 Spring与SpringBoot
Spring与SpringBoot
# springboot启动设置初始化数据
# 题目描述
面试中的问题:springboot如何在启动时设置初始化数据
# 案情回顾
在实际开发中,我们一般都会在配置文件(application.properties或者application.yml)中配置各个项目中集成的属性值,来进行各个组件的设置,比如配置端口:server.port=8080,但是在开发中我们需要配置业务得属性值来添加到springboot容器中,那么这个时候我们应该怎么办呢?
# 解决方案
# 实现ApplicationRunner接口
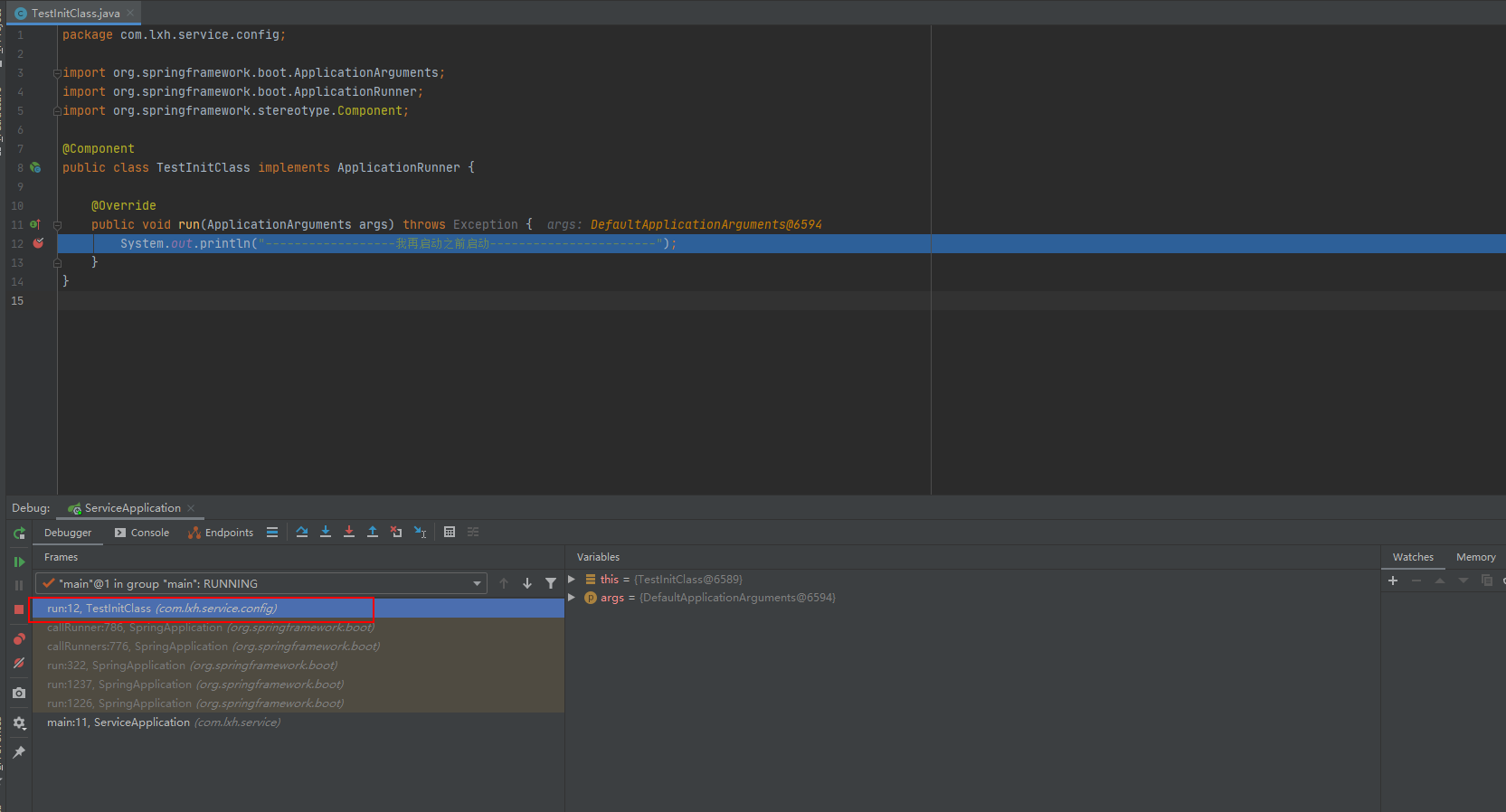
编写测试类
@Component
public class TestInitClass implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println("------------------我在启动之前加载了--------------------- --");
}
}
2
3
4
5
6
7
演示测试
# 实现 CommandLineRunner接口
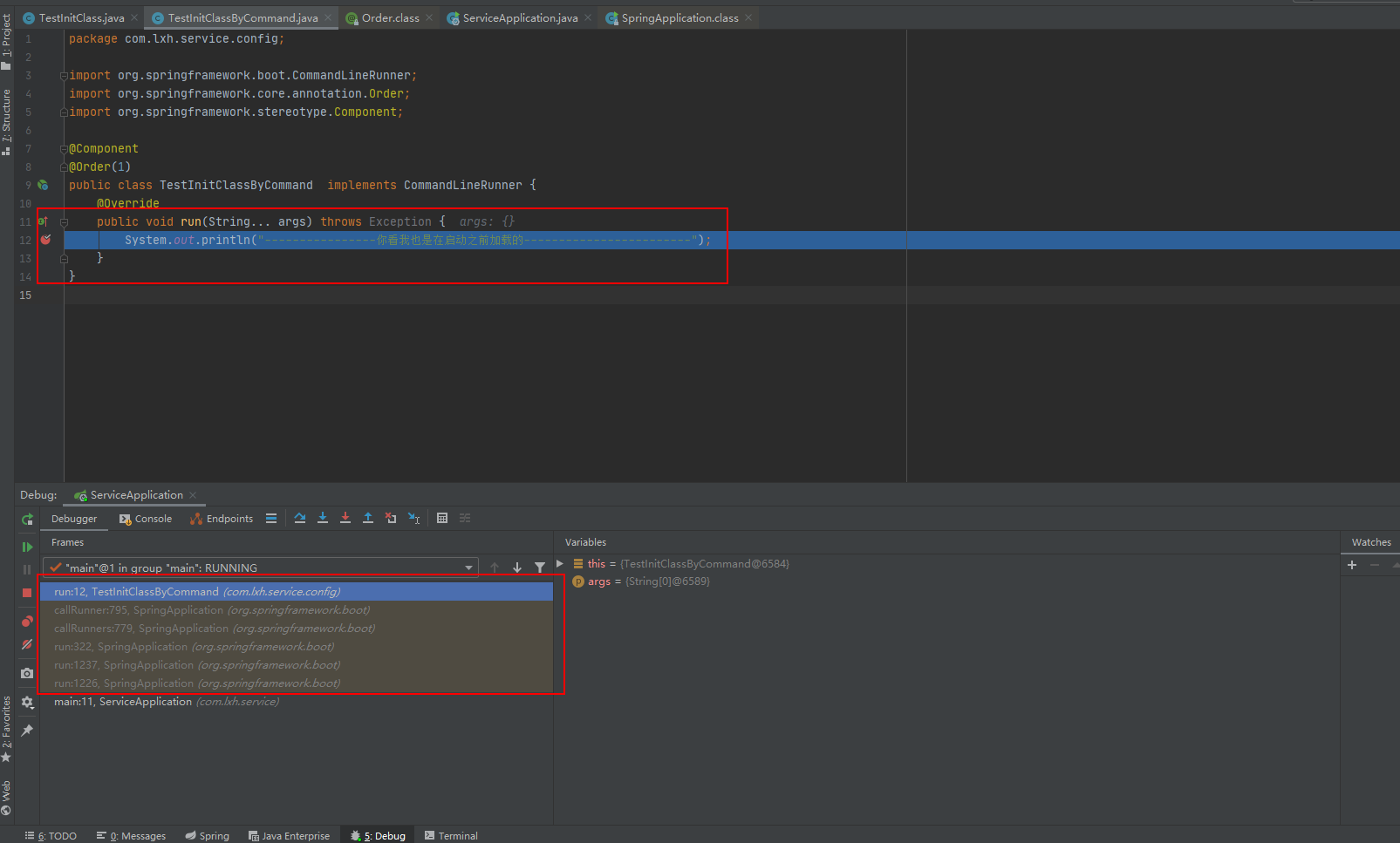
编写测试类
@Component
public class TestInitClassByCommand implements CommandLineRunner {
@Override
public void run(String...args) throws Exception {
System.out.println("----------------你看我也是在启动之前加载的---------------- -- -- -- --");
}
}
2
3
4
5
6
7
演示测试
# 优先级
默认情况下ApplicationRunner比CommandLineRunner 先执行
首先我们运行验证一下:
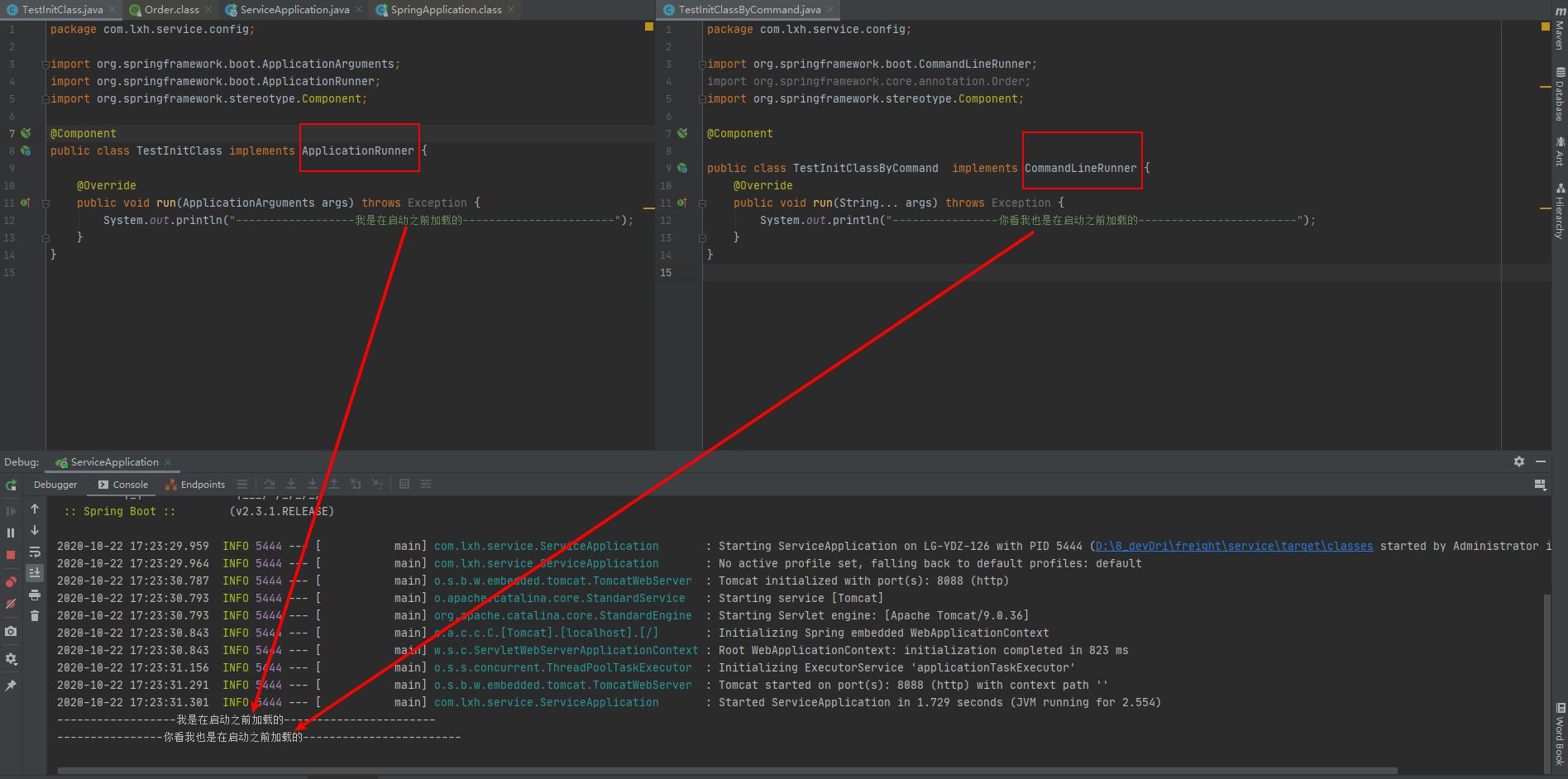
验证成功。
进行源码查看为什么会这样呢,我们在启动类中点击run()方法进入该方法的内容里面,该方法为springApplication类的方法,调用过程如下
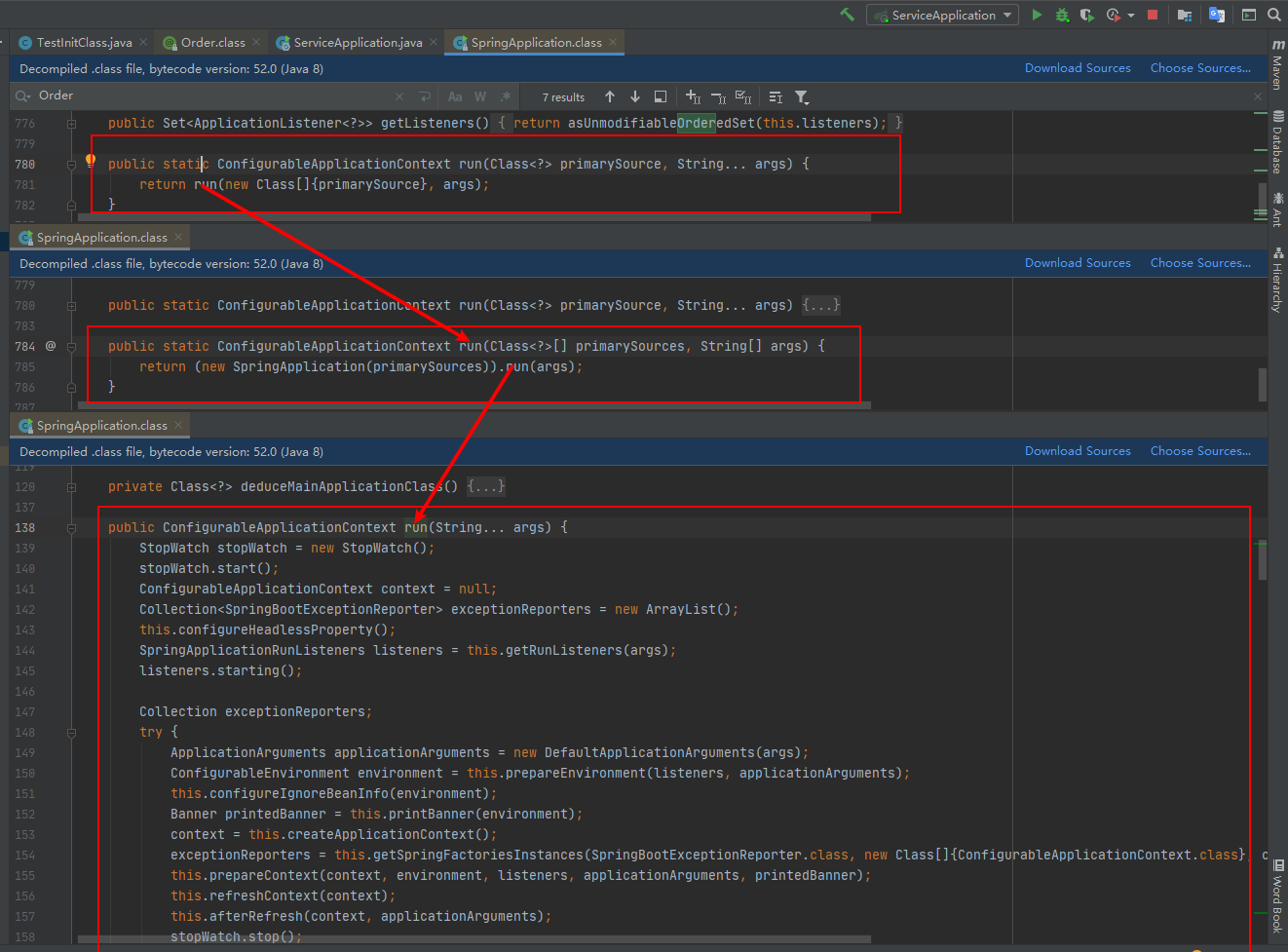
由此我们可以看到run()方法的执行,最终是走的138行的run方法。那么我们具体看下最后这个run方法
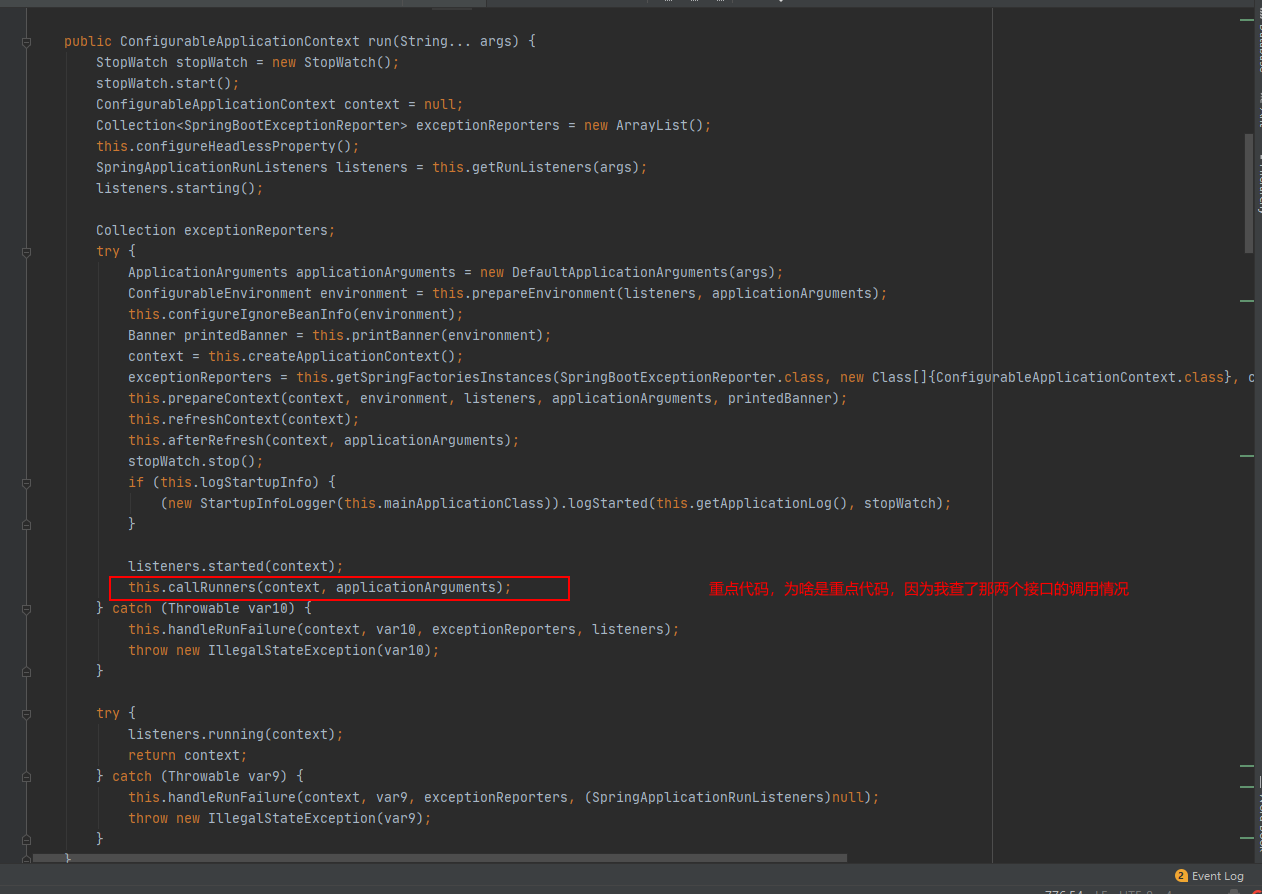
我们继续往下跟,查看该callRunners方法里具体的执行情况
private void callRunners(ApplicationContext context, ApplicationArguments args) {
List < Object > runners = new ArrayList();
//重点来了,看这个添加,这个添加是先添加 ApplicationRunner接口的类型再添加CommandLineRunner 接口的类型。
runners.addAll(context.getBeansOfType(ApplicationRunner.class).values());
