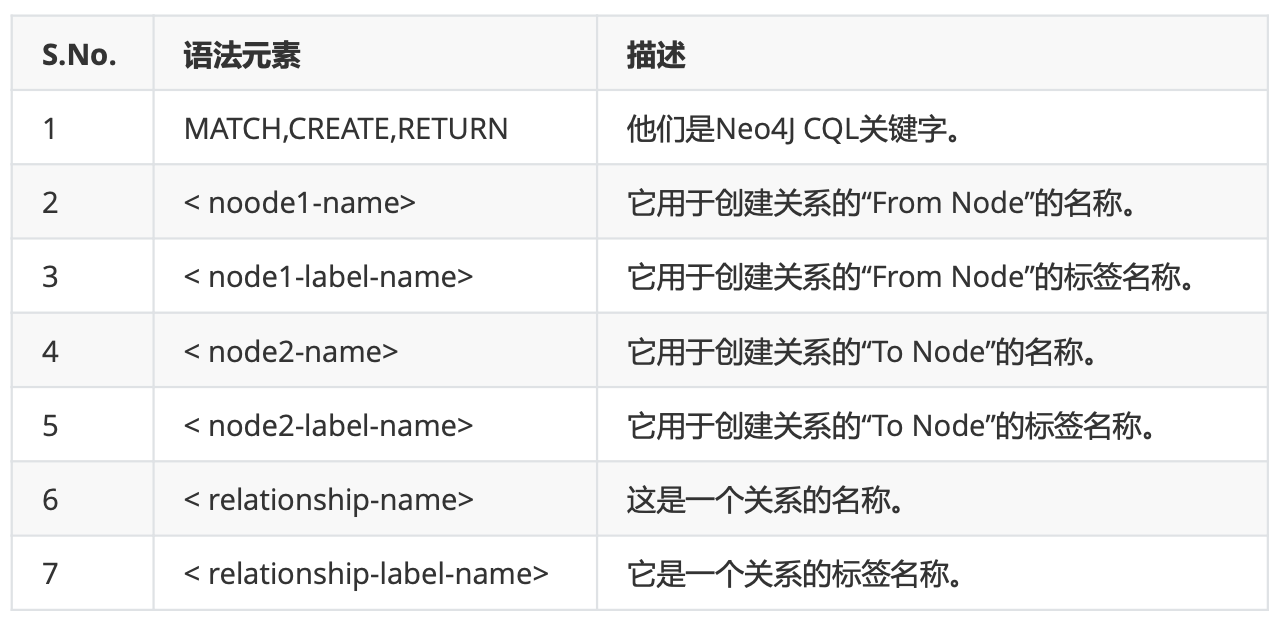
 2 Neo4j CQL
2 Neo4j CQL
# 1 CQL简介
CQL代表Cypher查询语言。 像关系型数据库具有查询语言SQL,Neo4j使用CQL作为查询语言。
Neo4j CQL
它是Neo4j图形数据库的查询语言。
它是一种声明性模式匹配语言。
它遵循SQL语法。
它的语法是非常简单且人性化、可读的格式。
