 数据结构与算法
数据结构与算法
# 如何衡量程序运行的效率?
咱们这个目标是想教会你利用数据结构的知识,建立算法思维,并完成代码效率的优化。为了达到这个目标,在第一节课,我们先来讲一讲如何衡量程序运行的效率。
当你在大数据环境中开发代码时,你一定遇到过程序执行好几个小时、甚至好几天的情况,或者是执行过程中电脑几乎死机的情况:
如果这个效率低下的系统是离线的,那么它会让我们的开发周期、测试周期变得很长。
如果这个效率低下的系统是在线的,那么它随时具有时间爆炸或者内存爆炸的可能性。
2
3
因此,衡量代码的运行效率对于一个工程师而言,是一项非常重要的基本功。本课时我们就来学习程序运行效率相关的度量方法。
# 复杂度是什么
复杂度是衡量代码运行效率的重要的度量因素。在介绍复杂度之前,有必要先看一下复杂度和计算机实际任务处理效率的关系,从而了解降低复杂度的必要性。
计算机通过一个个程序去执行计算任务,也就是对输入数据进行加工处理,并最终得到结果的过程。每个程序都是由代码构成的。可见,编写代码的核心就是要完成计算。但对于同一个计算任务,不同计算方法得到结果的过程复杂程度是不一样的,这对你实际的任务处理效率就有了非常大的影响。
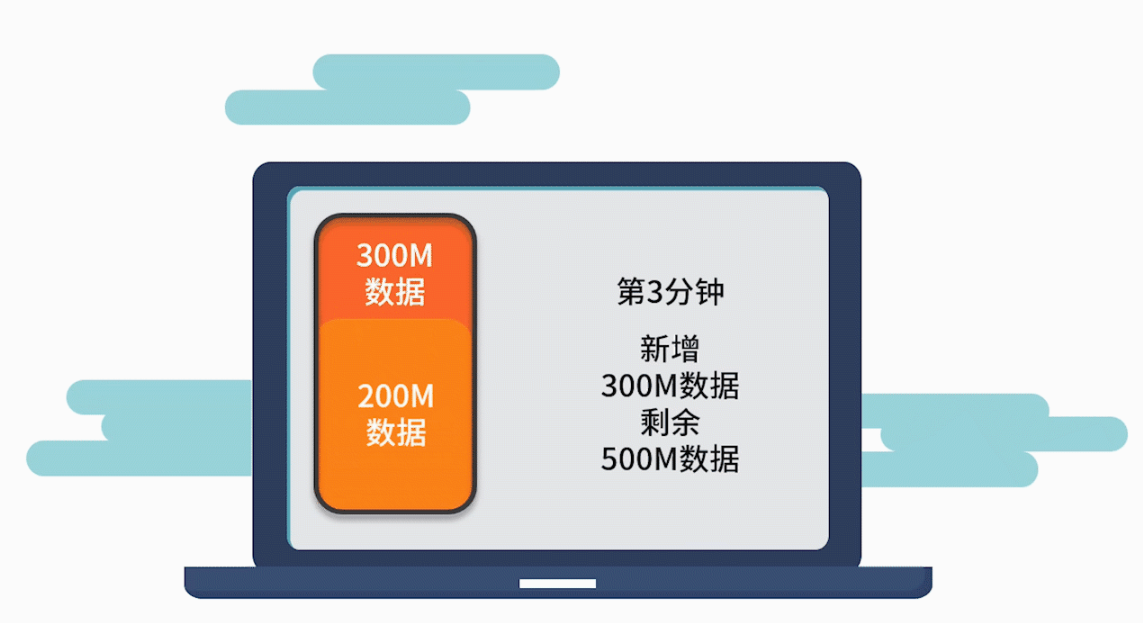
举个例子,你要在一个在线系统中实时处理数据。假设这个系统平均每分钟会新增 300M 的数据量。如果你的代码不能在 1 分钟内完成对这 300M 数据的处理,那么这个系统就会发生时间爆炸和空间爆炸。
表现就是,电脑执行越来越慢,直到死机。因此,我们需要讲究合理的计算方法,去通过尽可能低复杂程度的代码完成计算任务。
那提到降低复杂度,我们首先需要知道怎么衡量复杂度。而在实际衡量时,我们通常会围绕以下2 个维度进行。首先,这段代码消耗的资源是什么。一般而言,代码执行过程中会消耗计算时间和计算空间,那需要衡量的就是时间复杂度和空间复杂度。
我举一个实际生活中的例子。某个十字路口没有建立立交桥时,所有车辆通过红绿灯分批次行驶通过。
当大量汽车同时过路口的时候,就会分别消耗大家的时间。但建了立交桥之后,所有车辆都可以同时通过了,因为立交桥的存在,等于是消耗了空间资源,来换取了时间资源。

其次,这段代码对于资源的消耗是多少。我们不会关注这段代码对于资源消耗的绝对量,因为不管是时间还是空间,它们的消耗程度都与输入的数据量高度相关,输入数据少时消耗自然就少。为了更客观地衡量消耗程度,我们通常会关注时间或者空间消耗量与输入数据量之间的关系。
好,现在我们已经了解了衡量复杂度的两个纬度,那应该如何去计算复杂度呢?
