 电商实际应用
电商实际应用
# 1 常见问题
# 1.1 线程协作
先搞懂线程协作的一些基本操作,面试经常要用到!
# 1.1.1 Object中
# wait、notify
wait:让出锁,阻塞等待
notify/notifyAll:唤醒wait的进程,注意,具体唤醒哪一个要看优先级,同优先级的看运气
notifyAll优先级测试,猜一下输出?
package com.itheima.busi;
public class NotifyTest {
public static void main(String[] args) {
byte[] lock = new byte[0];
Thread t1 = new Thread(()‐>{
synchronized (lock){
try {
lock.wait();
System.out.println("t1 started");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(()‐>{
synchronized (lock){
try {
lock.wait();
System.out.println("t2 started");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t3 = new Thread(()‐>{
synchronized (lock){
try {
Thread.sleep(1000);
System.out.println("t3 notify");
lock.notifyAll();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.setPriority(1);
t2.setPriority(3);
t3.setPriority(2);
t1.start();
t2.start();
t3.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
结果分析:wait让出锁,t3得到执行,t3唤醒后,虽然t1先start,但是优先级低,所以t2优先执行
t3
t1
t2
也有可能
t3
t2
t1
2
3
4
5
6
7
# 1.1.2 Thread中
# sleep
sleep:暂停一下,只是让出CPU的执行权,并不释放锁。
猜一下结果……
package com.itheima;
public class SleepTest{
public static void main(String[] args) {
final byte[] lock = new byte[0];
new Thread(()‐>{
synchronized (lock){
System.out.println("start");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end");
}
}).start();
new Thread(()‐>{
synchronized (lock){
System.out.println("need lock");
}
}).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
结果
start
end
need lock
2
3
分析:
新的thread无法异步执行,被迫等待锁,跟着sleep
# yield
yield:不释放锁,运行中转为就绪,让出cpu给大家去竞争。当然有可能自己又抢了回来
想一下,以下代码有可能是什么结果……
yield让cpu,不让锁,所以其他线程包括自己当前的这个线程都会去竞争cpu的执行权,所以当多个线程去争cou执行权的时候,有些线程同时需要这把锁的话,锁被之前的那个线程占着,你不能执行,及时你抢到了cpu执行权。
而且其他没有用到锁的线程,就可以拥有优先执行的机会。
package com.itheima;
public class YieldTest{
public static void main(String[] args) throws InterruptedException {
final byte[] lock = new byte[0];
//让出执行权,但是锁不释放
Thread t1 = new Thread(()‐>{
synchronized (lock){
System.out.println("start");
Thread.yield();
System.out.println("end");
}
});
//可以抢t1,但是拿不到锁,白费
Thread t2 = new Thread(()‐>{
synchronized (lock){
System.out.println("need lock");
}
});
//不需要锁,可以抢t1的执行权,但是能不能抢得到,不一定
//所以多执行几次,会看到不同的结果……
Thread t3 = new Thread(()‐>{
System.out.println("t3 started");
});
t1.start();
t2.start();
t3.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
分析:
t3会插队抢到执行权,但是t2不会,因为t2和t1共用一把锁而yield不会释放
t3不见得每次都能抢到。可能t1让出又抢了回去
# join
上面那些例子都是兄弟线程并列关系,这个是父子关系。
- join:父线程等待子线程执行完成后再执行,将异步转为同步。注意调的是子线程,阻断的是父线程
一个典型的join案例,打开和关闭join看下结果:
package com.itheima;
public class JoinTest implements Runnable{
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("I am sub");
}
public static void main(String[] args) throws InterruptedException {
Thread sub = new Thread(new JoinTest());
sub.start();
// sub.join();
System.out.println("I am main");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
分析:
如果不join,main先跑完
I am main
I am sub
2
如果join,main必须等待sub之后才输出
I am sub
I am main