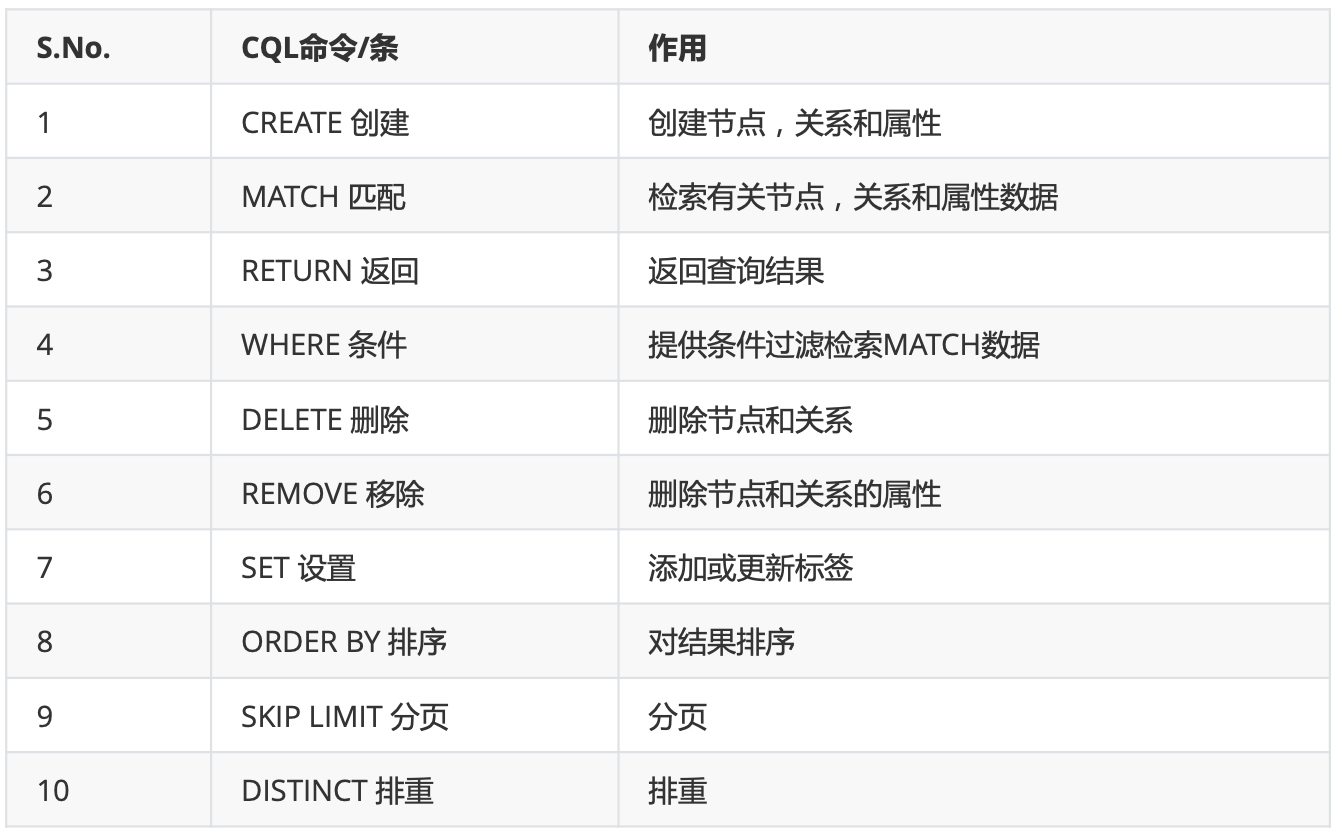
完成上面的语法 我们基于庆余年电视剧人物关系图片:
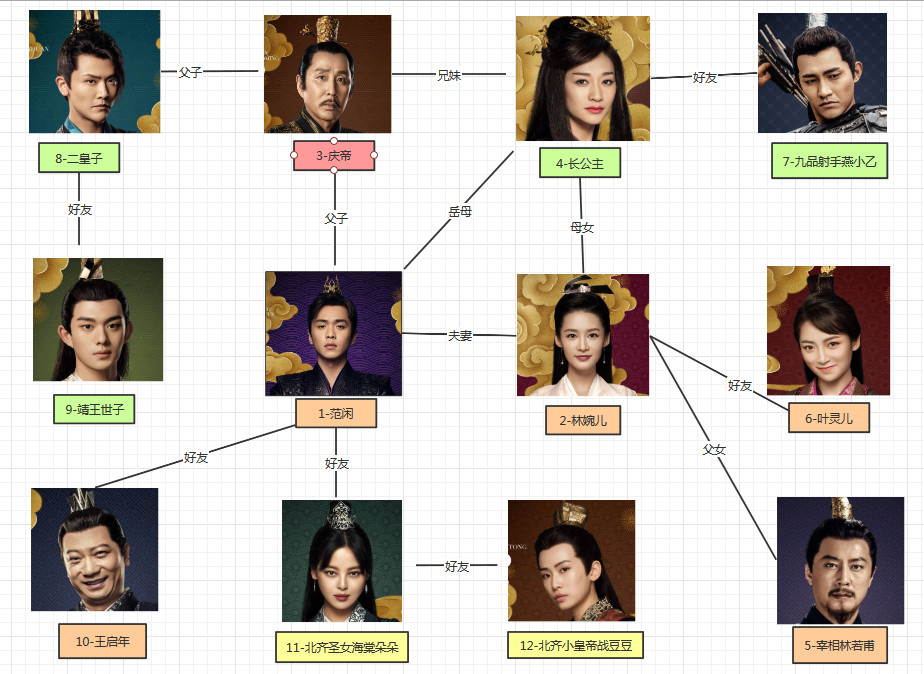
# 2 CREATE
CREATE (
<node-name>:<label-name>
[{
<property1-name>:<property1-Value>
........
