 设计模式
设计模式
# 1 代理模式详解
# 题⽬描述
聊⼀下代理模式,在哪⾥遇到或者使⽤过代理模式
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:代理模式概念,代理模式的三个⻆⾊,静态代理,JDK动态代
理
# 代理模式定义
现实⽣活中经常听到⼀个词“代理”,⽐如某某酒品牌什么什么省总代理;还有像现在的明星都有⾃⼰的经纪⼈,有事需要找他们的时候就要先找他们的经纪⼈,经纪⼈也相当于是⼀个代理;再⽐如打官司都需要找⼀个律师,有什么问题直接由律师去沟通解决,那律师就是⾃⼰的⼀个代理。
⽣活中的代理随处可⻅,Java中也存在⼀种设计模式,就叫代理模式,并且使⽤⾮常普遍,很多著名框架和开源项⽬的源码中都有⼤量使⽤代理模式,⽐如⽐较流⾏的Spring、MyBatis等,都有⽤到代理模式。特别是MyBatis,代理模式随处可⻅。那到底什么是代理模式呢?
代理模式也叫做委托模式,是指为其他对象提供⼀种代理以控制对这个对象的访问。代理模式可以分为静态代理和动态代理,动态代理⼜分为JDK提供的动态代理和CGLIB动态代理
# 代理模式中的三个⻆⾊
代理模式中存在三个⻆⾊:
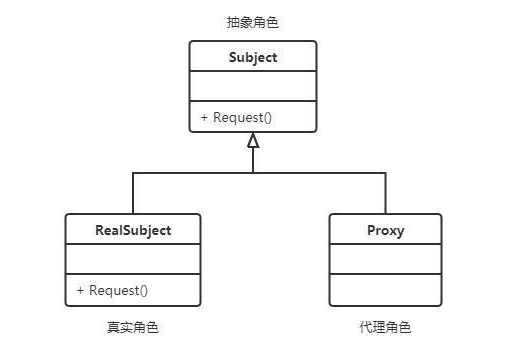
抽象⻆⾊:通过接⼝或抽象类声明真实⻆⾊实现的业务⽅法
代理⻆⾊:实现抽象⻆⾊,是真实⻆⾊的代理,通过真实⻆⾊的业务逻辑⽅法来实现抽象⽅法,并可以附加⾃⼰的操作。
真实⻆⾊:实现抽象⻆⾊,定义真实⻆⾊所要实现的业务逻辑,供代理⻆⾊调⽤。
这三个⻆⾊之间的关系可以⽤⼀张简单的类图来表示:
# 静态代理
静态代理:代理⻆⾊和真实⻆⾊继承同⼀个⽗类或实现相同的接⼝,使⽤时只需要把真实⻆⾊传递给代理⻆⾊,代理⻆⾊调⽤真实⻆⾊的⽅法。
例如游戏代练的例⼦:我们找游戏代练⼀般会找专业的代练公司,代练公司会有很多代练⼈员,我们相当于客户端,代练公司相当于代理⻆⾊,代练⼈员就是真实执⾏任务的真实⻆⾊。
静态代理的优缺点:
优点:
- 真实⻆⾊类(业务类)只需要关注业务逻辑本身,这是代理模式的共有优点。
- 代理类可以在调⽤业务类的处理⽅法之前和之后做⼀些增强性的操作,⽐如记录⽇志,管理事务等,这也是代理模式的共有优点。
缺点:
代理类和业务类实现了相同的接⼝,并且实现了相同的⽅法,代码冗余。如果接⼝增加⼀个⽅法,所有的代理类和所有的实现类都需要增加这个⽅法的实现,不易维护。
代理对象只能代理同⼀种类型的对象,如果要对多种类型的对象进⾏代理,就要写多个代理类,这就⼤⼤增加类⽂件的数量,不适合在⼤规模程序中使⽤
# JDK动态代理
动态代理的代理类是在程序运⾏的时候,有JAVA反射机制动态⽣成的。JAVA的java.lang.reflect包下提供了⼀个Proxy类和⼀个InvocationHandler接⼝,JDK动态代理的实现主要依靠这两个对象实现。
创建⼀个类,实现InvocationHandler接⼝,并重写invoke⽅法。这个类中持有⼀个被代理对象的实例target,还有⼀个invoke⽅法,这个⽅法中通过反射机制调⽤被代理对象target的method⽅法,所有执⾏代理对象的⽅法都会被替换成invoke⽅法。
创建被代理对象的接⼝
创建实际要被代理的对象
创建代理对象,并执⾏要代理的⽅法
我们可以把 InvocationHandler 看做⼀个中介类,中介类持有⼀个被代理对象,在invoke⽅法中调⽤了被代理对象的相应⽅法。
代理类调⽤⾃⼰⽅法时,通过⾃身持有的中介类对象来调⽤中介类对象的invoke⽅法,从⽽达到代理执⾏被代理对象的⽅法。也就是说,动态代理通过中介类实现了具体的代理功能。
动态代理的优点
Java动态代理的优势是实现⽆侵⼊式的代码扩展,也就是⽅法的增强;让你可以在不⽤修改源码的情况下,增强⼀些⽅法;在⽅法的前后你可以做你任何想做的事情(甚⾄不去执⾏这个⽅法就可以)。此外,也可以减少代码量,如果采⽤静态代理,类的⽅法⽐较多的时候,得⼿写⼤量代码。
# 总结
代理模式是常⽤的java设计模式,他的特征是代理类与委托类有同样的接⼝,代理类主要负责为委托类预处理消息、过滤消息、把消息转发给委托类,以及事后处理消息等。代理类与委托类之间通常会存在关联关系,⼀个代理类的对象与⼀个委托类的对象关联,代理类的对象本身并不真正实现服务,⽽是通过调⽤委托类的对象的相关⽅法,来提供特定的服务。简单的说就是,我们在访问实际对象时,是通过代理对象来访问的,代理模式就是在访问实际对象时引⼊⼀定程度的间接性,因为这种间接性,可以附加多种⽤途。
# 2 空对象模式
# 题目描述
面试中的问题:如何做到null值的优雅规避,项目中如何更好避免空指针异常(NullPointerException)
# 案情回顾
我们在写Java Web项目时有个方法叫getBookInfoByIndex,目的是返回Book对象之后再调用book.show方法来获取某个书籍的基本信息。如果我们输入1,2,3等等可以查询到的数字,程序运行正常,但是一旦我们输入-1,或者超过书本数量的index,那不就会报错么。此时我们比较常规的做法就是在客户端加一个判断,判断是否为null。如果为null的话,就不再调用show()方法。但是,你有没有考虑过?这样做,确实消除了报错,但是这样做真的好吗?你想如果在一段程序中有很多处调用getBookInfoByIndex()方法,岂不是很多处都要判断book对象是否为null?这还不算坏,如果哪一处没有判断,然后报错了,很有可能导致程序没法继续运行甚至崩溃。
