 Redis
Redis
# 1 什么是缓存击穿,如何解决缓存击穿
# 题目描述
什么是缓存击穿,如何解决缓存击穿 题目解决
# 缓存击穿
存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。 缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓
# 解决缓存击穿
# 解决方案一
当数据库和redis中都不存在key,在数据库返回null时,在redis中插入<key,null,expireTime>当 key再次请求时,redis直接返回null,而不用再次请求数据库。
# 解决方案二
可以设置一些过滤规则, 如布隆过滤器
将数据库中所有的查询条件,放入布隆过滤器中,
当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请
求查询不存在,直接丢弃。
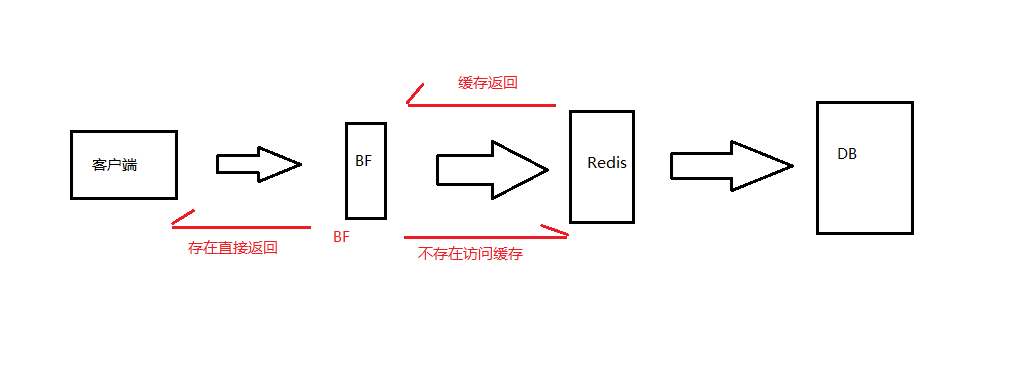
# 布隆过滤器的方式解决缓存穿透问题(重点)
# 简介
布隆过滤器(Bloom Filter,下文简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率
高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。听起来是很稀松平常的需求,为什
么要使用BF这种数据结构呢?
# 优缺点
优点:
不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
时间效率也较高,插入和查询的时间复杂度均为O(k);
哈希函数之间相互独立,可以在硬件指令层面并行计算。
缺点:
存在假阳性的概率,不适用于任何要求100%准确率的情境;
只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。
所以,BF在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适,另外,由于它不存在假阴性问题,所以用作“不存在”逻辑的处理时有奇效,比如可以用来作为缓存系统(如Redis)的缓存,防止缓存穿透。
# 设计思想
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。
位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是0,就是1。
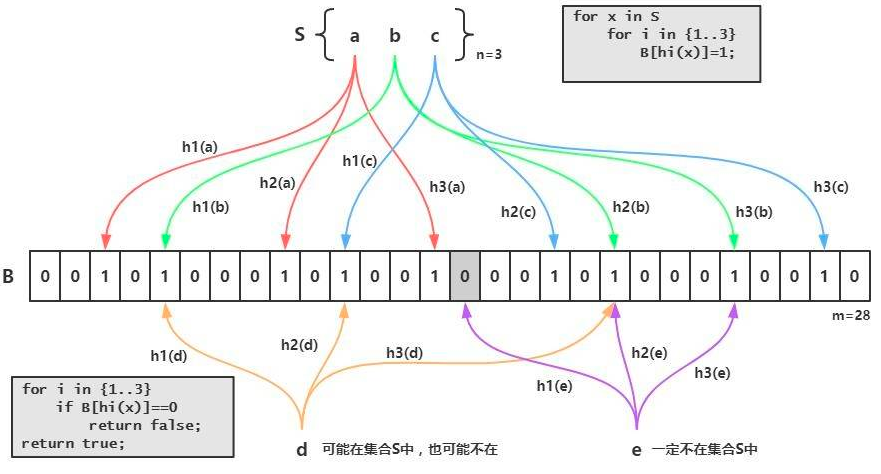
现在我们新建一个长度为16的布隆过滤器,默认值都是0,就像下面这样:

现在需要添加一个数据:
我们通过某种计算方式,比如Hash1,计算出了Hash1(数据)=5,我们就把下标为5的格子改成1,就像下面这样:

我们又通过某种计算方式,比如Hash2,计算出了Hash2(数据)=9,我们就把下标为9的格子改成1,就像下面这样:

还是通过某种计算方式,比如Hash3,计算出了Hash3(数据)=2,我们就把下标为2的格子改成1,就像下面这样:

这样,刚才添加的数据就占据了布隆过滤器“5”,“9”,“2”三个格子。
可以看出,仅仅从布隆过滤器本身而言,根本没有存放完整的数据,只是运用一系列随机映射函数计算出位置,然后填充二进制向量。
这有什么用呢?比如现在再给你一个数据,你要判断这个数据是否重复,你怎么做?
你只需利用上面的三种固定的计算方式,计算出这个数据占据哪些格子,然后看看这些格子里面放置的
刚才你添加进去的数据,你通过三种固定的计算方式,算出的结果肯定和上面的是一模一样的,也是占 是否都是1,如果有一个格子不为1,那么就代表这个数字不在其中。这很好理解吧,比如现在又给你了 据了布隆过滤器“5”,“9”,“2”三个格子。
但是有一个问题需要注意,如果这些格子里面放置的都是1,不一定代表给定的数据一定重复,也许其他数据经过三种固定的计算方式算出来的结果也是相同的。这也很好理解吧,比如我们需要判断对象是否相等,是不可以仅仅判断他们的哈希值是否相等的。
也就是说布隆过滤器只能判断数据是否一定不存在,而无法判断数据是否一定存在。如图:
按理来说,介绍完了新增、查询的流程,就要介绍删除的流程了,但是很遗憾的是布隆过滤器是很难做 到删除数据的,为什么?你想想,比如你要删除刚才给你的数据,你把“5”,“9”,“2”三个格子都改成了 0,但是可能其他的数据也映射到了“5”,“9”,“2”三个格子啊,这不就乱套了吗?
# Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit 数组的大小m,以及hash函数的个数k,并选择hash函数
# Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式: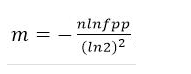
# 哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k: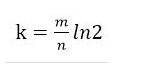
- 哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到 各个Bit。
- 选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参 数。
看看Guava中BloomFilter中对于m和k值计算的实现,在com.google.common.hash.BloomFilter类 中:
/** * 计算 Bloom Filter的bit位数m *
* <p>See http://en.wikipedia.org/wiki/Bloom_filter#Probability_of_false_positives for the
* formula.
*
* @param n 预期数据量
* @param p 误判率 (must be 0 < p < 1)
*/
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算最佳k值,即在Bloom过滤器中插入的每个元素的哈希数
*
* <p>See http://en.wikipedia.org/wiki/File:Bloom_filter_fp_probability.svg for the formula.
*
* @param n 预期数据量
* @param m bloom filter中总的bit位数 (must be positive)
*/
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
BloomFilter实现的另一个重点就是怎么利用hash函数把数据映射到bit数组中。Guava的实现是对元素 通过MurmurHash3计算hash值,将得到的hash值取高8个字节以及低8个字节进行计算,以得当前元 素在bit数组中对应的多个位置。MurmurHash3算法详见:Murmur哈希 (opens new window),于2008年被发明。这个算法 hbase,redis,kafka都在使用。
这个过程的实现在两个地方:
- 将数据放入bloom filter中
- 判断数据是否已在bloom filter中
这两个地方的实现大同小异,区别只是,前者是put数据,后者是查数据。
这里看一下put的过程,hash策略以MURMUR128_MITZ_64为例:
public <T> boolean put( T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
//利用MurmurHash3得到数据的hash值对应的字节数组
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
//取低8个字节、高8个字节,转成long类型
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
//这里的combinedHash = hash1 + i * hash2
long combinedHash = hash1;
//根据combinedHash,得到放入的元素在bit数组中的k个位置,将其置1
for (int i = 0; i < numHashFunctions; i++) {
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
判断元素是否在bloom filter中的方法mightContain与上面的实现基本一致,不再赘述。
# Bloom Filter的使用
简单写个demo,用法很简单
package com.qunar.sage.wang.common.bloom.filter;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.Funnels;
import com.goo gle.common.hash.PrimitiveSink;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.ToString;
/**
* BloomFilterTest
*
*/
public class BloomFilterTest {
public static void main(String[] args) {
long expectedInsertions = 10000000;
double fpp = 0.00001;
BloomFilter < CharSequence > bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions, fpp);
bloomFilter.put("aaa");
bloomFilter.put("bbb");
boolean containsString = bloomFilter.mightContain("aaa");
System.out.println(containsString);
BloomFilter < Email > emailBloomFilter = BloomFilter.create((Funnel < Email > )(from, into) - > into.putString(from.getDomain(), Charsets.UTF_8), expectedInsertions, fpp);
emailBloomFilter.put(new Email("sage.wang", "quanr.com"));
boolean containsEmail = emailBloomFilter.mightContain(new Email("sage.wangaaa", "quanr.com"));
System.out.println(containsEmail);
}
@Data
@Builder
@ToString
@AllArgsConstructor
public static class Email {
private String userName;
private String domain;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 练习题
1.基于Spring boot 模拟并解决缓存穿透
# 2 缓存雪崩
# 题目描述
什么是缓存雪崩,如何解决缓存击穿
# 题目解决
# 缓存雪崩
缓存层承载着大量的请求,有效保护了存储层。但是如果由于缓存大量失效或者缓存整体不能提供服 务,导致大量的请求到达存储层,会使存储层负载增加,这就是缓存雪崩的场景。
# 解决缓存雪崩
- 1.保持缓存层的高可用性
使用Redis 哨兵模式或者Redis 集群部署方式,即便个别Redis 节点下线,整个缓存层依然可以使用。
除此之外,还可以在多个机房部署 Redis,这样即便是机房死机,依然可以实现缓存层的高可用。
- 2.限流降级组件
无论是缓存层还是存储层都会有出错的概率,可以将它们视为资源。作为并发量较大的分布式系统,假 如有一个资源不可用,可能会造成所有线程在获取这个资源时异常,造成整个系统不可用。降级在高并 发系统中是非常正常的,比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至 于造成整个推荐服务不可用。常见的限流降级组件如 Hystrix、Sentinel 等。
- 3.缓存不过期
Redis 中保存的 key 永不失效,这样就不会出现大量缓存同时失效的问题,但是随之而来的就是Redis 需要更多的存储空间。
- 4.优化缓存过期时间
设计缓存时,为每一个 key 选择合适的过期时间,避免大量的 key 在同一时刻同时失效,造成缓存雪 崩。
- 5.使用互斥锁重建缓存