2
扩展:concurrent.lock中, Condition.await(),signal/signalAll 与 wait/notify效果一样
# 1.2 死锁
# 1.2.1 现象
很简单,先看一个案例。双锁互相等待。
package com.itheima;
public class DeadLock {
byte[] lock1 = new byte[0];
byte[] lock2 = new byte[0];
void f1() throws InterruptedException {
synchronized (lock1){
Thread.sleep(1000);
synchronized (lock2){
System.out.println("f1");
}
}
}
void f2() throws InterruptedException {
synchronized (lock2){
Thread.sleep(1000);
synchronized (lock1){
System.out.println("f2");
}
}
}
public static void main(String[] args) {
DeadLock deadLock = new DeadLock();
new Thread(()‐>{
try {
deadLock.f1();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(()‐>{
try {
deadLock.f2();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 1.2.2 死锁的条件
- 互斥使用,即资源只能独享,一个占了其他都必须等。
- 不可抢占,资源一旦被占,就只能等待占有者主动释放,其他线程抢不走。
- 贪婪占有,占着一把锁不释放,同时又需要申请另一把。
- 循环等待,即存在等待环路,A → B → C → A。
# 1.2.3 排查
jdk自带工具
- jps + jstack pid
通过jps找到线程号,再执行jstack pid,找到 Found one Java-level deadlock:xxx
- jconsole
执行jconsole,打开窗口,找到 线程 → 检测死锁
- jvisualvm
执行jvisualvm,打开窗口,双击线程pid,打开线程,会提示死锁,dump查看线程信息
# 1.2.4 如何避免
- 合理搭配锁顺序,如果必须获取多个锁,我们就要考虑不同线程获取锁的次序搭配
- 少用synchronized,多用Lock.tryLock方法并配置超时时间
- 对多线程保持谨慎。拿不准的场景宁可不用。线上一旦死锁往往正是高访问时间段。代价巨大
# 1.3 饥饿线程
# 1.3.1 概念
如果一个线程因为 CPU 时间全部被其他线程抢走而始终得不到 CPU 运行时间,看一个案例:
读代码,猜一猜结果?
package com.itheima;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class HungryThread{
ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
void write(){
readWriteLock.writeLock().lock();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
readWriteLock.writeLock().unlock();
}
void read(){
readWriteLock.readLock().lock();
System.out.println("read");
readWriteLock.readLock().unlock();
}
public static void main(String[] args) {
HungryThread hungryThread = new HungryThread();
Thread t1 = new Thread(()‐>{
//不停去拿写锁,拿到后sleep一段时间,释放
while (true) {
hungryThread.write();
}
});
Thread t2 = new Thread(()‐>{
//不停去拿读锁,虽然是读锁,但是...看下面!
while (true){
hungryThread.read();
}
});
t1.setPriority(9);
//优先级低!
t2.setPriority(1);
t1.start();
t2.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
结果分析:
read几乎不会出现,甚至一直都拿不到锁。处于饥饿状态
StampedLock
package com.itheima;
import java.util.concurrent.locks.StampedLock;
public class StampedThread {
StampedLock lock = new StampedLock();
void write(){
long stamp = lock.writeLock();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock(stamp);
}
void read(){
//乐观读
long stamp = lock.tryOptimisticRead();
//判断是否有写在进行,没占用的话,得到执行,打印read
if (lock.validate(stamp)){
System.out.println("read");
}
}
public static void main(String[] args) {
StampedThread stampedThread = new StampedThread();
Thread t1 = new Thread(()‐>{
while (true) {
stampedThread.write();
}
});
Thread t2 = new Thread(()‐>{
while (true){
stampedThread.read();
}
});
t1.setPriority(9);
t2.setPriority(1);
t1.start();
t2.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
结果分析:
read间隔性打出,提升了读操作的并发性
注意,StampedLock的使用有局限性!