复杂度是一个关于输入数据量 n 的函数。假设你的代码复杂度是 f(n),那么就用个大写字母 O 和括号,把 f(n) 括起来就可以了,即 O(f(n))。例如,O(n) 表示的是,复杂度与计算实例的个数 n 线性相关;
O(logn) 表示的是,复杂度与计算实例的个数 n 对数相关。
通常,复杂度的计算方法遵循以下几个原则:
首先,复杂度与具体的常系数无关,例如 O(n) 和 O(2n) 表示的是同样的复杂度。我们详细分析下,O(2n) 等于 O(n+n),也等于 O(n) + O(n)。也就是说,一段 O(n) 复杂度的代码只是先后执行两遍O(n),其复杂度是一致的。
其次,多项式级的复杂度相加的时候,选择高者作为结果,例如 O(n²)+O(n) 和 O(n²) 表示的是同样的复杂度。具体分析一下就是,O(n²)+O(n) = O(n²+n)。随着 n 越来越大,二阶多项式的变化率是要比一阶多项式更大的。因此,只需要通过更大变化率的二阶多项式来表征复杂度就可以了。
值得一提的是,O(1) 也是表示一个特殊复杂度,含义为某个任务通过有限可数的资源即可完成。此处有限可数的具体意义是,与输入数据量 n 无关。
例如,你的代码处理 10 条数据需要消耗 5 个单位的时间资源,3 个单位的空间资源。处理 1000 条数据,还是只需要消耗 5 个单位的时间资源,3 个单位的空间资源。那么就能发现资源消耗与输入数据量无关,就是 O(1) 的复杂度。
为了方便你理解不同计算方法对复杂度的影响,我们来看一个代码任务:对于输入的数组,输出与之逆序的数组。例如,输入 a=[1,2,3,4,5],输出 [5,4,3,2,1]。
先看方法一,建立并初始化数组 b,得到一个与输入数组等长的全零数组。通过一个 for 循环,从左到右将 a 数组的元素,从右到左地赋值到 b 数组中,最后输出数组 b 得到结果。
代码如下:
public void s1_1() {
int a[] = {
1,
2,
3,
4,
5
};
int b[] = new int[5];
for(int i = 0; i < a.length; i++) {
b[i] = a[i];
}
for(int i = 0; i < a.length; i++) {
b[a.length - i - 1] = a[i];
}
System.out.println(Arrays.toString(b));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这段代码的输入数据是 a,数据量就等于数组 a 的长度。代码中有两个 for 循环,作用分别是给b 数组初始化和赋值,其执行次数都与输入数据量相等。因此,代码的时间复杂度就是 O(n)+O(n),也就是O(n)。
空间方面主要体现在计算过程中,对于存储资源的消耗情况。上面这段代码中,我们定义了一个新的数组 b,它与输入数组 a 的长度相等。因此,空间复杂度就是 O(n)。
接着我们看一下第二种编码方法,它定义了缓存变量 tmp,接着通过一个 for 循环,从 0 遍历到a 数组长度的一半(即 len(a)/2)。每次遍历执行的是什么内容?就是交换首尾对应的元素。最后打印数组
a,得到结果。

代码如下:
public void s1_2() {
int a[] = {
1,
2,
3,
4,
5
};
int tmp = 0;
for(int i = 0; i < (a.length / 2); i++) {
tmp = a[i];
a[i] = a[a.length - i - 1];
a[a.length - i - 1] = tmp;
}
System.out.println(Arrays.toString(a));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这段代码包含了一个 for 循环,执行的次数是数组长度的一半,时间复杂度变成了 O(n/2)。根据复杂度与具体的常系数无关的性质,这段代码的时间复杂度也就是 O(n)。