# 代码实现、
我们将创建一个定义操作(在这里,是客户的名称)的 AbstractCustomer 抽象类,和扩展了AbstractCustomer 类的实体类。工厂类 CustomerFactory 基于客户传递的名字来返回 RealCustomer或 NullCustomer 对象。
NullPatternDemo,我们的演示类使用 CustomerFactory 来演示空对象模式的用法。
# 步骤1
创建一个抽象类。
AbstractCustomer.java
public abstract class AbstractCustomer {
protected String name;
public abstract boolean isNil();
public abstract String getName();
}
2
3
4
5
# 步骤2
创建扩展了上述类的实体类。
RealCustomer.java
public class RealCustomer extends AbstractCustomer {
public RealCustomer(String name) {
this.name = name;
}
@Override
public String getName() {
return name;
}
@Override
public boolean isNil() {
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
NullCustomer.java
public class NullCustomer extends AbstractCustomer {
@Override
public String getName() {
return "Not Available in Customer Database";
}
@Override
public boolean isNil() {
return true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 步骤 3
创建 CustomerFactory 类。
CustomerFactory.java
public class CustomerFactory {
public static final String[] names = {"Rob", "Joe", "Julie"};
public static AbstractCustomer getCustomer(String name){
for (int i = 0; i < names.length; i++) {
if (names[i].equalsIgnoreCase(name)){
return new RealCustomer(name);
}
}
return new NullCustomer();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 步骤4
使用 CustomerFactory,基于客户传递的名字,来获取 RealCustomer 或 NullCustomer 对象。
NullPatternDemo.java
public class NullPatternDemo {
public static void main(String[] args) {
AbstractCustomer customer1 = CustomerFactory.getCustomer("Rob");
AbstractCustomer customer2 = CustomerFactory.getCustomer("Bob");
AbstractCustomer customer3 = CustomerFactory.getCustomer("Julie");
AbstractCustomer customer4 = CustomerFactory.getCustomer("Laura");
System.out.println("Customers");
System.out.println(customer1.getName());
System.out.println(customer2.getName());
System.out.println(customer3.getName());
System.out.println(customer4.getName());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 步骤5
验证输出。
Customers
Rob
Not Available in Customer Database
Julie
Not Available in Customer Database
2
3
4
5
# 总结
空对象就是一个正常的对象,只不过你用这个对象来替代null。作用就是 当使用null表示缺少对象时,在每次引用前都要测试其是否为null,因此需要在代码中加入判断语句,当判断语句变多时,代码就变得杂乱,使用空对象可以减少判断的语句。