- 对于读多写少的场景 StampedLock 性能很好,简单的应用场景基本上可以替代 ReadWriteLock
- StampedLock 在命名上并没有 Reentrant,StampedLock 是不可重入的!
- StampedLock 的悲观读锁、写锁都不支持条件变量(无法使用Condition)
案例:StampedLock是不可重入锁!
可重入锁指的获取到锁后,如果同步块内需要再次获取同一把锁的时候,直接放行,而不是等待。其意义在于防止死锁。前面使用的synchronized 和ReentrantLock 都是可重入锁。
package com.itheima.thread;
import java.util.concurrent.locks.StampedLock;
public class StampedReetrant {
public static void main(String[] args) {
StampedLock lock = new StampedLock();
long stamp1 = lock.writeLock();
System.out.println(1);
long stamp2 = lock.writeLock();
System.out.println(2);
lock.unlock(stamp2);
lock.unlock(stamp1);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 1.3.2 饥饿线程产生原因
高优先级线程吞噬所有的低优先级线程的 CPU 时间。
锁始终被别的线程抢占。
# 1.3.3 解决饥饿问题的方案
- 保证资源充足
- 避免持有锁的线程长时间执行,设置一定的退出机制
- 在高风险地方使用公平锁
# 2 解决方案
# 2.1 demo准备
# 2.1.1 boot项目
搭建springboot web项目,集成mybatis,druid连接池,rabbitmq(抢单用),swagger
mysql,rabbitmq使用docker启动,操作参考如下
docker安装说明:
https://www.runoob.com/docker/windows-docker-install.html
启动:
#mysql
#注意,D:/data/mysql是机器上要挂载的数据库存放目录
#需要在自己机器上创建这个路径
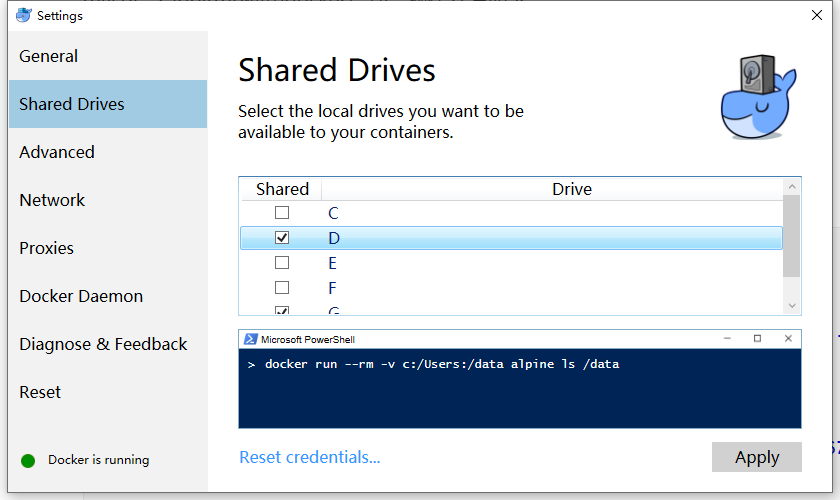
#同时要注意,windows下安装docker后,必须选中磁盘share,参考下面的截图
docker run ‐‐name mysql ‐v D:/data/mysql:/var/lib/mysql ‐p3306:3306 ‐e MYSQL_ROOT_PASSWORD=root ‐d daocloud.io/mysql:5.7.4
#rabbitmq
#这个不需要挂盘
docker run ‐d ‐‐hostname my‐rabbit ‐‐name rabbit ‐p 15672:15672 ‐p5672:5672 daoc
2
3
4
5
6
7
8
9
10
# 2)建表
- orders表,超时订单案例会用到
CREATE TABLE `orders` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL COMMENT '商品名称(demo使用,现实中为外键id)',
`createtime` datetime DEFAULT NULL COMMENT '创建时间',
`updatetime` datetime DEFAULT NULL COMMENT '更新时间',
`invalid` int(11) DEFAULT NULL COMMENT '失效时间(单位秒)',
`status` tinyint(4) DEFAULT NULL COMMENT '状态(0=新增,‐1=失效)',
PRIMARY KEY (`id`)
);
2
3
4
5
6
7
8
9
- product表,库存和排序会用到
CREATE TABLE `product` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL COMMENT '商品名称',
`num` int(11) DEFAULT '0' COMMENT '库存数',
`price` float DEFAULT '0' COMMENT '价格',
PRIMARY KEY (`id`)
);
2
3
4
5
6
7
- flashorder表,记录抢购后的单子
CREATE TABLE `flashorder` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`productid` int(11) NOT NULL COMMENT '抢到的商品id',
`userid` int(11) NOT NULL COMMENT '用户id,这里用抢购线程的id模拟',
PRIMARY KEY (`id`)
);
2
3
4
5
6
# 3)调试
启动springboot项目后,访问 http://localhost:8080/doc.html 进入swagger可以调试所有demo接口