空间方面,我们定义了一个 tmp 变量,它与数组长度无关。也就是说,输入是 5 个元素的数组,需要一个 tmp 变量;输入是 50 个元素的数组,依然只需要一个 tmp 变量。因此,空间复杂度与输入数组长度无关,即 O(1)。
可见,对于同一个问题,采用不同的编码方法,对时间和空间的消耗是有可能不一样的。因此,工程师在写代码的时候,一方面要完成任务目标;另一方面,也需要考虑时间复杂度和空间复杂度,以求用尽可能少的时间损耗和尽可能少的空间损耗去完成任务。
# 时间复杂度与代码结构的关系
好了,通过前面的内容,相信你已经对时间复杂度和空间复杂度有了很好的理解。从本质来看,时间复杂度与代码的结构有着非常紧密的关系;而空间复杂度与数据结构的设计有关,关于这一点我们会在下一讲进行详细阐述。接下来我先来系统地讲一下时间复杂度和代码结构的关系。
代码的时间复杂度,与代码的结构有非常强的关系,我们一起来看一些具体的例子。
例 1,定义了一个数组 a = [1, 4, 3],查找数组 a 中的最大值,代码如下:
public void s1_3() {
int a[] = {
1,
4,
3
};
int max_val = -1;
for(int i = 0; i < a.length; i++) {
if(a[i] > max_val) {
max_val = a[i];
}
}
System.out.println(max_val);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这个例子比较简单,实现方法就是,暂存当前最大值并把所有元素遍历一遍即可。因为代码的结构上需要使用一个 for 循环,对数组所有元素处理一遍,所以时间复杂度为 O(n)。
例2,下面的代码定义了一个数组 a = [1, 3, 4, 3, 4, 1, 3],并会在这个数组中查找出现次数最多的那个数字:
public void s1_4() {
int a[] = {
1,
3,
4,
3,
4,
1,
3
};
int val_max = -1;
int time_max = 0;
int time_tmp = 0;
for(int i = 0; i < a.length; i++) {
time_tmp = 0;
for(int j = 0; j < a.length; j++) {
if(a[i] == a[j]) {
time_tmp += 1;
}
if(time_tmp > time_max) {
time_max = time_tmp;
val_max = a[i];
}
}
}
System.out.println(val_max);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
这段代码中,我们采用了双层循环的方式计算:第一层循环,我们对数组中的每个元素进行遍历;第二层循环,对于每个元素计算出现的次数,并且通过当前元素次数 time_tmp 和全局最大次数变量time_max 的大小关系,持续保存出现次数最多的那个元素及其出现次数。由于是双层循环,这段代码在时间方面的消耗就是 n*n 的复杂度,也就是 O(n²)。
在这里,我们给出一些经验性的结论:
一个顺序结构的代码,时间复杂度是 O(1)。
二分查找,或者更通用地说是采用分而治之的二分策略,时间复杂度都是 O(logn)。这个我们会在后续课程讲到。
一个简单的 for 循环,时间复杂度是 O(n)。
两个顺序执行的 for 循环,时间复杂度是 O(n)+O(n)=O(2n),其实也是 O(n)。
两个嵌套的 for 循环,时间复杂度是 O(n²)。
有了这些基本的结论,再去分析代码的时间复杂度将会轻而易举。
降低时间复杂度的必要性