runners.addAll(context.getBeansOfType(CommandLineRunner.class).values());
AnnotationAwareOrderComparator.sort(runners);
Iterator var4 = (new LinkedHashSet(runners)).iterator();
//循环时也是先进行了ApplicationRunner类型的判断和调用。
while(var4.hasNext()) {
Object runner = var4.next();
if(runner instanceof ApplicationRunner) {
this.callRunner((ApplicationRunner) runner, args);
}
if(runner instanceof CommandLineRunner) {
this.callRunner((CommandLineRunner) runner, args);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
所以,我们应该能明白,调用的顺序原因了。那么我们是否能够手动指定谁先加载,谁在加载呢,答案是肯定的。同样这个callRunners方法,里面有一句是这么写的
AnnotationAwareOrderComparator.sort(runners); 这个是说明我会先进行一下排序。那么怎么排序的呢
//AnnotationAwareOrderComparator.java sort方法
public static void sort(List < ? > list) {
if(list.size() > 1) {
list.sort(INSTANCE);
}
}
2
3
4
5
6
经过简单查看,发现他是走的list的排序。然后我们回来看注解类 Order
/**
*@Order定义了已注释组件的排序顺序。
*该value是可选的,并且表示为在定义的顺序值Ordered接口。 值越低,具有更高的优先级。 默认值是Ordered.LOWEST_PRECEDENCE ,
*表示最低优先级(输给任何其他指定顺序值)
* @author Rod Johnson
* @author Juergen Hoeller
* @since 2.0
* @see org.springframework.core.Ordered
* @see AnnotationAwareOrderComparator
* @see OrderUtils
* @see javax.annotation.Priority
*/
@Retention(RetentionPolicy.RUNTIME)
@Target({
ElementType.TYPE,
ElementType.METHOD,
ElementType.FIELD
})
@Documented
public @interface Order {
/**
* 排序值默认为Ordered类中的LOWEST_PRECEDENCE
* <p>Default is {@link Ordered#LOWEST_PRECEDENCE}.