# 2.2 超时订单
# 2.2.1 设计方案
- 定时扫表:写定时任务轮询扫订单表,挨个比对时间,超时的更新掉
- 数据量小时,一般万级以内可以。几万到上亿的数据,显然不可取。
- 当前项目多处于分库分表模式,扫描需要扫多个表甚至跨库
- 延迟消费:在下订单时,同时投放一个队列用于延迟操作,常见队列有三种
- DelayQueue,简单,不借助任何外部中间件,可借助db事务,down机丢失,同时注意内存占用
- 消息队列,设置延迟并监听死信队列,注意消息堆积产生的监控报警
- redis过期回调,redis对内存空间的占用
具体采取哪种延迟手段,根据企业实际情况,临时性的场合(比如某个抢购活动),可以采用方案一,系统化的订单取消,比如电商系统默认30分钟不支付取消规则,2号方案居多。
为加深线程相关内容,本章节采用方案一
# 2.2.2 实现
- 定义delay的对象,实现Delay接口
package com.itheima.thread.order;
import com.itheima.thread.mapper.Orders;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class OrderDto implements Delayed {
private int id;
private long invalid;
public OrderDto(Orders o){
this.id = o.getId();
this.invalid = o.getInvalid()*1000 + System.currentTimeMillis();
}
//倒计时,降到0时队列会吐出该任务
@Override
public long getDelay(TimeUnit unit) {
return invalid ‐ System.currentTimeMillis();
}
@Override
public int compareTo(Delayed o) {
OrderDto o1 = (OrderDto) o;
return this.invalid ‐ o1.invalid <= 0 ? ‐1 : 1;
}
public int getId() {
return id;
}
public long getInvalid() {
return invalid;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
- 定义监控类,启动守护进程,如果有超时任务,提交进线程池
package com.itheima.thread.order;
import com.itheima.thread.mapper.Orders;
import com.itheima.thread.mapper.OrdersMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.Date;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Component
public class OrderMonitor {
@Autowired
OrdersMapper mapper ;
//延时队列
final DelayQueue<OrderDto> queue = new DelayQueue<OrderDto>();
//任务池
ExecutorService service = Executors.newFixedThreadPool(2);
//投放延迟订单
public void put(OrderDto dto){
this.queue.put(dto);
System.out.println("put task:"+dto.getId());
}
//在构造函数中启动守护线程
public OrderMonitor(){
this.execute();
System.out.println("monitor started");
}
//守护线程
public void execute(){
new Thread(()‐>{
while (true){
try {
OrderDto dto = queue.take();
System.out.println("take task:"+dto.getId());
service.execute(new Task(dto));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
//任务类
class Task implements Runnable{
OrderDto dto;
Task(OrderDto dto){
this.dto = dto;
}
@Override
public void run() {
Orders orders = new Orders();
orders.setId(dto.getId());
orders.setUpdatetime(new Date());
orders.setStatus(‐1);
System.out.println("cancel order:"+orders.getId());