很多新手的工程师,对降低时间复杂度并没有那么强的意识。这主要是在学校或者实验室中,参加的课程作业或者科研项目,普遍都不是实时的、在线的工程环境。
实际的在线环境中,用户的访问请求可以看作一个流式数据。假设这个数据流中,每个访问的平均时间间隔是 t。如果你的代码无法在 t 时间内处理完单次的访问请求,那么这个系统就会一波未平一波又起,最终被大量积压的任务给压垮。这就要求工程师必须通过优化代码、优化数据结构,来降低时间复杂度。
为了更好理解,我们来看一些数据。假设某个计算任务需要处理 10万 条数据。你编写的代码:
如果是 O(n²) 的时间复杂度,那么计算的次数就大概是 100 亿次左右。
如果是 O(n),那么计算的次数就是 10万 次左右。
如果这个工程师再厉害一些,能在 O(log n) 的复杂度下完成任务,那么计算的次数就是 17 次左右(log100000 = 16.61,计算机通常是二分法,这里的对数可以以 2 为底去估计)。
数字是不是一下子变得很悬殊?通常在小数据集上,时间复杂度的降低在绝对处理时间上没有太多体现。但在当今的大数据环境下,时间复杂度的优化将会带来巨大的系统收益。而这是优秀工程师必须具备的工程开发基本意识。
# 总结
OK,今天的内容到这儿就结束了。相信你对复杂度的概念有了进一步的认识。
复杂度通常包括时间复杂度和空间复杂度。在具体计算复杂度时需要注意以下几点。
它与具体的常系数无关,O(n) 和 O(2n) 表示的是同样的复杂度。
复杂度相加的时候,选择高者作为结果,也就是说 O(n²)+O(n) 和 O(n²) 表示的是同样的复杂度。
O(1) 也是表示一个特殊复杂度,即任务与算例个数 n 无关。
复杂度细分为时间复杂度和空间复杂度,其中时间复杂度与代码的结构设计高度相关;空间复杂度与代码中数据结构的选择高度相关。会计算一段代码的时间复杂度和空间复杂度,是工程师的基本功。这项技能你在实际工作中一定会用到,甚至在参加互联网公司面试的时候,也是面试中的必考内容。
# 八皇后问题(N皇后问题)
# 题目描述
八皇后问题是在一个 8*8 的棋盘上放置皇后,要求其放置后满足同一行,同一列,同一对角线上没有重复的皇后出现。试问有多少种摆盘方式?
# 解题思路
我们的主要思路是通过一行一行的放置皇后,来使得每一行都有一个皇后。当然,这些皇后在放置时都必须要满足规定的要求才行。
因此就会出先如下情况:
放置时不符合规则,继续检索同一行的下一列位置是否合理
如果符合规则就将其放置,然后进行下一行的尝试(递归)
如果有某一行没有可行的解,则退回上一行,消除上一行摆放的皇后,检索剩余的列,看是否有合理的位置,然后继续进行。(回溯)
直到所有的行都被放置为止。
# 注意的情况
需要注意的是,我们在放置皇后时需要检测其防止和理性的判断条件为:
- 同一列的上方所有行中是否有皇后
- 左上方对角线上是否有皇后
- 右上方对角线上是否有皇后
# 算法实现(java)
public class EightQueen {
private static final int num = 8; // 可以拓展为N皇后问题
private static int[][] item = new int[num][num];
private static int methods = 0; // 总方法数
public static void main(String[] args) {
buildQueen(0);
System.out.println(methods);
}
/**
* 构建棋盘的第row行
*
* @param row
*/
private static void buildQueen(int row) {
if(row == num) {
methods++;
return;
} else {
for(int col = 0; col < num; col++) { // 每一列进行检查,试探性放置
if(isSatisfy(row, col)) {