* @see Ordered#getOrder()
*/
int value() default Ordered.LOWEST_PRECEDENCE;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
综上:我们可以知道当使用注解Order时给的参数值越小则有更好的优先级。
# 总结
所有CommandLineRunner/ApplicationRunner的执行时点是在SpringBoot应用的ApplicationContext完全初始化开始工作之后, callRunners() 可以看出是run方法内部最后一个调用的方法(可以认为是main方法执行完成之前最后一步)
只要存在于当前SpringBoot应用的ApplicationContext中的任何CommandLineRunner/ApplicationRunner,都会被加载执行(不管你是手动注册还是自动扫描去Ioc容器)
使用@Order注解可以设置加载的顺序
一般情况我们只需要使用一个接口来加载初始化数据即可
# Spring bean的生命周期
# 题目描述
讲一下 Spring bean的生命周期
# 题目解决
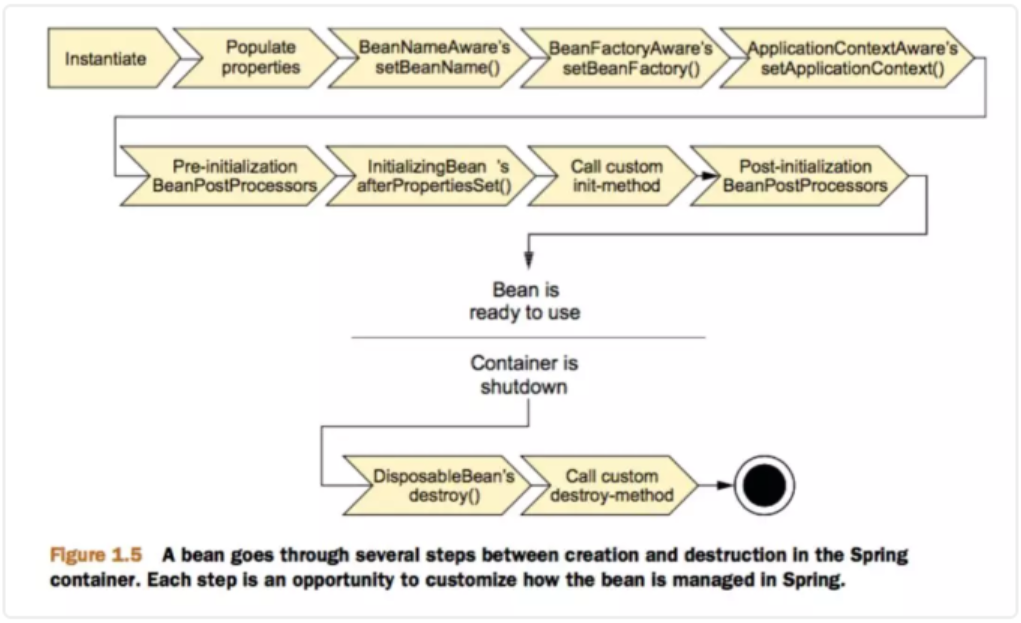
# 一、ApplicationContext Bean生命周期
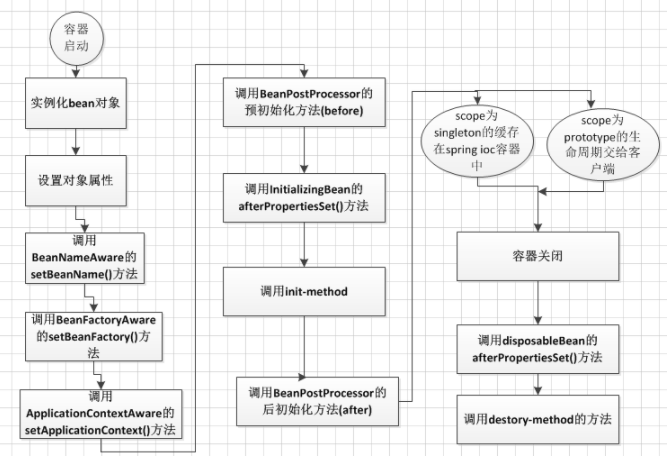
ApplicationContext容器中,Bean的生命周期流程如上图所示,流程大致如下:
1.首先容器启动后,会对scope为singleton且非懒加载的bean进行实例化,
2.按照Bean定义信息配置信息,注入所有的属性,
3.如果Bean实现了BeanNameAware接口,会回调该接口的setBeanName()方法,传入该Bean的id,此时该Bean就获得了自己在配置文件中的id,
4.如果Bean实现了BeanFactoryAware接口,会回调该接口的setBeanFactory()方法,传入该Bean的BeanFactory,这样该Bean就获得了自己所在的BeanFactory,
5.如果Bean实现了ApplicationContextAware接口,会回调该接口的setApplicationContext()方法,传入该Bean的ApplicationContext,这样该Bean就获得了自己所在的ApplicationContext,
6.如果有Bean实现了BeanPostProcessor接口,则会回调该接口的postProcessBeforeInitialzation()方法,
7.如果Bean实现了InitializingBean接口,则会回调该接口的afterPropertiesSet()方法,
8.如果Bean配置了init-method方法,则会执行init-method配置的方法,
9.如果有Bean实现了BeanPostProcessor接口,则会回调该接口的postProcessAfterInitialization()方法,
10.经过流程9之后,就可以正式使用该Bean了,对于scope为singleton的Bean,Spring的ioc容器中会缓存一份该bean的实例,而对于scope为prototype的Bean,每次被调用都会new一个新的对象,期生命周期就交给调用方管理了,不再是Spring容器进行管理了
11.容器关闭后,如果Bean实现了DisposableBean接口,则会回调该接口的destroy()方法,
12.如果Bean配置了destroy-method方法,则会执行destroy-method配置的方法,至此,整个Bean的生命周期结束
# 二、代码演示
我们定义了一个Person类,该类实现了BeanNameAware,BeanFactoryAware,ApplicationContextAware,InitializingBean,DisposableBean五个接口,并且在applicationContext.xml文件中配置了该Bean的id为person1,并且配置了init-method和destroy-method,为该Bean配置了属性name为jack的值,然后定义了一个MyBeanPostProcessor方法,该方法实现了BeanPostProcessor接口,且在applicationContext.xml文件中配置了该方法的Bean,其代码如下所示
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.2.xsd">
<bean id="person1" destroy-method="myDestroy"
init-method="myInit" class="com.test.spring.life.Person">
<property name="name">
<value>jack</value>
</property>
</bean>
<!-- 配置自定义的后置处理器 -->
<bean id="postProcessor" class="com.pingan.spring.life.MyBeanPostProcessor"/>
</beans>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class Person implements BeanNameAware, BeanFactoryAware, ApplicationContextAware, InitializingBean, DisposableBean
{
private String name;
public Person()
{
System.out.println("PersonService类构造方法");
}
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
System.out.println("set方法被调用");
}
//自定义的初始化函数
public void myInit()
{
System.out.println("myInit被调用");
}
//自定义的销毁方法
public void myDestroy()
{
System.out.println("myDestroy被调用");
}
public void destroy() throws Exception
{
// TODO Auto-generated method stub
System.out.println("destory被调用");
}
public void afterPropertiesSet() throws Exception
{
// TODO Auto-generated method stub
System.out.println("afterPropertiesSet被调用");
}
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException
{
// TODO Auto-generated method stub
System.out.println("setApplicationContext被调用");
}
public void setBeanFactory(BeanFactory beanFactory) throws BeansException
{
// TODO Auto-generated method stub
System.out.println("setBeanFactory被调用,beanFactory");
}
public void setBeanName(String beanName)
{
// TODO Auto-generated method stub
System.out.println("setBeanName被调用,beanName:" + beanName);
}
public String toString()
{
return "name is :" + name;
}
public class MyBeanPostProcessor implements BeanPostProcessor
{
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException
{
// TODO Auto-generated method stub
System.out.println("postProcessBeforeInitialization被调用");
return bean;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException
{
// TODO Auto-generated method stub
System.out.println("postProcessAfterInitialization被调用");
return bean;
}
}
public class AcPersonServiceTest
{
public static void main(String[] args)
{
// TODO Auto-generated method stub
System.out.println("开始初始化容器");
ApplicationContext ac = new
ClassPathXmlApplicationContext("com/test/spring/life/applicationContext.xml");
System.out.println("xml加载完毕");
Person person1 = (Person) ac.getBean("person1");
System.out.println(person1);
System.out.println("关闭容器");
((ClassPathXmlApplicationContext) ac).close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
我们启动容器,可以看到整个调用过程:
开始初始化容器
九月 25, 2016 10:44:50 下午
org.springframework.context.support.ClassPathXmlApplicationContext prepareRefresh
信息: Refreshing
org.springframework.context.support.ClassPathXmlApplicationContext@b4aa453:
startup date [Sun Sep 25 22:44:50 CST 2016]; root of context hierarchy
九月 25, 2016 10:44:50 下午
org.springframework.beans.factory.xml.XmlBeanDefinitionReader
loadBeanDefinitions
信息: Loading XML bean definitions from class path resource
[com/test/spring/life/applicationContext.xml]
Person类构造方法
set方法被调用
setBeanName被调用,beanName:person1
setBeanFactory被调用,beanFactory
setApplicationContext被调用
postProcessBeforeInitialization被调用
afterPropertiesSet被调用
myInit被调用
postProcessAfterInitialization被调用
xml加载完毕
name is :jack
关闭容器
九月 25, 2016 10:44:51 下午
org.springframework.context.support.ClassPathXmlApplicationContext doClose
信息: Closing
org.springframework.context.support.ClassPathXmlApplicationContext@b4aa453:
startup date [Sun Sep 25 22:44:50 CST 2016]; root of context hierarchy
destory被调用
myDestroy被调用
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 三、BeanFactory Bean生命周期
ApplicationContext会利用Java反射机制自动识别出配置文件中定义的
BeanPostProcesser,InstantiationAwareBeanPostProcessor和BeanFactoryPostProcessor,并自动将它们注册到应用上下文中。而BeanFactory需要手动addBeanPostProcessor()去进行注册。
流程
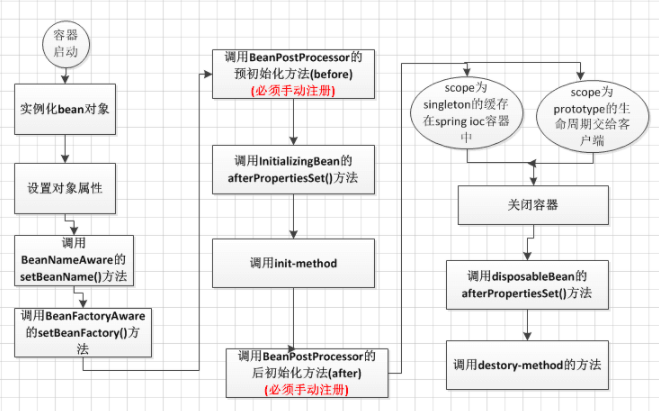
init-method 属性指定一个方法,在实例化 bean 时,立即调用该方法。同样,destroy-method 指定一个方法,只有从容器中移除 bean 之后,才能调用该方法。