mapper.updateByPrimaryKeySelective(orders);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
- 在add订单业务中,同时扔一份到queue,注意事务性
@PostMapping("/add")
@Transactional
public int add(@RequestParam String name){
Orders order = new Orders();
order.setName(name);
order.setCreatetime(new Date());
order.setUpdatetime(new Date());
//超时时间,取10‐20之间的随机数(秒)
order.setInvalid(new Random().nextInt(10)+10);
order.setStatus(0);
mapper.insert(order);
//事务性验证
// int i = 1/0;
monitor.put(new OrderDto(order));
return order.getId();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2.3 加/减库存
# 2.3.1 设计方案
1)rabbitmq异步排队:使用rabbitmq先排队,请求到来时之间入队,界面显示排队中,消费端逐个消费,同时扣减库存,界面轮询查询结果。可能会出现排队半天抢完的情况。
2)库存预热:使用缓存或内存变量,活动开始前从db中提取库存值初始化,请求到来时直接扣减,及时提醒。可能出现一种感觉,活动刚开始就抢没了……
实际企业秒杀场景下,方案1居多,为讲解多线程,本课程采用2
# 2.3.2 实现
初始化库存缓存
public Map load(){
products.clear();
List<Product> list = productMapper.selectByExample(null);
list.forEach(p ‐> {
products.put(p.getId(),new AtomicInteger(p.getNum()));
});
return products;
}
2
3
4
5
6
7
8
抢购代码,开启10个线程,不停去抢,减库存,如果抢到,异步刷库。
public void go(int productId){
for (int i = 0; i < 10; i++) {
new Thread(()‐>{
int count = 0;
long userId = Thread.currentThread().getId();
while (products.get(productId).getAndDecrement() > 0){
count++;
//扔消息队列,异步处理
template.convertAndSend("promotion.order",productId+","+userId);
}
System.out.println(Thread.currentThread().getName()+"抢到:"+count);
}).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
注意分析控制台结果:
- 前端线程立刻抢购得到结果,给出每个线程抢到的商品数
- 后面异步处理缓慢得到结果,操作db
# 2.4 价格排序
# 2.4.1 设计方案
1)直接数据库sort,这种最典型
2)redis缓存zset获取,在商品列表缓存,web网站排序场景中常见
3)内存排序,有时候,需要复杂的运算和比较逻辑,sql sort操作表达不出来时,必须进入内存运算
本课程使用方案3,规则模拟按价格排序
# 2.4.2 实现
1)针对内存排序,首先想到的是实现Comparable接口,在多线程知识背景下,可以运用所学的ForkJoin实现归并排序。
2)算法回顾
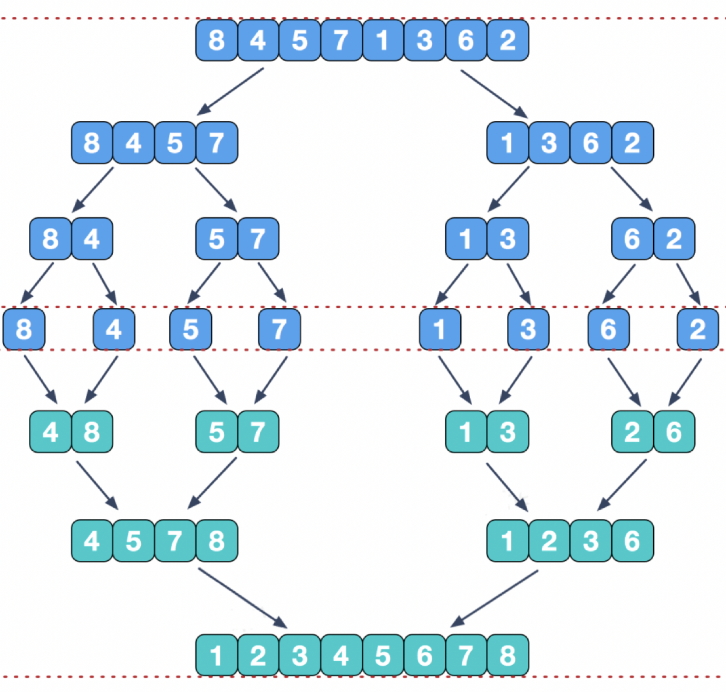
3)ForkJoinTask,任务实现算法
package com.itheima.thread.order;
import com.itheima.thread.mapper.Product;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RecursiveTask;
public class SortTask extends RecursiveTask<List<Product>> {
private List<Product> list;
public SortTask(List<Product> list){
this.list = list;
}
@Override
//分拆与合并
protected List<Product> compute() {
if (list.size() > 2){
//如果拆分的长度大于2,继续拆
int middle = list.size() / 2 ;
//拆成两个
List<Product> left = list.subList(0,middle);
List<Product> right = list.subList(middle+1,list.size());
//子任务fork出来