item[row][col] = 1;
buildQueen(row + 1);
item[row][col] = 0;
}
}
}
}
/**
* 检查row行col列元素是否满足要求
* 因为是一行行的放置皇后,所以不需要检测同一行是否存在重复皇后
* 在判断重复元素时,只需要判断上半部分的区域即可
*
* @param row
* @param col
* @return
*/
private static boolean isSatisfy(int row, int col) {
for(int i = 0; i < row; i++) {
if(item[i][col] == 1) { // 同一列的上方元素
return false;
}
}
for(int i = row, j = col; i >= 0 && j >= 0; i--, j--) { // 左上方斜对角线
if(item[i][j] == 1) {
return false;
}
}
for(int i = row, j = col; i >= 0 && j < num; i--, j++) { // 右上方斜对角线
if(item[i][j] == 1) {
return false;
}
}
return true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# 优雅的位运算解法
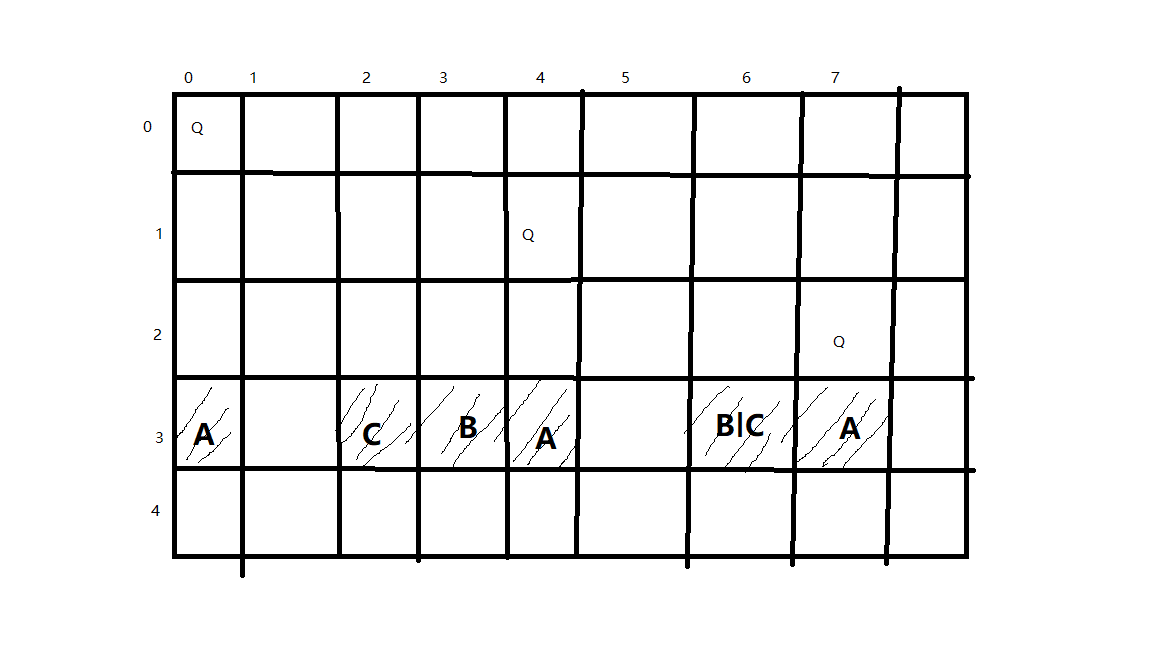
我们可以看到,前三行已经放置了皇后Q,我们需要在第四行选择放置皇后的点。阴影部分表示会出现冲突的格子,而冲突我们主要分为三种:同列冲突、右下方冲突和左下方冲突。
而就这对这种情况而言(此例为八皇后问题,可拓展到N皇后),一行刚好8个格子,对应8位二进制数字。因此我们可以首先定义冲突:
同列冲突: A = 1000 1001;
右下冲突: B = 0001 0010;
左下冲突: C = 0010 0010;
其中1表示冲突的格子,0表示可以放置皇后的格子。因此我们可以轻松得出综合的冲突情况:
D = (A | B | C) = 1011 1011;
对于我们将要放置的第四行而言,现在有两个0,意味着有两个可以放置皇后的位置,我们需要将所有的情况都考虑到,这里有一个神奇的式子:bit = (D + 1) & ~D; 它计算得出的结果是: 0000 0100;
其实它能够得到最右边一个可以放置皇后的位置,并用1来表示,其余位是0。 这样做是有好处的…
我们现在得出bit = 0000 0100,便能够轻松得到下一行的冲突A’ = (A | bit); B’ = (B | bit) >> 1; C’ = (C| bit) << 1;便能够很轻易地写出递归式了。
而我们的第4行试探其实并没有结束,只是从左向右的第一个可以放置的位置进行了试探,那想要取到第二个可以放置的位置怎么办呢?很简单,只需要做如下运算:
D = D + bit 将刚才试过的那一位设置为不能放置皇后状态,然后继续做 bit = (D + 1) & ~D 即可。
一直循环的试探,知道D 全部为1 为止。
下面是整个程序的代码:
public class NQueen {
private static final int N = 8; // 皇后数量,可拓展为N皇后
private static int count = 0; // 总方法数
private static int limit;
public static void main(String[] args) {
limit = (1 << N) - 1;
backtracking(0, 0, 0, 0);
System.out.println(count);
}
private static void backtracking(int a, int b, int c, int depth) {