# Spring循环依赖及解决方式
# 题目描述
什么是Spring循环依赖及解决方式
# 题目解决
# 1. 什么是循环依赖?
循环依赖其实就是循环引用,也就是两个或者两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图:
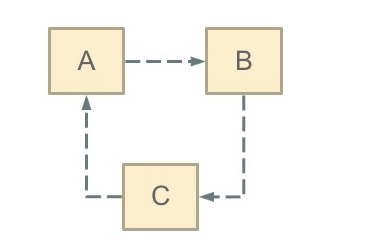
注意,这里不是函数的循环调用,是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。
Spring中循环依赖场景有:
(1)构造器的循环依赖
(2)field属性的循环依赖
其中,构造器的循环依赖问题无法解决,只能拋出BeanCurrentlyInCreationException异常,在解决属性循环依赖时,spring采用的是提前暴露对象的方法。
# 2.怎么检测是否存在循环依赖
检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。
# 3. Spring怎么解决循环依赖
Spring的循环依赖的理论依据基于Java的引用传递,当获得对象的引用时,对象的属性是可以延后设置的。(但是构造器必须是在获取引用之前)
Spring的单例对象的初始化主要分为三步:
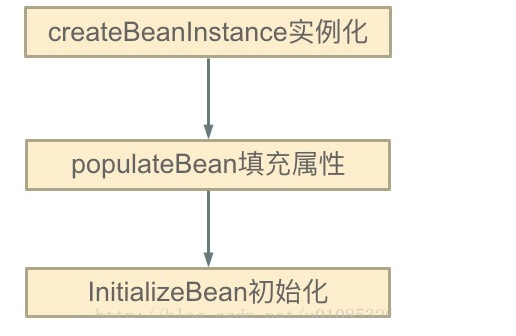
(1)createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
(2)populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
(3)initializeBean:调用spring xml中的init 方法。
从上面单例bean的初始化可以知道:循环依赖主要发生在第一、二步,也就是构造器循环依赖和field循环依赖。那么我们要解决循环引用也应该从初始化过程着手,对于单例来说,在Spring容器整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存。
这三级缓存分别指:
singletonFactories : 单例对象工厂的cache
earlySingletonObjects :提前暴光的单例对象的Cache
singletonObjects:单例对象的cache
在创建bean的时候,首先想到的是从cache中获取这个单例的bean,这个缓存就是singletonObjects。
如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取,如果获取到了则:从singletonFactories中移除,并放入earlySingletonObjects中。其实也就是从三级缓存移动到了二级缓存。
从上面三级缓存的分析,我们可以知道,Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory。这里就是解决循环依赖的关键,发生在createBeanInstance之后,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行初始化的第二步和第三步),但是已经能被人认出来了(根据对象引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来让大家认识,让大家使用。
这样做有什么好处呢?让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
知道了这个原理时候,肯定就知道为啥Spring不能解决“A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题了!因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
# 4.基于构造器的循环依赖
Spring容器会将每一个正在创建的Bean 标识符放在一个“当前创建Bean池”中,Bean标识符在创建过程中将一直保持在这个池中,因此如果在创建Bean过程中发现自己已经在“当前创建Bean池”里时将抛出BeanCurrentlyInCreationException异常表示循环依赖;而对于创建完毕的Bean将从“当前创建Bean池”中清除掉。
Spring容器先创建单例A,A依赖B,然后将A放在“当前创建Bean池”中,此时创建B,B依赖C ,然后将B放在“当前创建Bean池”中,此时创建C,C又依赖A, 但是,此时A已经在池中,所以会报错,,因为在池中的Bean都是未初始化完的,所以会依赖错误 ,(初始化完的Bean会从池中移除)
# 5.基于setter属性的循环依赖
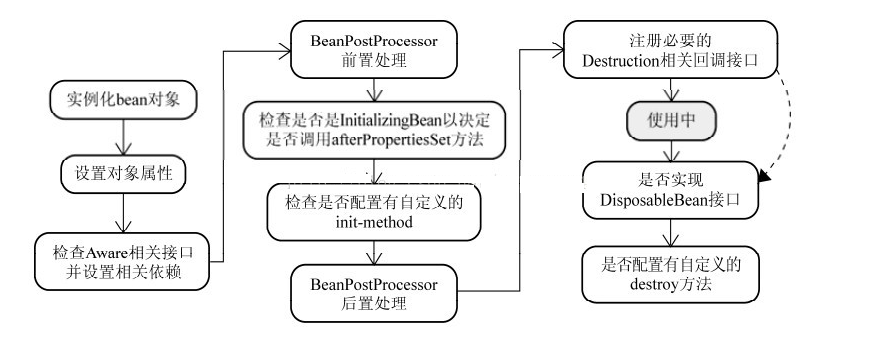
我们结合上面那张图看,Spring先是用构造实例化Bean对象 ,创建成功后,Spring会通过以下代码提前将对象暴露出来,此时的对象A还没有完成属性注入,属于早期对象,此时Spring会将这个实例化结束的对象放到一个Map中,并且Spring提供了获取这个未设置属性的实例化对象引用的方法。 结合我们的实例来看,当Spring实例化了A、B、C后,紧接着会去设置对象的属性,此时A依赖B,就会去Map中取出存在里面的单例B对象,以此类推,不会出来循环的问题喽
# 谈谈对Spring AOP的理解
# 题目描述
谈谈对Spring AOP的理解
# 面试题分析
将AOP的几个核心概念说出来,将AOP的实现方式说出来
# AOP
AOP(Aspect Oriented Programming),即面向切面编程,可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。OOP引入封装、继承、多态等概念来建立一种对象层次结构,用于模拟公共行为的一个集合。不过OOP允许开发者定义纵向的关系,但并不适合定义横向的关系,例如日志功能。日志代码往往横向地散布在所有对象层次中,而与它对应的对象的核心功能毫无关系对于其他类型的代码,如安全性、异常处理和透明的持续性也都是如此,这种散布在各处的无关的代码被称为横切(cross cutting),在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
AOP技术恰恰相反,它利用一种称为"横切"的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为"Aspect",即切面。所谓"切面",简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
使用"横切"技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处基本相似,比如权限认证、日志、事物。AOP的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
# AOP核心概念
1、横切关注点
对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点
2、切面(aspect)
类是对物体特征的抽象,切面就是对横切关注点的抽象
3、连接点(joinpoint)
被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器
4、切入点(pointcut)
对连接点进行拦截的定义
5、通知(advice)
所谓通知指的就是指拦截到连接点之后要执行的代码,通知分为前置、后置、异常、最终、环绕通知五类
6、目标对象
代理的目标对象
7、织入(weave)
将切面应用到目标对象并导致代理对象创建的过程
8、引入(introduction)
在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段
# Spring对AOP的支持
Spring中AOP代理由Spring的IOC容器负责生成、管理,其依赖关系也由IOC容器负责管理。因此,AOP代理可以直接使用容器中的其它bean实例作为目标,这种关系可由IOC容器的依赖注入提供。
Spring创建代理的规则为:
1、默认使用Java动态代理来创建AOP代理,这样就可以为任何接口实例创建代理了
2、当需要代理的类不是代理接口的时候,pring会切换为使用CGLIB代理,也可强制使用CGLIB
AOP编程其实是很简单的事情,纵观AOP编程,程序员只需要参与三个部分:
1、定义普通业务组件
2、定义切入点,一个切入点可能横切多个业务组件
3、定义增强处理,增强处理就是在AOP框架为普通业务组件织入的处理动作
所以进行AOP编程的关键就是定义切入点和定义增强处理,一旦定义了合适的切入点和增强处理,AOP框架将自动生成AOP代理,即:代理对象的方法=增强处理+被代理对象的方法。
下面给出一个Spring AOP的.xml文件模板,名字叫做aop.xml,之后的内容都在aop.xml上进行扩展:
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.2.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.2.xsd">
</beans>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 基于Spring的AOP简单实现
注意一下,在讲解之前,说明一点:使用Spring AOP,要成功运行起代码,只用Spring提供给开发者的jar包是不够的,请额外上网下载两个jar包:
1、aopalliance.jar
2、aspectjweaver.jar
开始讲解用Spring AOP的XML实现方式,先定义一个接口:
public interface HelloWorld {
void printHelloWorld();
void doPrint();
}
2
3
4
定义两个接口实现类:
public class HelloWorldImpl1 implements HelloWorld
{
public void printHelloWorld()
{
System.out.println("Enter HelloWorldImpl1.printHelloWorld()");
}
public void doPrint()
{
System.out.println("Enter HelloWorldImpl1.doPrint()");
return;
}
}
public class HelloWorldImpl2 implements HelloWorld
{
public void printHelloWorld()
{
System.out.println("Enter HelloWorldImpl2.printHelloWorld()");
}
public void doPrint()
{
System.out.println("Enter HelloWorldImpl2.doPrint()");
return;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
横切关注点,这里是打印时间:
public class TimeHandler
{
public void printTime()
{
System.out.println("CurrentTime = " + System.currentTimeMillis());
}
}
2
3
4
5
6
7
有这三个类就可以实现一个简单的Spring AOP了,看一下aop.xml的配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.2.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.2.xsd">
<bean id="helloWorldImpl1" class="com.xrq.aop.HelloWorldImpl1" />
<bean id="helloWorldImpl2" class="com.xrq.aop.HelloWorldImpl2" />
<bean id="timeHandler" class="com.xrq.aop.TimeHandler" />
<aop:config>
<aop:aspect id="time" ref="timeHandler">
<aop:pointcut id="addAllMethod" expression="execution(*
com.xrq.aop.HelloWorld.*(..))" />
<aop:before method="printTime" pointcut-ref="addAllMethod" />
<aop:after method="printTime" pointcut-ref="addAllMethod" />
</aop:aspect>
</aop:config>
</beans>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
写一个main函数调用一下:
public static void main(String[] args)
{
ApplicationContext ctx = new ClassPathXmlApplicationContext("aop.xml");
HelloWorld hw1 = (HelloWorld) ctx.getBean("helloWorldImpl1");
HelloWorld hw2 = (HelloWorld) ctx.getBean("helloWorldImpl2");
hw1.printHelloWorld();
System.out.println();
hw1.doPrint();
System.out.println();
hw2.printHelloWorld();
System.out.println();
hw2.doPrint();
}
2
3
4
5
6
7
8
9
10
11
12
13
运行结果为:
CurrentTime = 1446129611993
Enter HelloWorldImpl1.printHelloWorld()
CurrentTime = 1446129611993
CurrentTime = 1446129611994
Enter HelloWorldImpl1.doPrint()
CurrentTime = 1446129611994
CurrentTime = 1446129611994
Enter HelloWorldImpl2.printHelloWorld()
CurrentTime = 1446129611994
CurrentTime = 1446129611994
Enter HelloWorldImpl2.doPrint()
CurrentTime = 1446129611994
2
3
4
5
6
7
8
9
10
11
12
13
14
15
看到给HelloWorld接口的两个实现类的所有方法都加上了代理,代理内容就是打印时间
# 基于Spring的AOP使用其他细节
1、增加一个横切关注点,打印日志,Java类为:
public class LogHandler
{
public void LogBefore()
{
System.out.println("Log before method");
}
public void LogAfter()
{
System.out.println("Log after method");
}
}
2
3
4
5
6
7
8
9
10
11
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.2.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.2.xsd">
<bean id="helloWorldImpl1" class="com.xrq.aop.HelloWorldImpl1" />
<bean id="helloWorldImpl2" class="com.xrq.aop.HelloWorldImpl2" />
<bean id="timeHandler" class="com.xrq.aop.TimeHandler" />
<bean id="logHandler" class="com.xrq.aop.LogHandler" />
<aop:config>
<aop:aspect id="time" ref="timeHandler" order="1">
<aop:pointcut id="addTime" expression="execution(*
com.xrq.aop.HelloWorld.*(..))" />
<aop:before method="printTime" pointcut-ref="addTime" />
<aop:after method="printTime" pointcut-ref="addTime" />
</aop:aspect>
<aop:aspect id="log" ref="logHandler" order="2">
<aop:pointcut id="printLog" expression="execution(*
com.xrq.aop.HelloWorld.*(..))" />
<aop:before method="LogBefore" pointcut-ref="printLog" />
<aop:after method="LogAfter" pointcut-ref="printLog" />
</aop:aspect>
</aop:config>
</beans>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
测试类不变,打印结果为:
CurrentTime = 1446130273734
Log before method
Enter HelloWorldImpl1.printHelloWorld()
Log after method
CurrentTime = 1446130273735
CurrentTime = 1446130273736
Log before method
Enter HelloWorldImpl1.doPrint()
Log after method
CurrentTime = 1446130273736
CurrentTime = 1446130273736
Log before method
Enter HelloWorldImpl2.printHelloWorld()
Log after method
CurrentTime = 1446130273736
CurrentTime = 1446130273737
Log before method
Enter HelloWorldImpl2.doPrint()
Log after method
CurrentTime = 1446130273737
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
要想让logHandler在timeHandler前使用有两个办法:
(1)aspect里面有一个order属性,order属性的数字就是横切关注点的顺序
(2)把logHandler定义在timeHandler前面,Spring默认以aspect的定义顺序作为织入顺序
2、我只想织入接口中的某些方法
修改一下pointcut的expression就好了:
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.2.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.2.xsd">
<bean id="helloWorldImpl1" class="com.xrq.aop.HelloWorldImpl1" />
<bean id="helloWorldImpl2" class="com.xrq.aop.HelloWorldImpl2" />
<bean id="timeHandler" class="com.xrq.aop.TimeHandler" />
<bean id="logHandler" class="com.xrq.aop.LogHandler" />
<aop:config>
<aop:aspect id="time" ref="timeHandler" order="1">
<aop:pointcut id="addTime" expression="execution(*
com.xrq.aop.HelloWorld.print*(..))" />
<aop:before method="printTime" pointcut-ref="addTime" />
<aop:after method="printTime" pointcut-ref="addTime" />
</aop:aspect>
<aop:aspect id="log" ref="logHandler" order="2">
<aop:pointcut id="printLog" expression="execution(*
com.xrq.aop.HelloWorld.do*(..))" />
<aop:before method="LogBefore" pointcut-ref="printLog" />
<aop:after method="LogAfter" pointcut-ref="printLog" />
</aop:aspect>
</aop:config>
</beans>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
表示timeHandler只会织入HelloWorld接口print开头的方法,logHandler只会织入HelloWorld接口do开头的方法
3、强制使用CGLIB生成代理
前面说过Spring使用动态代理或是CGLIB生成代理是有规则的,高版本的Spring会自动选择是使用动态代理还是CGLIB生成代理内容,当然我们也可以强制使用CGLIB生成代理,那就是aop:config里面有一个"proxy-target-class"属性,这个属性值如果被设置为true,那么基于类的代理将起作用,如果proxy-target-class被设置为false或者这个属性被省略,那么基于接口的代理将起作用
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理:
①JDK动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler接口和Proxy类,InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy利用 InvocationHandler动态创建一个符合某一接口的的实例, 生成目标类的代理对象。
②如果代理类没有实现 InvocationHandler 接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
静态代理与动态代理区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。
# 关于BeanFactory和FactoryBean的区别
# 题⽬描述
⼀道阿⾥⾯试题:说说你知道的关于BeanFactory和FactoryBean的区别?
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:BeanFactory,FactoryBean分别描述清楚,两者之间的区别
# BeanFactory与FactoryBean的区别
BeanFactory是Spring容器的顶级接⼝,给具体的IOC容器的实现提供了规范。
FactoryBean也是接⼝,为IOC容器中Bean的实现提供了更加灵活的⽅式,FactoryBean在IOC容器的基础上给Bean的实现加上了⼀个简单⼯⼚模式和装饰模式(如果想了解装饰模式参考:修饰者模式(装饰者模式,Decoration) 我们可以在getObject()⽅法中灵活配置。其实在Spring源码中有很多FactoryBean的实现类.
**区别:**BeanFactory是个Factory,也就是IOC容器或对象⼯⼚,FactoryBean是个Bean。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进⾏管理的。
但对FactoryBean⽽⾔,这个Bean不是简单的Bean,⽽是⼀个能⽣产或者修饰对象⽣成的⼯⼚Bean,它的实现与设计模式中的⼯⼚模式和修饰器模式类似
# BeanFactory
BeanFactory,以Factory结尾,表示它是⼀个⼯⼚类(接⼝), 它负责⽣产和管理bean的⼀个⼯⼚。在Spring中,BeanFactory是IOC容器的核⼼接⼝,它的职责包括:实例化、定位、配置应⽤程序中的对象及建⽴这些对象间的依赖。
BeanFactory只是个接⼝,并不是IOC容器的具体实现,但是Spring容器给出了很多种实现,如DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,其中XmlBeanFactory就是常⽤的⼀个,该实现将以XML⽅式描述组成应⽤的对象及对象间的依赖关系。XmlBeanFactory类将持有此XML配置元数据,并⽤它来构建⼀个完全可配置的系统或应⽤。
都是附加了某种功能的实现。它为其他具体的IOC容器提供了最基本的规范,例如
DefaultListableBeanFactory,XmlBeanFactory,ApplicationContext 等具体的容器都是实现了BeanFactory,再在其基础之上附加了其他的功能。
BeanFactory和ApplicationContext就是spring框架的两个IOC容器,现在⼀般使⽤ApplicationnContext,其不但包含了BeanFactory的作⽤,同时还进⾏更多的扩展。
BeanFacotry是spring中⽐较原始的Factory。如XMLBeanFactory就是⼀种典型的BeanFactory。
原始的BeanFactory⽆法⽀持spring的许多插件,如AOP功能、Web应⽤等。ApplicationContext接⼝,它由BeanFactory接⼝派⽣⽽来,ApplicationContext包含BeanFactory的所有功能,通常建议⽐BeanFactory优先ApplicationContext以⼀种更向⾯向框架的⽅式⼯作以及对上下⽂进⾏分层和实现继承,ApplicationContext包还提供了以下的功能:
MessageSource, 提供国际化的消息访问
资源访问,如URL和⽂件
事件传播
载⼊多个(有继承关系)上下⽂ ,使得每⼀个上下⽂都专注于⼀个特定的层次,⽐如应⽤的web层;
BeanFactory提供的⽅法及其简单,仅提供了六种⽅法供客户调⽤:
boolean containsBean(String beanName) 判断⼯⼚中是否包含给定名称的bean定义,若有则返回true
Object getBean(String) 返回给定名称注册的bean实例。根据bean的配置情况,如果是singleton模式将返回⼀个共享实例,否则将返回⼀个新建的实例,如果没有找到指定bean,该⽅法可能会抛出异常
Object getBean(String, Class) 返回以给定名称注册的bean实例,并转换为给定class类型
Class getType(String name) 返回给定名称的bean的Class,如果没有找到指定的bean实例,则排除NoSuchBeanDefinitionException异常
boolean isSingleton(String) 判断给定名称的bean定义是否为单例模式
String[] getAliases(String name) 返回给定bean名称的所有别名