在高并发场景下,为了避免大量的请求同时到达存储层查询数据、重建缓存,可以使用互斥锁控制,如 根据 key 去缓存层查询数据,当缓存层为命中时,对 key 加锁,然后从存储层查询数据,将数据写入缓 存层,最后释放锁。若其他线程发现获取锁失败,则让线程休眠一段时间后重试。对于锁的类型,如果 是在单机环境下可以使用 Java 并发包下的 Lock,如果是在分布式环境下,可以使用分布式锁(Redis 中的 SETNX 方法)
分布式环境下使用Redis 分布式锁实现缓存重建,优点是设计思路简单,对数据一致性有保障;缺点是 代码复杂度增加,有可能会造成用户等待。假设在高并发下,缓存重建期间 key 是锁着的,如果当前并 发 1000 个请求,其中 999 个都在阻塞,会导致 999 个用户请求阻塞而等待。
- 6.异步重建缓存
在这种方案下构建缓存采取异步策略,会从线程池中获取线程来异步构建缓存,从而不会让所有的请求 直接到达存储层,该方案中每个Redis key 维护逻辑超时时间,当逻辑超时时间小于当前时间时,则说 明当前缓存已经失效,应当进行缓存更新,否则说明当前缓存未失效,直接返回缓存中的 value 值。如 在Redis 中将 key 的过期时间设置为 60 min,在对应的 value 中设置逻辑过期时间为 30 min。这样当 key 到了 30 min 的逻辑过期时间,就可以异步更新这个 key 的缓存,但是在更新缓存的这段时间内, 旧的缓存依然可用。这种异步重建缓存的方式可以有效避免大量的 key 同时失效。
# 练习题
1.基于Spring boot 模拟并解决缓存穿透
# 3 缓存穿透,缓存击穿,缓存雪崩
# 题⽬描述
描述⼀下你对Redis缓存穿透,缓存击穿,缓存雪崩的理解,以及简单描述⼀下每种情况的解决⽅案
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:三种情况发⽣的概念描述与原因,解决⽅案
# 缓存穿透,缓存击穿,缓存雪崩
- 缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会 到数据源,从⽽可能压垮数据源。⽐如⽤⼀个不存在的⽤户id获取⽤户信息,不论缓存还是数据库 都没有,若⿊客利⽤此漏洞进⾏攻击可能压垮数据库。
- 缓存击穿:key对应的数据存在,但在redis中过期,此时若有⼤量并发请求过来,这些请求发现缓存过期⼀般都会从后端DB加载数据并回设到缓存,这个时候⼤并发的请求可能会瞬间把后端DB压 垮。
- 缓存雪崩:当缓存服务器重启或者⼤量缓存集中在某⼀个时间段失效,这样在失效的时候,也会给 后端系统(⽐如DB)带来很⼤压⼒。
# 缓存穿透,缓存击穿,缓存雪崩解决⽅案
# 1.缓存穿透解决⽅案
⼀个⼀定不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存 储层查不到数据则不写⼊缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存 的意义。
有很多种⽅法可以有效地解决缓存穿透问题,最常⻅的则是采⽤布隆过滤器,将所有可能存在的数据哈 希到⼀个⾜够⼤的bitmap中,⼀个⼀定不存在的数据会被 这个bitmap拦截掉,从⽽避免了对底层存储 系统的查询压⼒。另外也有⼀个更为简单粗暴的⽅法(我们采⽤的就是这种),如果⼀个查询返回的数 据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进⾏缓存,但它的过期时间会很 短,最⻓不超过五分钟。
// 伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if(cacheValue != null) {
return cacheValue;
}
cacheValue = CacheHelper.Get(cacheKey);
if(cacheValue != null) {
return cacheValue;
} else {
//数据库查询不到,为空
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//如果发现为空,设置个默认值,也缓存起来
cacheValue = string.Empty;
}
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 2.缓存击穿解决⽅案
key可能会在某些时间点被超⾼并发地访问,是⼀种⾮常“热点”的数据。这个时候,需要考虑⼀个问题: 缓存被“击穿”的问题。
使⽤互斥锁(mutex key)
业界⽐较常⽤的做法,是使⽤mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空), 不是⽴即去load db,⽽是先使⽤缓存⼯具的某些带成功操作返回值的操作(⽐如Redis的SETNX或者 Memcache的ADD)去set⼀个mutex key,当操作返回成功时,再进⾏load db的操作并回设缓存;否 则,就重试整个get缓存的⽅法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利⽤它来实现锁的效 果。
// 伪代码
public String get(key) {
String value = redis.get(key);
if (value == null) {
//代表缓存值过期
//设置3min的超时,防⽌del操作失败的时候,下次缓存过期⼀直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) {
//代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else {
//这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓 存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 3.缓存雪崩解决⽅案
缓存失效时的雪崩效应对底层系统的冲击⾮常可怕!⼤多数系统设计者考虑⽤加锁或者队列的⽅式保证 来保证不会有⼤量的线程对数据库⼀次性进⾏读写,从⽽避免失效时⼤量的并发请求落到底层存储系统 上。还有⼀个简单⽅案就时讲缓存失效时间分散开,⽐如我们可以在原有的失效时间基础上增加⼀个随 机值,⽐如1-5分钟随机,这样每⼀个缓存的过期时间的重复率就会降低,就很难引发集体失效的事 件。
加锁排队只是为了减轻数据库的压⼒,并没有提⾼系统吞吐量。假设在⾼并发下,缓存重建期间key是 锁着的,这是过来1000个请求999个都在阻塞的。同样会导致⽤户等待超时,这是个治标不治本的⽅ 法!
注意:加锁排队的解决⽅式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻 塞,⽤户体验很差!因此,在真正的⾼并发场景下很少使⽤!
// 加锁排队伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String lockKey = cacheKey;
String cacheValue = CacheHelper.get(cacheKey);
if(cacheValue != null) {
return cacheValue;
} else {
synchronized(lockKey) {
cacheValue = CacheHelper.get(cacheKey);
if(cacheValue != null) {
return cacheValue;
} else {
//这⾥⼀般是sql查询数据
cacheValue = GetProductListFromDB();
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
}
}
return cacheValue;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 总结
针对业务系统,永远都是具体情况具体分析,没有最好,只有最合适。
于缓存其它问题,缓存满了和数据丢失等问题,⼤伙可⾃⾏学习。最后也提⼀下三个词LRU、RDB、 AOF,通常我们采⽤LRU策略处理溢出,Redis的RDB和AOF持久化策略来保证⼀定情况下的数据安全。
# 4 并发竞争key的解决方案
# 题目描述
Redis并发竞争key的解决方案详解?