if(depth == N) {
count++;
return;
}
int d = a | b | c;
while(d < limit) {
int bit = (d + 1) & ~d;
backtracking(a | bit, limit & ((b | bit) >> 1), limit & ((c | bit) << 1), depth + 1);
d |= bit;
}
}
} ** C 语言实现 ** \#include<stdio.h>
\#define line 8
void queen(int i, int j);
int check(int i, int j);
int chess[line][line];
int cas = 0;
int xx, yy;
int main() {
queen(0, 0);
printf("%d\n", cas);
return 0;
}
void queen(int i, int j) {
if(j >= line) {
return;
}
if(check(i, j) == 1) { //如果能放
chess[i][j] = 1; //放皇后
if(i == line - 1) { //如果是最后一行,记录情况
cas++;
/*下面是输出每种棋盘结果,供测试
for (xx=0;xx<8;xx++)
for(yy=0;yy<8;yy++){
printf("%d",chess[xx][yy]);
if(yy==7)
printf("\n");
}
printf("\n");
上面是输出结果*/
} else {
queen(i + 1, 0); //不是最后一行就分析下一行
}
}
chess[i][j] = 0; //如果此位置不能放,就置空(0),判断旁边的格子。
//如果此位置能放,走到这里就意味着上面的代码全部执行了,把皇后拿走(置零),再讨论其他情况,拿旁边位置试探。
queen(i, j + 1);
}
int check(int i, int j) {
int k;
for(k = 0; k < line; k++) {
if(chess[i][k] == 1) return 0; //0=不能放
}
for(k = 0; k < line; k++) {
if(chess[k][j] == 1) return 0;
}
for(k = -line; k <= line; k++) { //两对角线
if(i + k >= 0 && i + k < line && j + k >= 0 && j + k < line) //从左上到右下对角线
if(chess[i + k][j + k] == 1) return 0;
if(i - k >= 0 && i - k < line && j + k >= 0 && j + k < line) //从左下到右上对角线
if(chess[i - k][j + k] == 1) return 0;
}
return 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# 快速排序算法
# 题⽬描述
描述⼀下快速排序算法。
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:快速排序算法原理、伪代码实现⽅式,时间复杂度,如何避免最坏情况
# 快速排序算法原理
快速排序的核⼼思想是:分治思想。
简单⽽⾔,⽐较排序算法是对两个元素进⾏⽐较来决定两个元素的在输出序列中相对位置(谁在前⾯谁在后⾯)的排序算法。
快速排序的主旨很简单:找⼀个标杆数,称为X,然后根据X把数组的数分堆,⼩于X的全放左边,⼤于X的全放右边,就可以啦。对于实际情况呢,我们还需要考虑等于X**的情况,我将其与⼩于归为⼀起,即
数组排列后,形成“⼩于等于X” + “⼤于X”两部分。
就是说,快速排序的主要步骤就是:找X + 跟X⽐⼤⼩排列?