# FactoryBean
**⼀般情况下,Spring通过反射机制利⽤<bean>的class属性指定实现类实例化Bean,在某些情况下,实例化Bean过程⽐较复杂,如果按照传统的⽅式,则需要在<bean>中提供⼤量的配置信息。**配置⽅式的灵活性是受限的,这时采⽤编码的⽅式可能会得到⼀个简单的⽅案。
Spring为此提供了⼀个org.springframework.bean.factory.FactoryBean的⼯⼚类接⼝,⽤户可以通过实现该接⼝定制实例化Bean的逻辑。FactoryBean接⼝对于Spring框架来说占⽤重要的地位,Spring⾃身就提供了70多个FactoryBean的实现。**它们隐藏了实例化⼀些复杂Bean的细节,给上层应⽤带来了便利。**从Spring3.0开始,FactoryBean开始⽀持泛型,即接⼝声明改为 FactoryBean
例如⾃⼰实现⼀个FactoryBean,功能:⽤来代理⼀个对象,对该对象的所有⽅法做⼀个拦截,在调⽤前后都输出⼀⾏LOG,模仿ProxyFactoryBean的功能。
FactoryBean是⼀个接⼝,当在IOC容器中的Bean实现了FactoryBean后,通过getBean(String BeanName)获取到的Bean对象并不是FactoryBean的实现类对象,⽽是这个实现类中的getObject()⽅法返回的对象。要想获取FactoryBean的实现类,就要getBean(&BeanName),在BeanName之前加上&。
package org.springframework.beans.factory;
public interface FactoryBean < T >
{
T getObject() throws Exception;
Class < ? > getObjectType();
boolean isSingleton();
}
2
3
4
5
6
7
在该接⼝中还定义了以下3个⽅法:
TgetObject():返回由FactoryBean创建的Bean实例,如果isSingleton()返回true,则该实例会放到Spring容器中单实例缓存池中;
**booleanisSingleton():**返回由FactoryBean创建的Bean实例的作⽤域是singleton还是prototype;
**ClassgetObjectType():**返回FactoryBean创建的Bean类型。
当配置⽂件中
FactoryBean#getObject()代理了getBean()⽅法。
# 总结
BeanFactory是个Factory,也就是IOC容器或对象⼯⼚,FactoryBean是个Bean。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进⾏管理的。但对FactoryBean⽽⾔,这个Bean不是简单的Bean,⽽是⼀个能⽣产或者修饰对象⽣成的⼯⼚Bean,它的实现与设计模式中的⼯⼚模式和修饰器模式类似
# Spring事务的传播机制与隔离级别
# 题⽬描述
描述⼀下Spring事务的传播机制与隔离级别
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:说清楚Spring事务,传播机制与隔离级别,并能描述清楚,分布式事务
# Spring事务
事务是逻辑处理原⼦性的保证⼿段,通过使⽤事务控制,可以极⼤的避免出现逻辑处理失败导致的脏数据等问题。
事务最重要的两个特性,是事务的传播级别和数据隔离级别。传播级别定义的是事务的控制范围,事务隔离级别定义的是事务在数据库读写⽅⾯的控制范围。
# Spring事务传播机制
1) PROPAGATION_REQUIRED ,Spring默认的事务传播级别,使⽤该级别的特点是,如果上下⽂中已经存在事务,那么就加⼊到事务中执⾏,如果当前上下⽂中不存在事务,则新建事务执⾏。所以这个级别通常能满⾜处理⼤多数的业务场景。
2)PROPAGATION_SUPPORTS ,从字⾯意思就知道,supports,⽀持,该传播级别的特点是,如果上下⽂存在事务,则⽀持事务加⼊事务,如果没有事务,则使⽤⾮事务的⽅式执⾏。所以说,并⾮所有的包在transactionTemplate.execute中的代码都会有事务⽀持。这个通常是⽤来处理那些并⾮原⼦性的⾮核⼼业务逻辑操作。应⽤场景较少。
3)PROPAGATION_MANDATORY , 该级别的事务要求上下⽂中必须要存在事务,否则就会抛出异常!配置该⽅式的传播级别是有效的控制上下⽂调⽤代码遗漏添加事务控制的保证⼿段。⽐如⼀段代码不能单独被调⽤执⾏,但是⼀旦被调⽤,就必须有事务包含的情况,就可以使⽤这个传播级别。
4)PROPAGATION_REQUIRES_NEW ,从字⾯即可知道,new,每次都要⼀个新事务,该传播级别的特点是,每次都会新建⼀个事务,并且同时将上下⽂中的事务挂起,执⾏当前新建事务完成以后,上下⽂事务恢复再执⾏。
这是⼀个很有⽤的传播级别,举⼀个应⽤场景:现在有⼀个发送100个红包的操作,在发送之前,要做⼀些系统的初始化、验证、数据记录操作,然后发送100封红包,然后再记录发送⽇志,发送⽇志要求100%的准确,如果⽇志不准确,那么整个⽗事务逻辑需要回滚。
怎么处理整个业务需求呢?就是通过这个PROPAGATION_REQUIRES_NEW 级别的事务传播控制就可以完成。发送红包的⼦事务不会直接影响到⽗事务的提交和回滚。
5)PROPAGATION_NOT_SUPPORTED ,这个也可以从字⾯得知,not supported ,不⽀持,当前级别的特点就是上下⽂中存在事务,则挂起事务,执⾏当前逻辑,结束后恢复上下⽂的事务。
这个级别有什么好处?可以帮助你将事务极可能的缩⼩。我们知道⼀个事务越⼤,它存在的⻛险也就越多。所以在处理事务的过程中,要保证尽可能的缩⼩范围。⽐如⼀段代码,是每次逻辑操作都必须调⽤的,⽐如循环1000次的某个⾮核⼼业务逻辑操作。这样的代码如果包在事务中,势必造成事务太⼤,导致出现⼀些难以考虑周全的异常情况。所以这个事务这个级别的传播级别就派上⽤场了。⽤当前级别的事务模板抱起来就可以了。
6)PROPAGATION_NEVER ,该事务更严格,上⾯⼀个事务传播级别只是不⽀持⽽已,有事务就挂起,⽽PROPAGATION_NEVER传播级别要求上下⽂中不能存在事务,⼀旦有事务,就抛出runtime异常,强制停⽌执⾏!这个级别上辈⼦跟事务有仇。
7)PROPAGATION_NESTED ,字⾯也可知道,nested,嵌套级别事务。该传播级别特征是,如果上下⽂中存在事务,则嵌套事务执⾏,如果不存在事务,则新建事务
# Spring事务隔离级别
1、Serializable :最严格的级别,事务串⾏执⾏,资源消耗最⼤;
2、REPEATABLE READ :保证了⼀个事务不会修改已经由另⼀个事务读取但未提交(回滚)的数据。
避免了“脏读取”和“不可重复读取”的情况,但是带来了更多的性能损失。
3、READ COMMITTED :⼤多数主流数据库的默认事务等级,保证了⼀个事务不会读到另⼀个并⾏事务已修改但未提交的数据,避免了“脏读取”。该级别适⽤于⼤多数系统。
4、Read Uncommitted :保证了读取过程中不会读取到⾮法数据。
上⾯的解释其实每个定义都有⼀些拗⼝,其中涉及到⼏个术语:脏读、不可重复读、幻读。
这⾥解释⼀下:
**脏读 😗*所谓的脏读,其实就是读到了别的事务回滚前的脏数据。⽐如事务B执⾏过程中修改了数据X,在未提交前,事务A读取了X,⽽事务B却回滚了,这样事务A就形成了脏读。
不可重复读 :不可重复读字⾯含义已经很明了了,⽐如事务A⾸先读取了⼀条数据,然后执⾏逻辑的时候,事务B将这条数据改变了,然后事务A再次读取的时候,发现数据不匹配了,就是所谓的不可重复读了。
**幻读 :**⼩的时候数⼿指,第⼀次数⼗10个,第⼆次数是11个,怎么回事?产⽣幻觉了?
幻读也是这样⼦,事务A⾸先根据条件索引得到10条数据,然后事务B改变了数据库⼀条数据,导致也符合事务A当时的搜索条件,这样事务A再次搜索发现有11条数据了,就产⽣了幻读。
# 分布式事务
在分布式的⾼并发环境下,对于核⼼业务逻辑的检查,要采⽤加锁机制。
⽐如事务开启需要读取⼀条数据进⾏验证,然后逻辑操作中需要对这条数据进⾏修改,最后提交。
这样的⼀个过程,如果读取并验证的代码放到事务之外,那么读取的数据极有可能已经被其他的事务修改,当前事务⼀旦提交,⼜会重新覆盖掉其他事务的数据,导致数据异常。
所以在进⼊当前事务的时候,必须要将这条数据锁住,使⽤for update就是⼀个很好的在分布式环境下的控制⼿段。
⼀种好的实践⽅式是使⽤编程式事务⽽⾮⽣命式,尤其是在较为规模的项⽬中。对于事务的配置,在代码量⾮常⼤的情况下,将是⼀种折磨,⽽且⼈⾁的⽅式,绝对不能避免这种问题。
将DAO保持针对⼀张表的最基本操作,然后业务逻辑的处理放⼊manager和service中进⾏,同时使⽤编程式事务更精确的控制事务范围。
特别注意的,对于事务内部⼀些可能抛出异常的情况,捕获要谨慎,不能随便的catch Exception 导致事务的异常被吃掉⽽不能正常回滚。
# Spring中使用了哪些设计模式?
# 1、简单工厂模式
又叫做静态工厂方法(StaticFactory Method)模式,但不属于23种GOF设计模式之一。
简单工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。如下配置,就是在 HelloItxxz 类中创建一个 itxxzBean。
# 2、工厂方法模式
通常由应用程序直接使用new创建新的对象,为了将对象的创建和使用相分离,采用工厂模式,即应用程序将对象的创建及初始化职责交给工厂对象。
一般情况下,应用程序有自己的工厂对象来创建bean.如果将应用程序自己的工厂对象交给Spring管理,那么Spring管理的就不是普通的bean,而是工厂Bean。
就以工厂方法中的静态方法为例讲解一下:
import java.util.Random;
public class StaticFactoryBean
{
public static Integer createRandom()
{
return new Integer(new Random().nextInt());
}
}
2
3
4
5
6
7
8
建一个config.xm配置文件,将其纳入Spring容器来管理,需要通过factory-method指定静态方法名称:
<bean id="random" class="example.chapter3.StaticFactoryBean" factory-method="createRandom" scope="prototype"/>
测试:
public static void main(String[] args)
{
//调用getBean()时,返回随机数.如果没有指定factory-method,会返回StaticFactoryBean的实例,即返回工厂Bean的实例
XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource("config.xml"));
System.out.println("我是IT学习者创建的实例:" + factory.getBean("random").toString());
}
2
3
4
5
6
# 3、单例模式
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
spring中的单例模式完成了后半句话,即提供了全局的访问点BeanFactory。但没有从构造器级别去控制单例,这是因为spring管理的是是任意的java对象。
核心提示点:Spring下默认的bean均为singleton,可以通过singleton=“true|false”或者scope="?"来指定。
# 4、适配器模式
在Spring的Aop中,使用的Advice(通知)来增强被代理类的功能。Spring实现这一AOP功能的原理就使用代理模式(1、JDK动态代理。2、CGLib字节码生成技术代理。)对类进行方法级别的切面增强,即,生成被代理类的代理类, 并在代理类的方法前,设置拦截器,通过执行拦截器重的内容增强了代理方法的功能,实现的面向切面编程。
Adapter类接口:Target
public interface AdvisorAdapter
{
boolean supportsAdvice(Advice advice);
MethodInterceptor getInterceptor(Advisor advisor);
}
2
3
4
5
MethodBeforeAdviceAdapter类, Adapter
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable
{
public boolean supportsAdvice(Advice advice)
{
return (advice instanceof MethodBeforeAdvice);
}
public MethodInterceptor getInterceptor(Advisor advisor)
{
MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();
return new MethodBeforeAdviceInterceptor(advice);
}
}
2
3
4
5
6
7
8
9
10
11
12
# 5、包装器模式
在我们的项目中遇到这样一个问题:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。我们以往在spring和hibernate框架中总是配置一个数据源,因而sessionFactory的dataSource属性总是指向这个数据源并且恒定不变,所有DAO在使用sessionFactory的时候都是通过这个数据源访问数据库。
但是现在,由于项目的需要,我们的DAO在访问sessionFactory的时候都不得不在多个数据源中不断切换,问题就出现了:如何让sessionFactory在执行数据持久化的时候,根据客户的需求能够动态切换不同的数据源?我们能不能在spring的框架下通过少量修改得到解决?是否有什么设计模式可以利用呢?