# 面试题分析
Redis缓存的高性能有目共睹,应用的场景也是非常广泛,但是在高并发的场景下,也会出现问题,数 据一致性方案,如何解决Redis缓存雪崩、缓存穿透、缓存并发,以及今天要谈到的Redis并发竞争问 题,这里的并发指的是多个redis的client同时set key引起的并发问题。
比如:多客户端同时并发写一个key,一个key的值是1,本来按顺序修改为2,3,4,最后是4,但是由于并发设置的原因,最后顺序变成了4,3,2,最后变成的key值成了2。
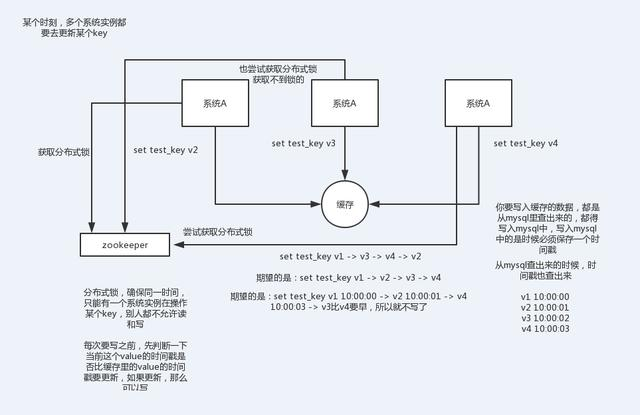
# 解决Redis的并发竞争key问题
# 第一种方案:分布式锁
# 1.整体技术方案
这种情况,主要是准备一个分布式锁,大家去抢锁,抢到锁就做set操作。
# 2.为什么是分布式锁
因为传统的加锁的做法(如java的synchronized和Lock)这里没用,只适合单点。因为这是分布式环 境,需要的是分布式锁。
当然,分布式锁可以基于很多种方式实现,比如zookeeper、redis等,不管哪种方式实现,基本原理 是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
# 3.分布式锁的要求
互斥性:在任意一个时刻,只有一个客户端持有锁。 无死锁:即便持有锁的客户端崩溃或者其他意外事件,锁仍然可以被获取。 容错:只要大部分Redis节点都活着,客户端就可以获取和释放锁
# 4.分布式锁的实现方式
数据库 Memcached(add命令) redis(setnx命令) Zookeeper(临时节点)
# 第二种方案:利用消息队列
在并发量过大的情况下,可以通过消息中间件进行处理,把并行读写进行串行化。
把Redis.set操作放在队列中使其串行化,必须的一个一个执行。
这种方式在一些高并发的场景中算是一种通用的解决方案。
# 5 RDB持久化、AOF持久化
# 题目描述
Redis RDB持久化、AOF持久化
# 题目解决
# 1.持久化
# 1.1 持久化简介
持久化(Persistence),持久化是将程序数据在持久状态和瞬时状态间转换的机制,即把数据(如内 存中的对象)保存到可永久保存的存储设备中(如磁盘)。

# 1.2 redis持久化
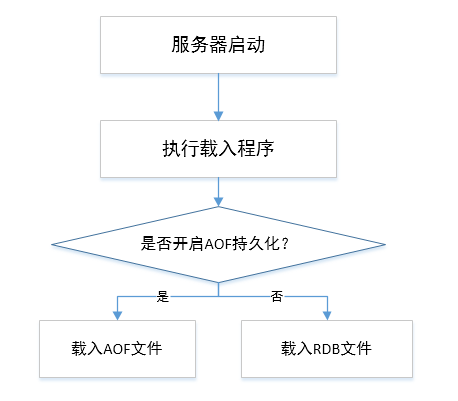
redis为内存数据库,为了防止服务器宕机以及服务器进程退出后,服务器数据丢失,Redis提供了持久 化功能,即将Redis中内存数据持久化到磁盘中。Redis 提供了不同级别的持久化方式:
- RDB持久化方式:可以在指定的时间间隔能对数据进行快照存储.
- AOF持久化方式:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原 始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台 重写,使得AOF文件的体积不至于过大.
如果服务器开启了AOF持久化功能。服务器会优先使用AOF文件还原数据。只有关闭了AOF持久化功 能,服务器才会使用RDB文件还原数据
# 2.RDB持久化
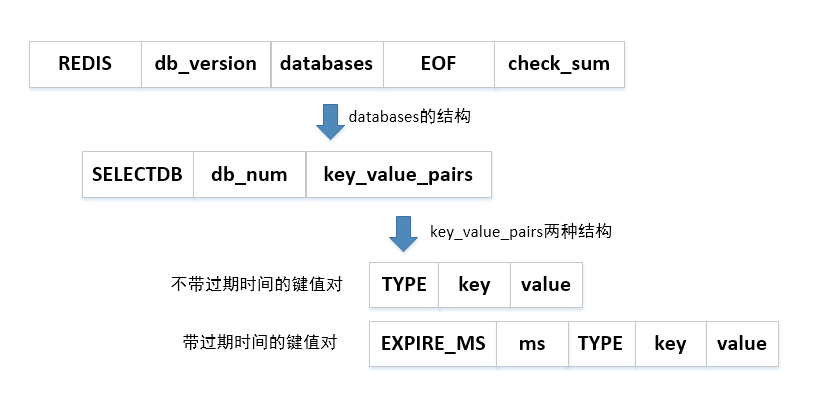
# 2.1 RDB文件格式
RDB文件是一个经过压缩的二进制文件(默认的文件名:dump.rdb),由多个部分组成,RDB格式:
# 2.2 RDB文件持久化创建与载入
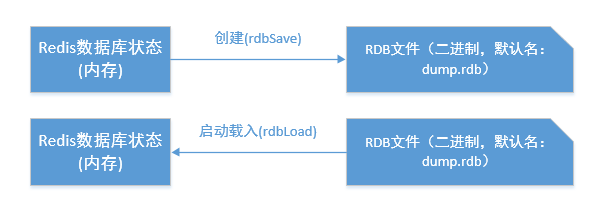
在 Redis持久化时, RDB 程序将当前内存中的数据库状态保存到磁盘文件中, 在 Redis 重启动时, RDB 程序可以通过载入 RDB 文件来还原数据库的状态。
# 2.3 工作方式
当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
- Redis 调用forks。同时拥有父进程和子进程。
- 子进程将数据集写入到一个临时 RDB 文件中。
- 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
# 2.4 创建方式
SAVE
同步操作,在执行该命令时,服务器会被阻塞,拒绝客户端发送的命令请求
redis> save
1
2

BGSAVE
异步操作,在执行该命令时,子进程执行保存工作,服务器还可以继续让主线程处理客户端发送的命令 请求
redis>bgsave
1
2
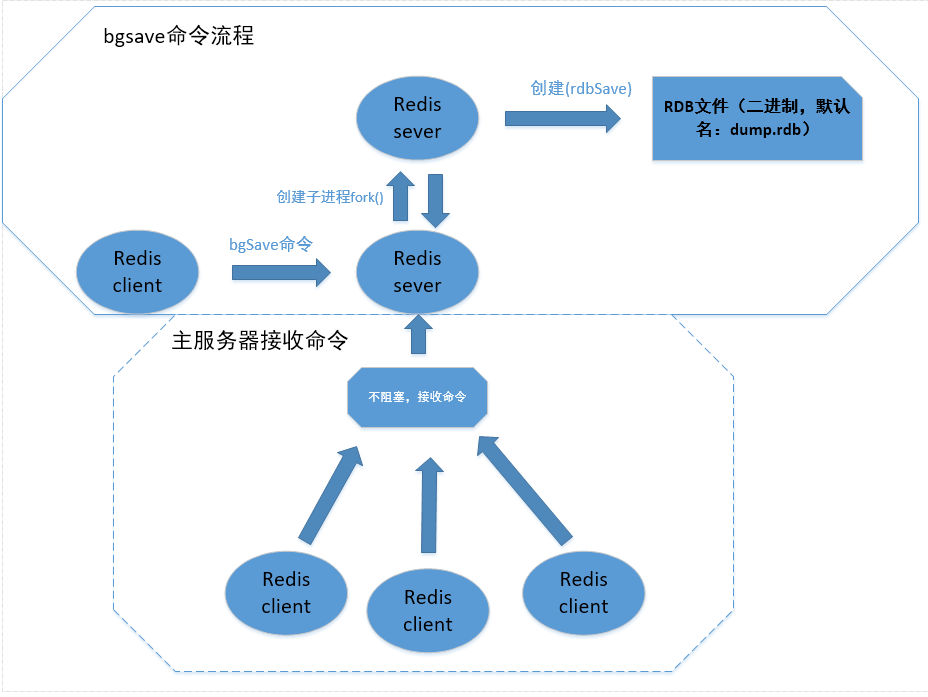
自动创建
由于BGSAVE命令可不阻塞服务器进程下执行,可以让用户自定义save属性,让服务器每个一段时间自 动执行一次BGSAVE命令(即通过配置文件对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改 动”这一条件被满足时, 自动进行数据集保存操作)。