SortTask task1 = new SortTask(left);
task1.fork();
SortTask task2 = new SortTask(right);
task2.fork();
//join并返回
return mergeList(task1.join(),task2.join());
}else if (list.size() == 2 && list.get(0).getPrice() > list.get(1).getPrice()){
//如果长度达到2个了,但是顺序不对,交换一下
//其他如果2个且有序,或者1个元素的情况,不需要管他
Product p = list.get(0);
list.set(0,list.get(1));
list.set(1,p);
}
//交换后的返回,这个list已经是每个拆分任务里的有序值了
return list;
}
//归并排序的合并操作,目的是将两个有序的子list合并成一个整体有序的集合
//遍历两个子list,依次取值,两边比较,从小到大放入新list
//注意,left和right是两个有序的list,已经从小到大排好序了
private List<Product> mergeList(List<Product> left,List<Product> right){
if (left == null || right == null) return null;
//合并后的list
List<Product> total = new ArrayList<>(left.size()+right.size());
//list1的下标
int index1 = 0;
//list2的下标
int index2 = 0;
//逐个放入total,所以需要遍历两个size的次数之和
for (int i = 0; i < left.size()+right.size(); i++) {
//如果list1的下标达到最大,说明list1已经都全部放入total
if (index1 == left.size()){
//那就从list2挨个取值,不需要比较直接放入total
total.add(i,right.get(index2++));
continue;
}else if (index2 == right.size()){
//如果list2已经全部放入,那规律一样,取list1
total.add(i,left.get(index1++));
continue;
}
//到这里说明,1和2中还都有元素,那就需要比较,把小的放入total
//list1当前商品的价格
Float p1 = left.get(index1).getPrice();
//list2当前商品的价格
Float p2 = right.get(index2).getPrice();
Product min = null;
//取里面价格小的,取完后,将它的下标增加
if (p1 <= p2){
min = left.get(index1++);
}else{
min = right.get(index2++);
}
//放入total
total.add(min);
}
//这样处理后,total就变为两个子list的所有元素,并且从小到大排好序
System.out.println(total);
System.out.println("‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐");
return total;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
4)调用过程
package com.itheima.thread.order;
import com.itheima.thread.mapper.Product;
import com.itheima.thread.mapper.ProductMapper;
import io.swagger.annotations.Api;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
@RestController
@RequestMapping("/sort")
@Api(value = "多线程排序测试demo")
public class SortController {
@Autowired
ProductMapper mapper;
@GetMapping("/list")
List<Product> sort() throws ExecutionException, InterruptedException {
//查商品列表
List<Product> list = mapper.selectByExample(null);
//线程池
ForkJoinPool pool = new ForkJoinPool(2);
//开始运算,拆分与合并
Future<List<Product>> future = pool.submit(new SortTask(list));
return future.get();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