你可能会疑惑,只是按“⽐X⼤或⽐X⼩”排列数组,怎么能得到完整的排序呢。⼀次排列⼏乎不可能排好,但我们可以将排了⼀次的数组上,切分为“⼩于等于X”和“⼤于X”两块,再对这两块分别再找标杆数X'和X'',接着再分别排序。最后组合再⼀起,就得到了排列了两次的数组,其顺序肯定更接近完美序列。那么我们继续这么“切分→找标杆数→排列”操作下去呢?在此例中,由于每⼀分堆总⼩于右侧的分堆,⽽⼤于左侧的分堆,同时每个分堆内部已排好序,因此整个序列排序完成。
以上这种操作叫做“递归”,可以对数组不断地切分并采⽤同样的排列模式进⾏排列,直到递归条件不再满⾜,则停⽌递归。在这⾥,我们选择切分后数组的⻓度⼤⼩,作为递归的条件。
# 伪代码实现⽅式
public < T extends Comparable < T >> T[] sort(T[] array) {
doSort(array, 0, array.length - 1);
return array;
}
private static < T extends Comparable < T >> void doSort(T[] array, int left, int right) {
if(left < right) {
int pivot = randomPartition(array, left, right);
doSort(array, left, pivot - 1);
doSort(array, pivot, right);
}
}
private static < T extends Comparable < T >> int randomPartition(T[] array, int left, int right) {
int randomIndex = left + (int)(Math.random() * (double)(right - left + 1));
SortUtils.swap(array, randomIndex, right);
return partition(array, left, right);
}
private static < T extends Comparable < T >> int partition(T[] array, int left, int right) {
int mid = (left + right) / 2;
Comparable pivot = array[mid];
while(left <= right) {
while(SortUtils.less(array[left], pivot)) {
++left;
}
while(SortUtils.less(pivot, array[right])) {
--right;
}
if(left <= right) {
SortUtils.swap(array, left, right);
++left;
--right;
}
}
return left;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 常⻅的⽐较排序算法
冒泡排序(Bubble Sort)时间复杂度和空间复杂度为 。
插⼊排序(Insertion Sort) 时间复杂度下界,上界以及空间复杂度为。
归并排序(Merge Sort)时间复杂度和空间复杂度为 。可
⻅虽然归并排序的时间复杂度符合理论最⼩值,但它的空间复杂度也很⾼。更蛋疼的是归并排序的时间复杂度分析是建⽴在RAM模型(Random Access Memory)上,⽽实际的计算机内存模型并
不是RAM⽽是有cache的。因为归并排序算法在每次递归迭代过程中都会申请新的内存然后在新申请内存上进⾏操作。这不匹配于cache内存机制,所以归并排序算法在真实硬件上的表现不很理想。不过随着并⾏,分布式系统的兴起,这个算法⼜有了新的⽣机。它⾮常适合并⾏优化,并且已经有了相应分析和研究(如果这篇反响好我第⼆篇就写这个内容)。
# 时间复杂度,空间复杂度
时间复杂度为O(nlogn),空间复杂度为O(n)
# 如何避免最坏情况
- 采⽤三位中值法选择标杆数
- 采⽤随机数的⽅式选择标杆数
# 总结
充分理解快速排序算法的运⾏原理,可以形象的描述清楚。
快速排序可实现理论最优效率,这可能是快速排序⽐较重要的原因吧。
# 求中位数
# 题目描述
从 5 亿个数中找出中位数。
数据排序后,位置在最中间的数就是中位数。当样本数为奇数时,中位数为 第 (N+1)/2 个数;当样本数为偶数时,中位数为 第 N/2 个数与第 1+N/2 个数的均值。
# 解答思路
如果这道题没有内存大小限制,则可以把所有数读到内存中排序后找出中位数。但是最好的排序算法的时间复杂度都为 O(NlogN)。这里使用其他方法。
# 方法一:双堆法
维护两个堆,一个大顶堆,一个小顶堆。大顶堆中最大的数小于等于小顶堆中最小的数;保证这两个堆中的元素个数的差不超过 1。
若数据总数为偶数,当这两个堆建好之后,中位数就是这两个堆顶元素的平均值。当数据总数为奇数时,根据两个堆的大小,中位数一定在数据多的堆的堆顶。
class MedianFinder {
private PriorityQueue < Integer > maxHeap;
private PriorityQueue < Integer > minHeap;