<propertyn-name>:<propertyn-Value>
}]
)
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
语法说明:
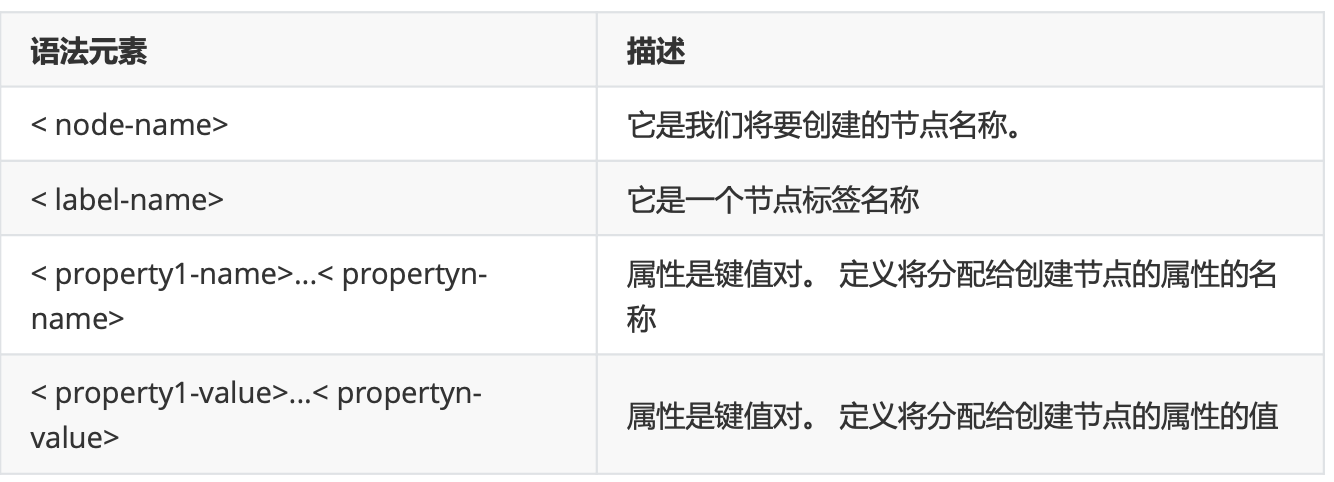
举例:
CREATE (person:Person)
1
CREATE (person:Person {cid:1,name:"范闲",age:24,gender:0,character:"A",money:1000});
CREATE (person:Person {cid:2,name:"林婉儿",age:20,gender:1,character:"B",money:800});
CREATE (person:Person {cid:3,name:"庆帝",age:49,gender:0,character:"A",money:8900});
1
2
3
4
5
2
3
4
5
# 3 MATCH RETURN命令语法
MATCH
(
<node-name>:<label-name>
)
RETURN
<node-name>.<property1-name>,
...
<node-name>.<propertyn-name>
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
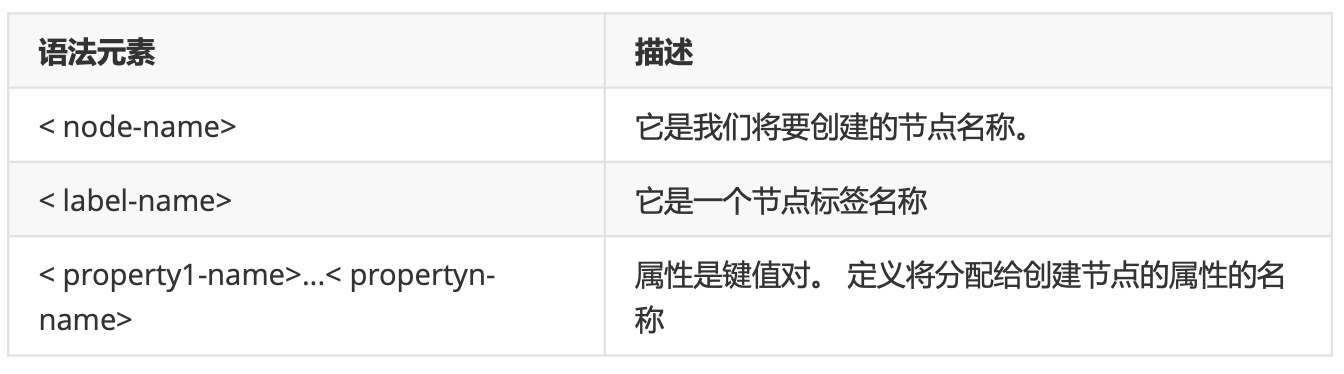
举例:
MATCH (person:Person) return person
MATCH (person:Person) return person.name,person.age
1
2
2
# 4 关系创建
- 使用现有节点创建没有属性的关系
MATCH (<node1-name>:<node1-label-name>),(<node2-name>:<node2-label-name>)
CREATE (<node1-name>)-[<relationship-name>:<relationship-label-name>]->(<node2-name>)
RETURN 相应的内容
1
2
3
2
3
语法说明:
创建关系
match(person:Person {name:"范闲"}) ,(person2:Person {name:"林婉儿"})
create(person)-[r:Couple]->(person2);
查询关系
match p = (person:Person {name:"范闲"})-[r:Couple]->(person2:Person) return p
match (p1:Person {name:"范闲"})-[r:Couple]-(p2:Person) return p1,p2
match (p1:Person {name:"范闲"})-[r:Couple]-(p2:Person) return r
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
- 使用现有节点创建有属性的关系