比如:
/*服务器在900秒之内,对数据库进行了至少1次修改*/
Save 900 1
/*服务器在300秒之内,对数据库进行了至少10次修改*/
Save 300 10
/*服务器在60秒之内,对数据库进行了至少10000次修改*/
Save 60 10000
1234567
2
3
4
5
6
7
8
只要满足其中一个条件就会执行BGSAVE命令
# 2.5 RDB 默认配置
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#在给定的秒数和给定的对数据库的写操作数下,自动持久化操作。
# save <seconds> <changes>
#
save 900 1
save 300 10
save 60 10000
#bgsave发生错误时是否停止写入,一般为yes
stop-writes-on-bgsave-error yes
#持久化时是否使用LZF压缩字符串对象?
rdbcompression yes
#是否对rdb文件进行校验和检验,通常为yes
rdbchecksum yes
# RDB持久化文件名
dbfilename dump.rdb
#持久化文件存储目录
dir ./ 123456789101112131415161718192021222324
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 3.AOF持久化
# 3.1 AOF持久化简介
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态
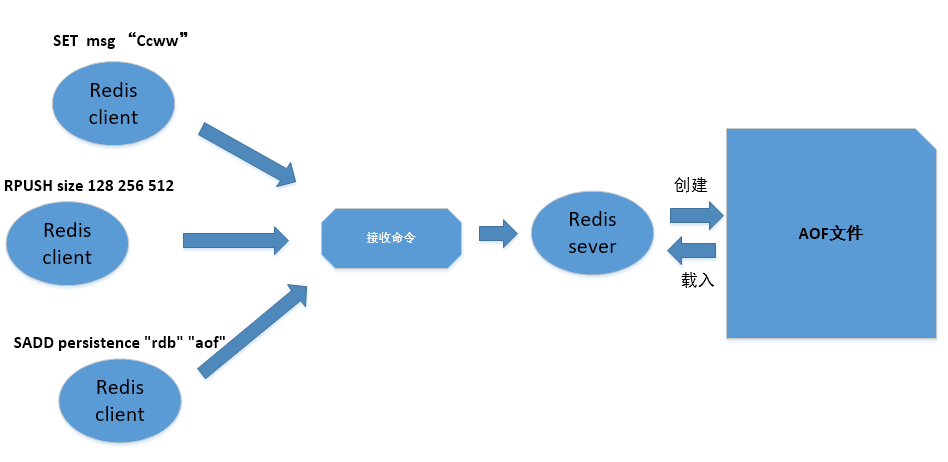
AOF持久化功能实现:
- append命令追加:当AOF持久化功能处于打开状态时,服务器执行完一个写命令会协议格式被执 行的命令追加服务器状态的aof_buf缓冲区的末尾。
reids>SET KET VAULE
//协议格式
\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVAULE\r\n 123
2
3
- 文件写入和同步sync:Redis的服务器进程是一个事件循环,这个文件事件负责接收客户端的命令 请求以及向客户端发送命令回复。当执行了append命令追加后,服务器会调用 flushAppendOnlyFile函数是否需要将AOF缓冲区的内容写入和保存到AOF文件
redis> SET msg "Ccww"
redis> SADD persistence "rdb" "aof"
redis> RPUSH size 128 256 512
123
2
3
4
# 3.2 AOF持久化策略
AOF持久化策略(即缓冲区内容写入和同步sync到AOF中),可以通过配置appendfsync属性来选择AOF 持久化策略:
- always:将aof_buf缓冲区中的所有内容写入并同步到AOF文件,每次有新命令追加到 AOF 文件时 就执行一次 fsync。
- everysec(默认):如果上次同步AOF的时间距离现在超过一秒,先将aof_buf缓冲区中的所有内 容写入到AOF文件,再次对AOF文件进行同步,且同步操作由一个专门线程负责执行。
- no:将aof_buf缓冲区中的所有内容写入到AOF文件,但并不对AOF文件进行同步,何时同步由操 作系统(OS)决定。
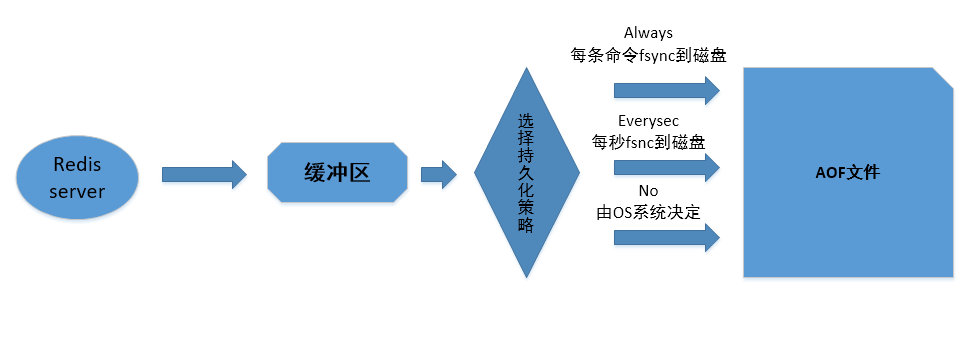
AOF持久化策略的效率与安全性:
- Always:效率最慢的,但安全性是最安全的,即使出现故障宕机,持久化也只会丢失一个事件 循环 的命令数据
- everysec:兼顾速度和安全性, 出现宕机也只是丢失一秒钟的命令数据
- No:写入最快,但综合起来单次同步是时间是最长的,且出现宕机时会丢失上传同步AOF文件之后 的所有命令数据。
# 3.3 AOF重写
由于AOF持久化会把执行的写命令追加到AOF文件中,所以随着时间写入命令会不断增加, AOF文件的 体积也会变得越来越大。AOF文件体积大对Reids服务器,甚至宿主服务器造成影响。
为了解决AOF文件体积膨胀的问题,Redis提供了AOF文件重写(rewrite)功能:
- 生成一个不保存任何浪费空间的冗余命令新的AOF文件,且新旧AOF文件保存数据库状态一样的
- 新的AOF文件是通过读取数据库中的键值对来实现的,程序无须对现有的AOF文件进行读入,分 析,或者写入操作。
- 为防止缓冲区溢出,重写处理list,hash,set以及Zset时,超过设置常量数量时会多条相同命令记 录一个集合。
- Redis 2.4 可以通过配置自动触发 AOF 重写,触发参数 auto-aof-rewrite-percentage (触发 AOF文件执行重写的增长率) 以及 auto-aof-rewrite-min-size (触发AOF文件执行重写的最小尺 寸)
