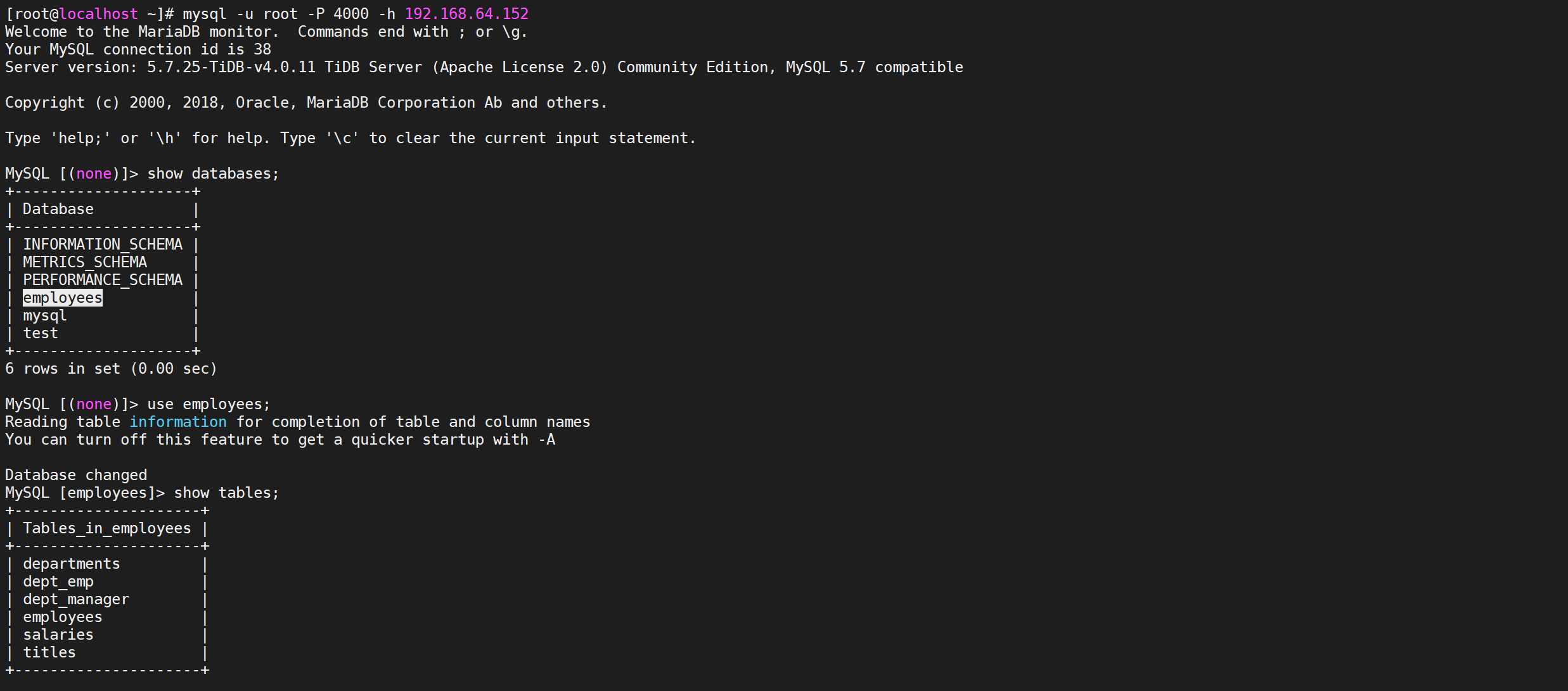
到这里基本上已经确定导入成功