MATCH (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>)
CREATE
(<node1-label-name>)-[<relationship-label-name>:<relationship-name>
{<define-properties-list>}]->(<node2-label-name>)
RETURN <relationship-label-name>
其中<define-properties-list> 是分配给新创建关系的属性(名称 - 值对)的列表。
{
<property1-name>:<property1-value>,
<property2-name>:<property2-value>,
...
<propertyn-name>:<propertyn-value>
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
match(person:Person {name:"范闲"}),(person2:Person {name:"林婉儿"})
create(person)-[r:Couple{mary_date:"12/12/2014",price:55000}]->(person2)
return r;
1
2
3
2
3
- 使用新节点创建没有属性的关系
CREATE
(<node1-label-name>:<node1-name>)
-[<relationship-label-name>:<relationship-name>]->
(<node1-label-name>:<node1-name>)
1
2
3
4
2
3
4
create(person1:Person {cid:4,name:"长公主",age:49,gender:1,character:"A",money:5000})
-[r:Friend]->
(person2:Person {cid:7,name:"九品射手燕小乙",age:48,gender:0,character:"B",money:1000})
1
2
3
2
3
- 使用新节点创建有属性的关系
CREATE
(<node1-label-name>:<node1-name>{<define-properties-list>})
-[<relationship-label-name>:<relationship-name>{<define-properties-list>}]
->(<node1-label-name>:<node1-name>{<define-properties-list>})
1
2
3
4
2
3
4
create (person1:Person {cid:9,name:"靖王世子",age:23,gender:0,character:"A",money:3000})
<-[r:Friend {date:"11-02-2000"}]->
(person2:Person {cid:8,name:"二皇子",age:24,gender:0,character:"B",money:6000})