首先想到在spring的applicationContext中配置所有的dataSource。这些dataSource可能是各种不同类型的,比如不同的数据库:Oracle、SQL Server、MySQL等,也可能是不同的数据源:比如apache 提
供的org.apache.commons.dbcp.BasicDataSource、spring提供的
org.springframework.jndi.JndiObjectFactoryBean等。然后sessionFactory根据客户的每次请求,将dataSource属性设置成不同的数据源,以到达切换数据源的目的。
spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator。基本上都是动态地给一个对象添加一些额外的职责。
# 6、代理模式
为其他对象提供一种代理以控制对这个对象的访问。 从结构上来看和Decorator模式类似,但Proxy是控制,更像是一种对功能的限制,而Decorator是增加职责。
spring的Proxy模式在aop中有体现,比如JdkDynamicAopProxy和Cglib2AopProxy。
# 7、观察者模式
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
spring中Observer模式常用的地方是listener的实现。如ApplicationListener。
# 8、策略模式
定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。
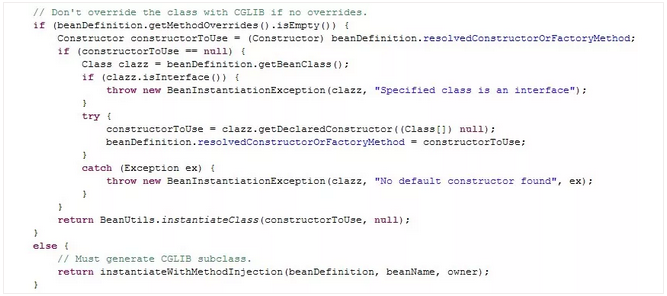
spring中在实例化对象的时候用到Strategy模式
在SimpleInstantiationStrategy中有如下代码说明了策略模式的使用情况:
# 9、模板方法模式
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。Template Method使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
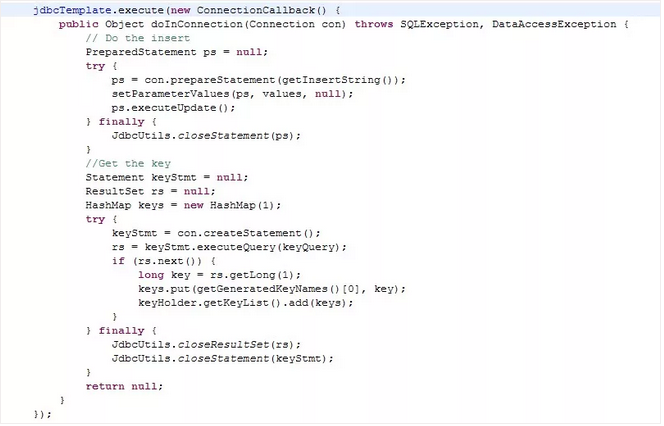
Template Method模式一般是需要继承的。这里想要探讨另一种对Template Method的理解。spring中的JdbcTemplate,在用这个类时并不想去继承这个类,因为这个类的方法太多,但是我们还是想用到JdbcTemplate已有的稳定的、公用的数据库连接,那么我们怎么办呢?我们可以把变化的东西抽出来作为一个参数传入JdbcTemplate的方法中。但是变化的东西是一段代码,而且这段代码会用到JdbcTemplate中的变量。怎么办?那我们就用回调对象吧。
在这个回调对象中定义一个操纵JdbcTemplate中变量的方法,我们去实现这个方法,就把变化的东西集中到这里了。然后我们再传入这个回调对象到JdbcTemplate,从而完成了调用。这可能是TemplateMethod不需要继承的另一种实现方式。
以下是一个具体的例子:
JdbcTemplate中的execute方法
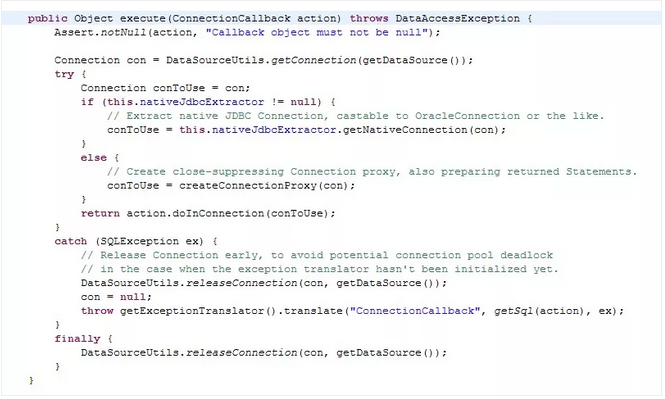
JdbcTemplate执行execute方法
# Spring中bean的作用域与生命周期
# 题目描述
Spring中bean的作用域与生命周期
# 面试题分析
将五种作用域的详细的介绍一下,其次要将它从创建到销毁的过程说一遍。
在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
Spring中的bean默认都是单例的,这些单例Bean在多线程程序下如何保证线程安全呢? 例如对于Web应用来说,Web容器对于每个用户请求都创建一个单独的Sevlet线程来处理请求,引入Spring框架之后,每个Action都是单例的,那么对于Spring托管的单例Service Bean,如何保证其安全呢? Spring的单例是基于BeanFactory也就是Spring容器的,单例Bean在此容器内只有一个,Java的单例是基于JVM,每个JVM内只有一个实例。
# 一、bean的作用域
创建一个bean定义,其实质是用该bean定义对应的类来创建真正实例的“配方”。把bean定义看成一个配方很有意义,它与class很类似,只根据一张“处方”就可以创建多个实例。不仅可以控制注入到对象中的各种依赖和配置值,还可以控制该对象的作用域。这样可以灵活选择所建对象的作用域,而不必在Java Class级定义作用域。Spring Framework支持五种作用域,分别阐述如下表。
五种作用域中,request、session和 global session 三种作用域仅在基于web的应用中使用(不必关心你所采用的是什么web应用框架),只能用在基于 web 的 Spring ApplicationContext 环境。
# 1. singleton——唯一bean 实例
当一个bean的作用域为singleton,那么Spring IoC容器中只会存在一个共享的 bean实例,并且所有对bean的请求,只要 id 与该bean定义相匹配,则只会返回bean的同一实例。
singleton 是单例类型(对应于单例模式),就是在创建起容器时就同时自动创建了一个bean的对象,不管你是否使用,他都存在了,每次获取到的对象都是同一个对象。注意,singleton 作用域是Spring中的缺省作用域。要在XML中将 bean 定义成 singleton ,可以这样配置:
<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" scope="singleton">
也可以通过 @Scope 注解(它可以显示指定bean的作用范围。)的方式
@Service
@Scope("singleton")
public class ServiceImpl{
}
2
3
4
5
# 2. prototype——每次请求都会创建一个新的bean实例
当一个bean的作用域为 prototype,表示一个 bean 定义对应多个对象实例。prototype 作用域的bean 会导致在每次对该 bean 请求**(将其注入到另一个bean中,或者以程序的方式调用容器的getBean()方法**)时都会创建一个新的 bean 实例。prototype 是原型类型,它在我们创建容器的时候并没有实例化,而是当我们获取bean的时候才会去创建一个对象,而且我们每次获取到的对象都不是同一个对象。根据经验,对有状态的 bean 应该使用 prototype 作用域,而对无状态的 bean 则应该使用 singleton 作用域。在 XML 中将 bean 定义成 prototype ,可以这样配置:
<bean id="account" class="com.foo.DefaultAccount" scope="prototype"/>
或者
<bean id="account" class="com.foo.DefaultAccount" singleton="false"/>
通过 @Scope 注解的方式实现就不做演示了。
# 3. request——每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效
request只适用于Web程序,每一次HTTP请求都会产生一个新的bean,同时该bean仅在当前HTTPrequest内有效,当请求结束后,该对象的生命周期即告结束。 在 XML 中将 bean 定义成 prototype,可以这样配置:
<bean id="loginAction" class=cn.csdn.LoginAction" scope="request"/>
# 4. session——每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session内有效
session只适用于Web程序,session作用域表示该针对每一次HTTP 请求都会产生一个新的 bean,同时该bean仅在当前HTTP session内有效.与request作用域一样,可以根据需要放心的更改所创建实例的内部状态,而别的HTTP session中根据 userPreferences创建的实例,将不会看到这些特定于某个HTTP session的状态变化。当HTTP session最终被废弃的时候,在该HTTP session作用域内的bean也会被废弃掉。
<bean id="userPreferences" class="com.foo.UserPreferences" scope="session"/>
# 5. globalSession
global session 作用域类似于标准的 HTTP session 作用域,不过仅仅在基于 portlet 的 web 应用中才有意义。Portlet 规范定义了全局 Session 的概念,它被所有构成某个 portlet web 应用的各种不同的portle t所共享。在global session 作用域中定义的 bean 被限定于全局portlet Session的生命周期范围内。
<bean id="user" class="com.foo.Preferences "scope="globalSession"/>
# 二、bean的生命周期
Spring Bean是Spring应用中最最重要的部分了。所以来看看Spring容器在初始化一个bean的时候会做那些事情,顺序是怎样的,在容器关闭的时候,又会做哪些事情。
Spring容器初始化
=====================================
调用GiraffeService无参构造函数
GiraffeService中利用set方法设置属性值
调用setBeanName:: Bean Name defined in context=giraffeService
调用setBeanClassLoader,ClassLoader Name = sun.misc.Launcher$AppClassLoader
调用setBeanFactory,setBeanFactory:: giraffe bean singleton=true
调用setEnvironment
调用setResourceLoader:: Resource File Name=spring-beans.xml
调用setApplicationEventPublisher
调用setApplicationContext:: Bean Definition Names=[giraffeService,
org.springframework.context.annotation.CommonAnnotationBeanPostProcessor#0,com.giraffe.spring.service.GiraffeServicePostProcessor#0]
执行BeanPostProcessor的postProcessBeforeInitialization方法,beanName=giraffeService
调用PostConstruct注解标注的方法
执行InitializingBean接口的afterPropertiesSet方法
执行配置的init-method
执行BeanPostProcessor的postProcessAfterInitialization方法,beanName=giraffeService
Spring容器初始化完毕
=====================================
从容器中获取Bean
giraffe Name=李光洙
=====================================
调用preDestroy注解标注的方法
执行DisposableBean接口的destroy方法
执行配置的destroy-method
Spring容器关闭
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
先来看看,Spring在Bean从创建到销毁的生命周期中可能做的事情。
# initialization和destroy
有时我们需要在Bean属性值set好之后和Bean销毁之前做一些事情,比如检查Bean中某个属性是否被正常的设置好值了。Spring框架提供了多种方法让我们可以在Spring Bean的生命周期中执行initialization和pre-destroy方法。
1.实现InitializingBean和DisposableBean接口
这两个接口都只包含一个方法。通过实现InitializingBean接口的afterPropertiesSet()方法可以在Bean属性值设置好之后做一些操作,实现DisposableBean接口的destroy()方法可以在销毁Bean之前做一些操作。
例子如下:
public class GiraffeService implements InitializingBean, DisposableBean
{
@Override
public void afterPropertiesSet() throws Exception
{
System.out.println("执行InitializingBean接口的afterPropertiesSet方法");
}
@Override
public void destroy() throws Exception
{
System.out.println("执行DisposableBean接口的destroy方法");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
这种方法比较简单,但是不建议使用。因为这样会将Bean的实现和Spring框架耦合在一起。
2.在bean的配置文件中指定init-method和destroy-method方法
Spring允许我们创建自己的 init 方法和 destroy 方法,只要在 Bean 的配置文件中指定 init-method 和destroy-method 的值就可以在 Bean 初始化时和销毁之前执行一些操作。
例子如下:
public class GiraffeService
{
//通过<bean>的destroy-method属性指定的销毁方法
public void destroyMethod() throws Exception
{
System.out.println("执行配置的destroy-method");
}
//通过<bean>的init-method属性指定的初始化方法
public void initMethod() throws Exception
{
System.out.println("执行配置的init-method");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
配置文件中的配置:
<bean name="giraffeService" class="com.giraffe.spring.service.GiraffeService" init-method="initMethod" destroy-method="destroyMethod">
</bean>
2
需要注意的是自定义的init-method和post-method方法可以抛异常但是不能有参数。
这种方式比较推荐,因为可以自己创建方法,无需将Bean的实现直接依赖于spring的框架。
3.使用@PostConstruct和@PreDestroy注解
除了xml配置的方式,Spring 也支持用 @PostConstruct 和 @PreDestroy 注解来指定 init 和destroy 方法。这两个注解均在 javax.annotation 包中。为了注解可以生效,需要在配置文件中定义org.springframework.context.annotation.CommonAnnotationBeanPostProcessor或
context:annotation-config
例子如下:
public class GiraffeService
{
@PostConstruct
public void initPostConstruct()
{
System.out.println("执行PostConstruct注解标注的方法");
}
@PreDestroy
public void preDestroy()
{
System.out.println("执行preDestroy注解标注的方法");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
配置文件:
<bean class="org.springframework.context.annotation.CommonAnnotationBeanPostProcessor"/>