AOF重写的作用:
- 减少磁盘占用量
- 加速数据恢复
Redis服务器使用单个线程来处理命令请求,服务器大量调用aof_rewrite函数,在AOF重写期间,则无 法处理client发来的命令请求,所以AOF重写程序放在子进程执行,好处:
子进程进行AOF重写期间,服务器进程可以继续处理命令请求
子进程带有服务器进程的数据副本,保证了数据的安全性。
AOF重写使用子进程会造成数据库与重写后的AOF保存的数据不一致,为了解决这种数据不一致,redis 使用了AOF重写缓冲区
实现:
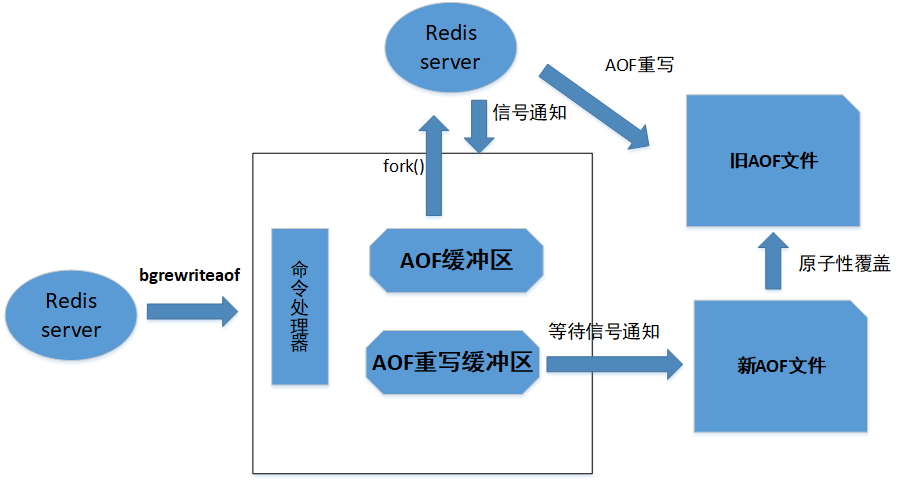
BGREWRITEAOF命令实现原理(只有信号处理函数执行时才对服务器进程造成阻塞):
- 执行命令,同时将命令追加到AOF缓冲区和AOF重写缓冲区
- 当AOF子进程重写完成后,发送一个信号给父进程,父进程将执行AOF重写缓冲区中的所有内容写 入到新AOF文件中,新AOF文件保存的数据库状态将和服务器当前的数据库状态一致。
- 对新的AOF文件进行改名,原子性地覆盖现有AOF文件,完成新旧两个AOF文件替换处理完成。
# 3.4 AOF持久化默认参数
############################## APPEND ONLY MODE ###############################
#开启AOF持久化方式
appendonly no
#AOF持久化文件名
appendfilename "appendonly.aof"
#每秒把缓冲区的数据fsync到磁盘
appendfsync everysec
# appendfsync no
#是否在执行重写时不同步数据到AOF文件
no-appendfsync-on-rewrite no
# 触发AOF文件执行重写的增长率
auto-aof-rewrite-percentage 100
#触发AOF文件执行重写的最小size
auto-aof-rewrite-min-size 64mb
#redis在恢复时,会忽略最后一条可能存在问题的指令
aof-load-truncated yes
#是否打开混合开关
aof-use-rdb-preamble yes
1234567891011121314151617181920212223
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 4 持久化方式总结与抉择
# 4.1 RDB优缺点
RDB的优点
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在 每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可 以根据需求恢复到不同版本的数据集.
- 基于RDB文件紧凑性,便于复制数据到一个远端数据中心,非常适用于灾难恢复.
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来 做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能. 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
RDB的缺点
如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适 合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis 要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存, 万一在Redis意外宕机,你可能会丢失几分钟的数据.
RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的, 可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的 情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的 耐久度.
# 4.2 AOF的优缺点
AOF的优点:
- 使用AOF 会让你的Redis更加耐久:使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync. 使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处 理客户端请求),一旦出现故障,你最多丢失1秒的数据.
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写 的过程中宕机等等)未执行完整的写入命令,你也可使用redis-check-aof工具修复问题.