1
2
3
2
3
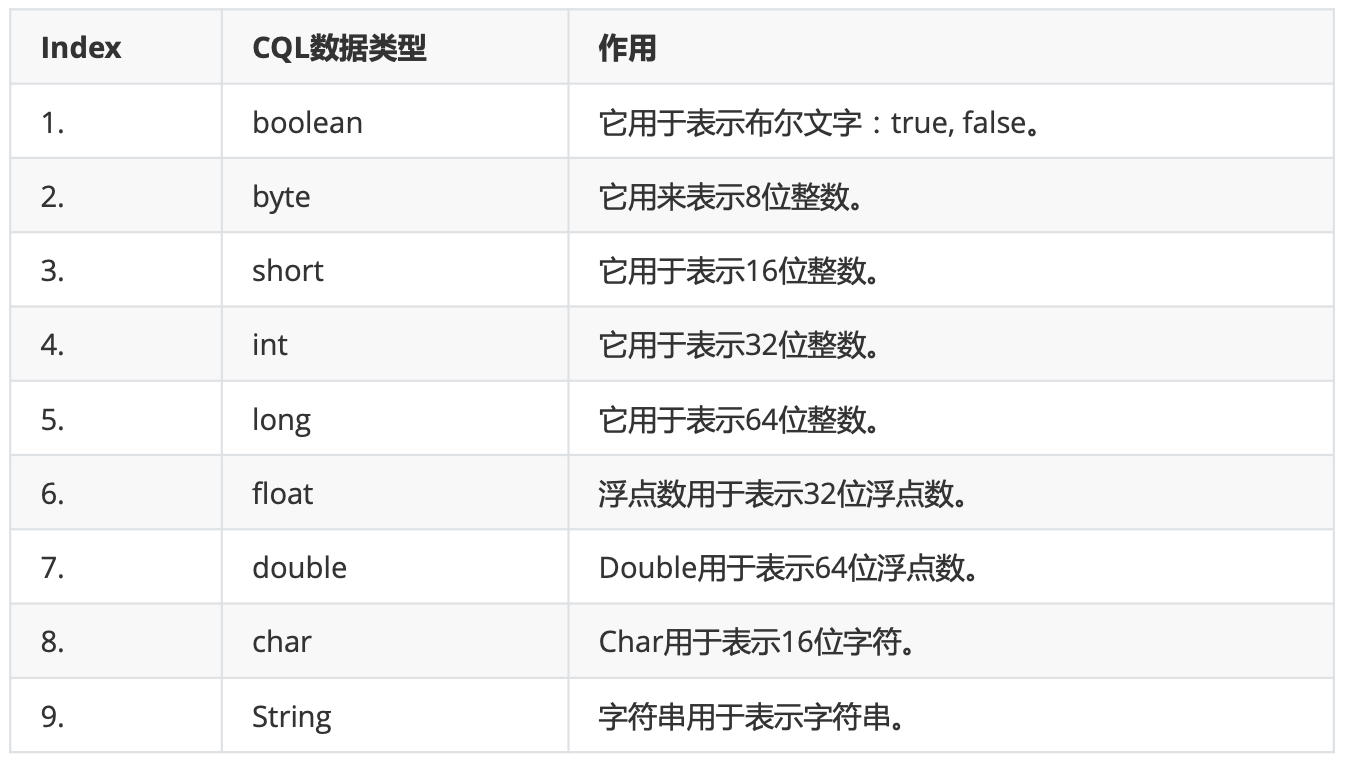
关系和节点的属性可以使用的类型
# 5 CREATE创建多个标签
CREATE (<node-name>:<label-name1>:<label-name2>.....:<label-namen>)
1
如:
CREATE (person:Person:Beauty:Picture {cid:20,name:"小美女"})
1
# 6 WHERE 子句
简单的WHERE子句
WHERE <condition>
复杂的WHERE子句
WHERE <condition> <boolean-operator> <condition>
1
2
3
4
2
3
4
where 中的比较运算符 和 之前mysql的相同 如 = != <> > < 等
MATCH (person:Person)
WHERE person.name = '范闲' OR person.name = '靖王世子'
RETURN pers
1
2
3
2
3
# 7 DELETE子句和REMOVE子句
DELETE子句
删除节点。
删除节点及相关节点和关系。
match p = (:Person {name:"林婉儿"})-[r:Couple]-(:Person) delete r
1
REMOVE子句
删除节点或关系的标签
删除节点或关系的属性
MATCH (person:Person {name:"小美女"})
REMOVE person.cid
1
2
2
# 8 SET子句
向现有节点或关系添加新属性
更新属性值
MATCH (person:Person {cid:1})
SET person.money = 3456,person.age=25
1
2
2
# 9 ORDER BY子句
“ORDER BY”子句,对MATCH查询返回的结果进行排序。
我们可以按升序或降序对行进行排序。
默认情况下,它按升序对行进行排序。 如果我们要按降序对它们进行排序,我们需要使用DESC子句。
MATCH (person:Person)
RETURN person.name,person.money
ORDER BY person.money DESC
1
2
3
2
3
# 10 SKIP 和LIMIT
Neo4j CQL已提供“SKIP”子句来过滤或限制查询返回的行数。 它修整了CQL查询结果集顶部的结果。
Neo4j CQL已提供“LIMIT”子句来过滤或限制查询返回的行数。 它修剪CQL查询结果集底部的结果。
MATCH (person:Person)
RETURN ID(person),person.name,person.money
ORDER BY person.money DESC skip 4 limit 2
1
2
3
2
3
# 11 DISTINCT排重
这个函数的用法就像SQL中的distinct关键字,返回的是所有不同值。
MATCH (p:Person) RETURN Distinct(p.character
1
上次更新: 2025/04/03, 11:07:08