# 实现Aware接口在Bean中使用Spring框架的一些对象
有些时候我们需要在 Bean 的初始化中使用 Spring 框架自身的一些对象来执行一些操作,比如获取ServletContext 的一些参数,获取 ApplicaitionContext 中的 BeanDefinition 的名字,获取 Bean 在容器中的名字等等。为了让 Bean 可以获取到框架自身的一些对象,Spring 提供了一组名为*Aware的接口。
这些接口均继承于 org.springframework.beans.factory.Aware 标记接口,并提供一个将由 Bean实现的set*方法,Spring通过基于setter的依赖注入方式使相应的对象可以被Bean使用。
网上说,这些接口是利用观察者模式实现的,类似于servlet listeners,目前还不明白,不过这也不在本文的讨论范围内。
介绍一些重要的Aware接口:
ApplicationContextAware: 获得ApplicationContext对象,可以用来获取所有Bean definition的名字。
BeanFactoryAware:获得BeanFactory对象,可以用来检测Bean的作用域。
BeanNameAware:获得Bean在配置文件中定义的名字。
ResourceLoaderAware:获得ResourceLoader对象,可以获得classpath中某个文件。
ServletContextAware:在一个MVC应用中可以获取ServletContext对象,可以读取context中的参数。
ServletConfigAware: 在一个MVC应用中可以获取ServletConfig对象,可以读取config中的参数。
public class GiraffeService implements ApplicationContextAware,
ApplicationEventPublisherAware, BeanClassLoaderAware, BeanFactoryAware,
BeanNameAware, EnvironmentAware, ImportAware, ResourceLoaderAware
{
@Override
public void setBeanClassLoader(ClassLoader classLoader)
{
System.out.println("执行setBeanClassLoader,ClassLoader Name = " + classLoader.getClass().getName());
}
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException
{
System.out.println("执行setBeanFactory,setBeanFactory::giraffe bean singleton = " + beanFactory.isSingleton("giraffeService "));
}
@Override
public void setBeanName(String s)
{
System.out.println("执行setBeanName:: Bean Name defined in context=" + s);
}
@Override
public void setApplicationContext(ApplicationContext applicationContext)
throws BeansException
{
System.out.println("执行setApplicationContext:: Bean Definition Names=" + Arrays.toString(applicationContext.getBeanDefinitionNames()));
}
@Override
public void setApplicationEventPublisher(ApplicationEventPublisher applicationEventPublisher)
{
System.out.println("执行setApplicationEventPublisher");
}
@Override
public void setEnvironment(Environment environment)
{
System.out.println("执行setEnvironment");
}
@Override
public void setResourceLoader(ResourceLoader resourceLoader)
{
Resource resource = resourceLoader.getResource("classpath:spring-beans.xml ");
System.out.println("执行setResourceLoader:: Resource File Name=" + resource.getFilename());
}
@Override
public void setImportMetadata(AnnotationMetadata annotationMetadata)
{
System.out.println("执行setImportMetadata");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# BeanPostProcessor
上面的*Aware接口是针对某个实现这些接口的Bean定制初始化的过程,
Spring同样可以针对容器中的所有Bean,或者某些Bean定制初始化过程,只需提供一个实现BeanPostProcessor接口的类即可。 该接口中包含两个方法,postProcessBeforeInitialization和postProcessAfterInitialization。 postProcessBeforeInitialization方法会在容器中的Bean初始化之前执行, postProcessAfterInitialization方法在容器中的Bean初始化之后执行。
例子如下:
public class CustomerBeanPostProcessor implements BeanPostProcessor
{
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName)
throws BeansException
{
System.out.println("执行BeanPostProcessor的postProcessBeforeInitialization方法, beanName = " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName)
throws BeansException
{
System.out.println("执行BeanPostProcessor的postProcessAfterInitialization方法, beanName = " + beanName);
return bean;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
要将BeanPostProcessor的Bean像其他Bean一样定义在配置文件中
<bean class="com.giraffe.spring.service.CustomerBeanPostProcessor"/>
# 总结
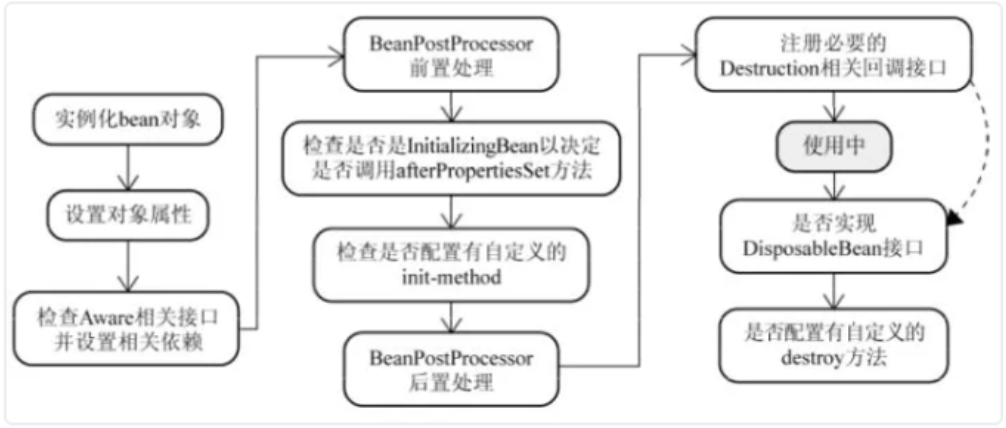
结合第一节控制台输出的内容,Spring Bean的生命周期是这样纸的:
Bean容器找到配置文件中 Spring Bean 的定义。
Bean容器利用Java Reflection API创建一个Bean的实例。
如果涉及到一些属性值 利用set方法设置一些属性值。
如果Bean实现了BeanNameAware接口,调用setBeanName()方法,传入Bean的名字。
如果Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
如果Bean实现了BeanFactoryAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
与上面的类似,如果实现了其他*Aware接口,就调用相应的方法。
如果有和加载这个Bean的Spring容器相关的BeanPostProcessor对象,执行postProcessBeforeInitialization()方法
如果Bean实现了InitializingBean接口,执行afterPropertiesSet()方法。
如果Bean在配置文件中的定义包含init-method属性,执行指定的方法。
如果有和加载这个Bean的Spring容器相关的BeanPostProcessor对象,执行postProcessAfterInitialization()方法
当要销毁Bean的时候,如果Bean实现了DisposableBean接口,执行destroy()方法。
当要销毁Bean的时候,如果Bean在配置文件中的定义包含destroy-method属性,执行指定的方法。
与之比较类似的中文版本:
其实很多时候我们并不会真的去实现上面说描述的那些接口,那么下面我们就除去那些接口,针对bean的单例和非单例来描述下bean的生命周期:
单例管理的对象
当scope=”singleton”,即默认情况下,会在启动容器时(即实例化容器时)时实例化。但我们可以指定Bean节点的lazy-init=”true”来延迟初始化bean,这时候,只有在第一次获取bean时才会初始化bean,即第一次请求该bean时才初始化。如下配置:
<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" lazy-\init="true"/>
如果想对所有的默认单例bean都应用延迟初始化,可以在根节点beans设置default-lazy-init属性为true,如下所示:
<beans default-lazy-init="true" …>
默认情况下,Spring 在读取 xml 文件的时候,就会创建对象。在创建对象的时候先调用构造器,然后调用 init-method 属性值中所指定的方法。对象在被销毁的时候,会调用 destroy-method 属性值中所指定的方法(例如调用Container.destroy()方法的时候)。写一个测试类,代码如下:
public class LifeBean
{
private String name;
public LifeBean()
{
System.out.println("LifeBean()构造函数");
}
public String getName()
{
return name;
}
public void setName(String name)
{
System.out.println("setName()");
this.name = name;
}
public void init()
{
System.out.println("this is init of lifeBean");
}
public void destory()
{
System.out.println("this is destory of lifeBean " + this);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
life.xml配置如下:
<bean id="life_singleton" class="com.bean.LifeBean" scope="singleton"
init-method="init" destroy-method="destory" lazy-init="true"/>
2
测试代码:
public class LifeTest
{
@Test
public void test()
{
AbstractApplicationContext container = new ClassPathXmlApplicationContext("life.xml");
LifeBean life1 = (LifeBean) container.getBean("life");
System.out.println(life1);
container.close();
}
}
2
3
4
5
6
7
8
9
10
11
运行结果:
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@573f2bb1
……
this is destory of lifeBean com.bean.LifeBean@573f2bb1
2
3
4
5
当 scope=”prototype” 时,容器也会延迟初始化 bean,Spring 读取xml 文件的时候,并不会立刻创建对象,而是在第一次请求该 bean 时才初始化(如调用getBean方法时)。在第一次请求每一个prototype 的bean 时,Spring容器都会调用其构造器创建这个对象,然后调用 init-method 属性值中所指定的方法。对象销毁的时候,Spring 容器不会帮我们调用任何方法,因为是非单例,这个类型的对象有很多个,Spring容器一旦把这个对象交给你之后,就不再管理这个对象了。
为了测试prototype bean的生命周期life.xml配置如下:
<bean id="life_prototype" class="com.bean.LifeBean" scope="prototype" init-method="init" destroy-method="destory"/>
测试程序:
public class LifeTest
{
@Test
public void test()
{
AbstractApplicationContext container = new
ClassPathXmlApplicationContext("life.xml");
LifeBean life1 = (LifeBean) container.getBean("life_singleton");
System.out.println(life1);
LifeBean life3 = (LifeBean) container.getBean("life_prototype");
System.out.println(life3);
container.close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
运行结果:
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@573f2bb1
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@5ae9a829
……
this is destory of lifeBean com.bean.LifeBean@573f2bb1
2
3
4
5
6
7
8
可以发现,对于作用域为 prototype 的 bean ,其 destroy 方法并没有被调用。如果bean的scope设为prototype时,当容器关闭时,方法不会被调用。对于 prototype作用域的bean,有一点非常重要,那就是Spring不能对一个prototype bean的整个生命周期负责:容器在初始化、配置、装饰或者是装配完一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。 不管何种作用域,容器都会调用所有对象的初始化生命周期回调方法。但对prototype而言,任何配置好的析构生命周期回调方法都将不会被调用。清除prototype作用域的对象并释放任何prototypebean所持有的昂贵资源,都是客户端代码的职责(让Spring容器释放被prototype作用域bean占用资源的一种可行方式是,通过使用bean的后置处理器,该处理器持有要被清除的bean的引用)。谈及prototype作用域的bean时,在某些方面你可以将Spring容器的角色看作是Java new操作的替代者,任何迟于该时间点的生命周期事宜都得交由客户端来处理。
Spring容器可以管理singleton作用域下bean的生命周期,在此作用域下,Spring能够精确地知道bean何时被创建,何时初始化完成,以及何时被销毁。而对于prototype作用域的bean,Spring只负责创建,当容器创建了bean的实例后,bean的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的bean的生命周期。