- Redis可以在AOF文件体积变得过大时,自动对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复 当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的 过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件 也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开 始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单(例如, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重 写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数 据集恢复到 FLUSHALL 执行之前的状态)。
AOF 缺点:
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依 然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过 在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
# 4.3 如何选择使用哪种持久化方式?
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot) 非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使 用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
# 6 Redis缓存和MySQL数据一致性的解决方案
# 题目描述
Redis缓存和MySQL数据一致性的解决方案
# 面试题分析
根据题目要求我们可以知道:
- 采用延时双删策略保证缓存和mysql数据一致
- 异步更新缓存保证缓存和mysql数据一致
分析需要全面并且有深度
容易被忽略的坑
- 分析片面
- 没有深入
# 需求分析
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做 一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库。
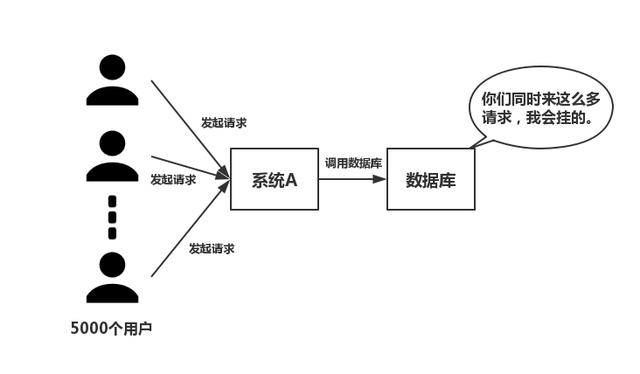
这个业务场景,主要是解决读数据从Redis缓存,一般都是按照下图的流程来进行业务操作。
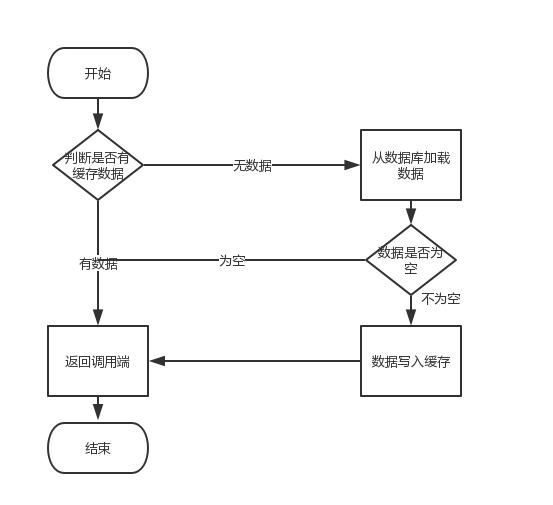
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存 (Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的 情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库 中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
如来解决?这里给出两个解决方案,先易后难,结合业务和技术代价选择使用。
# 缓存和数据库一致性解决方案
# 第一种方案:采用延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
伪代码如下
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(500);
redis.delKey(key);
}
2
3
4
5
6
1.具体的步骤
1)先删除缓存
2)再写数据库
3)休眠500毫秒
4)再次删除缓存
那么,这个500毫秒怎么确定的,具体该休眠多久呢? 需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除
读请求造成的缓存脏数据。
当然这种策略还要考虑redis和数据库主从同步的耗时。最后的的写数据的休眠时间:则在读数据业务逻 辑的耗时基础上,加几百ms即可。比如:休眠1秒。
2.设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
3.该方案的弊端
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
# 第二种方案:异步更新缓存**(基于订阅binlog**的同步机制)
1.技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
1**)读**Redis:热数据基本都在Redis
2**)写**MySQL:增删改都是操作MySQL
3**)更新Redis数据**:MySQ的数据操作binlog,来更新到Redis
2.Redis更新
1**)数据操作主要分为两大块:**
- 一个是全量(将全部数据一次写入到redis)
- 一个是增量(实时更新)
2**)读取binlog后分析 ,利用消息队列**,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis, Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致 性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正 是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis。
- 扩展内容
MySQL主从同步的方案,及优劣比较 Redis哨兵、复制、集群的设计原理及区别 如何解决Redis缓存雪崩、缓存穿透、缓存并发等难题 Redis的内存回收原理,及Redis内存过期淘汰策略
# 7 Redis为什么是单线程、及高并发快的原因
# 题目描述
Redis为什么是单线程、及高并发快的原因
# 面试题分析
根据题目要求我们可以知道:
Redis的高并发和快速原因
为什么Redis是单线程的
Redis单线程的优劣势
IO多路复用技术
Redis高并发快总结
分析需要全面并且有深度
容易被忽略的坑
- 分析片面
- 没有深入
# Redis的高并发和快速原因
1.redis是基于内存的,内存的读写速度非常快;
2.redis是单线程的,省去了很多上下文切换线程的时间;
3.redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现 的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝 不在io上浪费一点时间。
# 1.官方答案
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络 带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
# 2.性能指标
关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
# 3.详细原因
1**)不需要各种锁的性能消耗**
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很 细粒度的操作,比如在很⻓的列表后面添加一个元素,在hash当中添加或者删除一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。
总之,在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2**)单线程多进程集群方案**
单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
所以单线程、多进程的集群不失为一个时髦的解决方案。
3**)CPU消耗**
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU。 但是如果CPU成为Redis瓶颈,或者不想让服务器其他CUP核闲置,那怎么办?
可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客 户端分清哪些key放在哪个Redis进程上就可以了。
# Redis单线程的优劣势
# 1.单进程单线程优势
- 代码更清晰,处理逻辑更简单
- 不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
- 不存在多进程或者多线程导致的切换而消耗CPU
# 2.单进程单线程弊端
- 无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善;
# IO多路复用技术
redis 采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll, epoll。epoll是最新的也是目前最好的多路复用技术。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操 作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的 吞吐量。
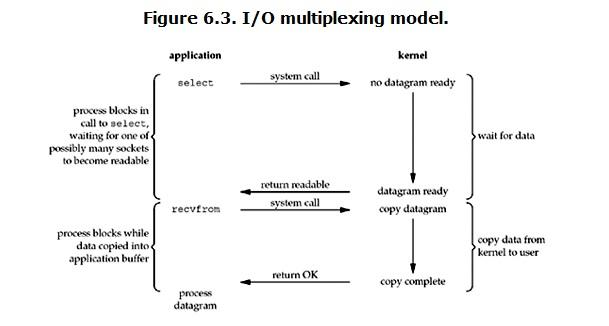
# Redis高并发快总结
Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
再说一下IO,Redis使用的是非阻塞IO,IO多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
另外,数据结构也帮了不少忙,Redis全程使用hash结构,读取速度快,还有一些特殊的数据结 构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结 构加快读取的速度。
还有一点,Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能 力比较大。
# 扩展内容
- Redis缓存和MySQL数据一致性的解决方案
- Redis哨兵、复制、集群的设计原理及区别
- 如何解决Redis缓存雪崩、缓存穿透、缓存并发等难题
- Redis的内存回收原理,及Redis内存过期淘汰策略
- Redis并发竞争key的解决方案
# 8 Redis哨兵、复制、集群的设计原理,以及区 别
# 题目描述
Redis哨兵、复制、集群的设计原理,以及区别?