/** initialize your data structure here. */
public MedianFinder() {
maxHeap = new PriorityQueue < > (Comparator.reverseOrder());
minHeap = new PriorityQueue < > (Integer::compareTo);
}
public void addNum(int num) {
if(maxHeap.isEmpty() || maxHeap.peek() > num) {
maxHeap.offer(num);
} else {
minHeap.offer(num);
}
int size1 = maxHeap.size();
int size2 = minHeap.size();
if(size1 - size2 > 1) {
minHeap.offer(maxHeap.poll());
} else if(size2 - size1 > 1) {
maxHeap.offer(minHeap.poll());
}
}
public double findMedian() {
int size1 = maxHeap.size();
int size2 = minHeap.size();
return size1 == size2 ? (maxHeap.peek() + minHeap.peek()) * 1.0 / 2 : (size1 > size2 ? maxHeap.peek() : minHeap.peek());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
以上这种方法,需要把所有数据都加载到内存中。当数据量很大时,就不能这样了,因此,这种方法适用于数据量较小的情况。5 亿个数,每个数字占用 4B,总共需要 2G 内存。如果可用内存不足 2G,就不能使用这种方法了,下面介绍另一种方法。
# 方法二:分治法
分治法的思想是把一个大的问题逐渐转换为规模较小的问题来求解。
对于这道题,顺序读取这 5 亿个数字,对于读取到的数字 num,如果它对应的二进制中最高位为,则把这个数字写到 f1 中,否则写入 f0 中。通过这一步,可以把这 5 亿个数划分为两部分,而且 f0 中的数都大于 f1 中的数(最高位是符号位)。
划分之后,可以非常容易地知道中位数是在 f0 还是 f1 中。假设 f1 中有 1 亿个数,那么中位数一定在f0 中,且是在 f0 中,从小到大排列的第 1.5 亿个数与它后面的一个数的平均值。
提示,5 亿数的中位数是第 2.5 亿与右边相邻一个数求平均值。若 f1 有一亿个数,那么中位数就是 f0 中从第 1.5 亿个数开始的两个数求得的平均值。
对于 f0 可以用次高位的二进制继续将文件一分为二,如此划分下去,直到划分后的文件可以被加载到内存中,把数据加载到内存中以后直接排序,找出中位数。
注意,当数据总数为偶数,如果划分后两个文件中的数据有相同个数,那么中位数就是数据较小的文件中的最大值与数据较大的文件中的最小值的平均值。
# 在 2.5 亿个整数中找出不重复的整数
# 题目描述
在 2.5 亿个整数中找出不重复的整数。注意:内存不足以容纳这 2.5 亿个整数。
# 解答思路
# 方法一:分治法
与前面的题目方法类似,先将 2.5 亿个数划分到多个小文件,用 HashSet/HashMap 找出每个小文件中不重复的整数,再合并每个子结果,即为最终结果。
# 方法二:位图法
位图,就是用一个或多个 bit 来标记某个元素对应的值,而键就是该元素。采用位作为单位来存储数据,可以大大节省存储空间。
位图通过使用位数组来表示某些元素是否存在。它可以用于快速查找,判重,排序等。不是很清楚?我先举个小例子。
假设我们要对 [0,7] 中的 5 个元素 (6, 4, 2, 1, 5) 进行排序,可以采用位图法。0~7 范围总共有 8 个数,只需要 8bit,即 1 个字节。首先将每个位都置 0:
0 0 0 0 0 0 0 0
然后遍历 5 个元素,首先遇到 6,那么将下标为 6 的位的 0 置为 1;接着遇到 4,把下标为 4 的位 的 0置为 1:
0 0 0 0 1 0 1 0
依次遍历,结束后,位数组是这样的:
0 1 1 0 1 1 1 0
每个为 1 的位,它的下标都表示了一个数:
for i in range(8): if bits[i] == 1: print(i)
这样我们其实就已经实现了排序。
对于整数相关的算法的求解,位图法是一种非常实用的算法。假设 int 整数占用 4B,即 32bit,那么我们可以表示的整数的个数为 232。
那么对于这道题,我们用 2 个 bit 来表示各个数字的状态:
•00 表示这个数字没出现过;•01 表示这个数字出现过一次(即为题目所找的不重复整数);•10 表示这个数字出现了多次。
那么这 232 个整数,总共所需内存为 232*2b=1GB。因此,当可用内存超过 1GB 时,可以采用位图法。假设内存满足位图法需求,进行下面的操作:
遍历 2.5 亿个整数,查看位图中对应的位,如果是 00,则变为 01,如果是 01 则变为 10,如果是 10则保持不变。遍历结束后,查看位图,把对应位是 01 的整数输出即可。
# 方法总结
判断数字是否重复的问题,位图法是一种非常高效的方法。