# 面试题分析
谈到Redis服务器的高可用,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制。
- **哨兵(Sentinel)😗*可以管理多个Redis服务器,它提供了监控,提醒以及自动的故障转移的功能。
- 复制(Replication):则是负责让一个Redis服务器可以配备多个备份的服务器。
Redis正是利用这两个功能来保证Redis的高可用。
# 哨兵(sentinal)
哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要人
为干预的问题。
# 1.Redis哨兵主要功能
(1)集群监控:负责监控Redis master和slave进程是否正常工作
(2)消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
(3)故障转移:如果master node挂掉了,会自动转移到slave node上
(4)配置中心:如果故障转移发生了,通知client客户端新的master地址
# 2.Redis哨兵的高可用
原理:当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可
用性。
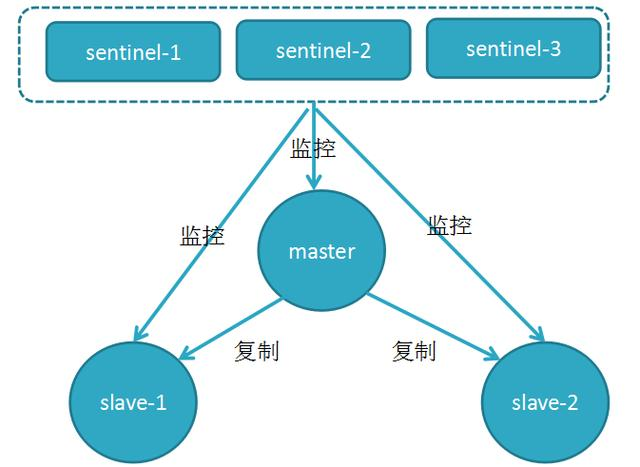
哨兵机制建立了多个哨兵节点(进程),共同监控数据节点的运行状况。
同时哨兵节点之间也互相通信,交换对主从节点的监控状况。
每隔1秒每个哨兵会向整个集群:Master主服务器+Slave从服务器+其他Sentinel(哨兵)进程,发送一次ping命令做一次心跳检测。
这个就是哨兵用来判断节点是否正常的重要依据,涉及两个新的概念**:主观下线和客观下线。**
**1.主观下线:**一个哨兵节点判定主节点down掉是主观下线。
**2.客观下线:**只有半数哨兵节点都主观判定主节点down掉,此时多个哨兵节点交换主观判定结果,才会判定主节点客观下线。
**3.原理:**基本上哪个哨兵节点最先判断出这个主节点客观下线,就会在各个哨兵节点中发起投票机制Raft算法(选举算法),最终被投为领导者的哨兵节点完成主从自动化切换的过程。
# 3.Redis复制(Replication)
Redis为了解决单点数据库问题,会把数据复制多个副本部署到其他节点上,通过复制,实现Redis的高可用性,实现对数据的冗余备份,保证数据和服务的高度可靠性。
# 数据复制原理(执行步骤)
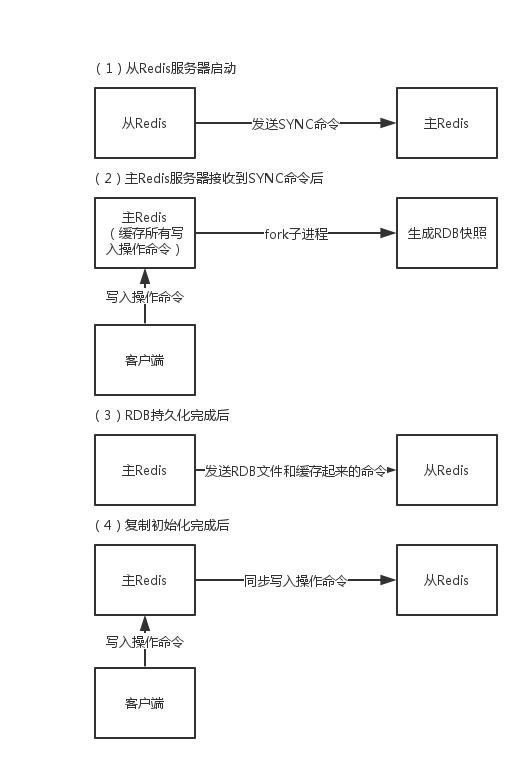
①从数据库向主数据库发送sync(数据同步)命令。
②主数据库接收同步命令后,会保存快照,创建一个RDB文件。
③当主数据库执行完保持快照后,会向从数据库发送RDB文件,而从数据库会接收并载入该文件。
④主数据库将缓冲区的所有写命令发给从服务器执行。
⑤以上处理完之后,之后主数据库每执行一个写命令,都会将被执行的写命令发送给从数据库。
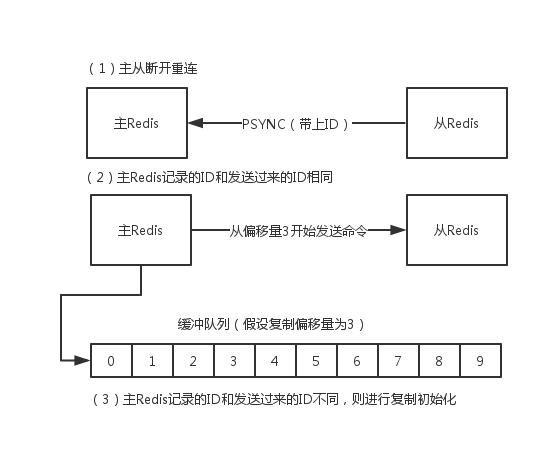
注意:在Redis2.8之后,主从断开重连后会根据断开之前最新的命令偏移量进行增量复制。
# 4.Redis主从复制、哨兵和集群这三个有什么区别
1.主从模式:读写分离,备份,一个Master可以有多个Slaves。
2.哨兵sentinel:监控,自动转移,哨兵发现主服务器挂了后,就会从slave中重新选举一个主服务器。
3.集群:为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。