# 3 你真的了解单例模式吗?
# 题目描述
手把手教你手写写单例模式
# 题目解决
# 概念
系统中只需要一个全局的实例,比如一些工具类,Converter,SqlSession等。
# 为什么要用单例模式?
只有一个全局的实例,减少了内存开支,特别是某个对象需要频繁的创建和销毁的时候,而创建和销毁的过程由jvm执行,我们无法对其进行优化,所以单例模式的优势就显现出来啦。单例模式可以避免对资源的多重占用,避免出现多线程的复杂问题。
# 单例模式的写法重点
构造方法私有化
我们需要将构造方法私有化,而默认不写的话,是公有的构造方法,外部可以显式的调用来创建对象,我们的目的是让外部不能创建对象。
提供获取实例的公有方法
对外只提供一个公有的的方法,用来获取实例,而这个实例是否是唯一的,单例的,由方法决定,外部无需关心。
# 单例模式的常见写法(如下,重点)
# 饿汉式和懒汉式的区别
# 饿汉式
饿汉式,从名字上也很好理解,就是“比较饿”,迫不及待的想吃饭,实例在初始化的时候就已经建好了,不管你有没有用到,都先建好了再说。
# 懒汉式
饿汉式,从名字上也很好理解,就是“比较懒”,不想吃饭,等饿的时候再吃。在初始化的时候先不建好对象,如果之后用到了,再创建对象。
# 1.饿汉式(静态变量)–可以使用
A类
public class A {
//私有的构造方法
private A() {}
//私有的静态变量
private final static A a = new A();
//对外的公有方法
public static A getInstance() {
return a;
}
}
2
3
4
5
6
7
8
9
10
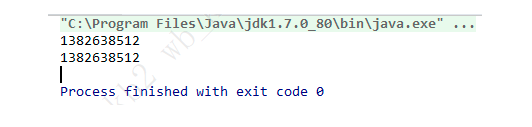
测试类
public class test {
public static void main(String[] args) {
A a1 = A.getInstance();
System.out.println(a1.hashCode());
A a2 = A.getInstance();
System.out.println(a2.hashCode());
}
}
2
3
4
5
6
7
8
运行结果
说明
该方法采用的静态常量的方法来生成对应的实例,其只在类加载的时候就生成了,后续并不会再生成,所以其为单例的。
优点
在类加载的时候,就完成实例化,避免线程同步问题。
缺点
没有达到懒加载的效果,如果从始到终都没有用到这个实例,可能会导致内存的浪费。
# 2.饿汉式(静态代码块)–可以使用
A类
public class A {
//私有的构造方法
private A() {}
//私有的静态变量
private final static A a;
//静态代码块
static {
a = new A();
}
//对外的公有方法
public static A getInstance() {
return a;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
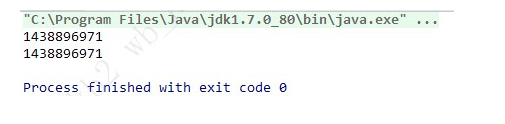
测试类
public class test {
public static void main(String[] args) {
A a1 = A.getInstance();
System.out.println(a1.hashCode());
A a2 = A.getInstance();
System.out.println(a2.hashCode());
}
}
2
3
4
5
6
7
8
运行结果
说明
该静态代码块的饿汉式单例模式与静态变量的饿汉式模式大同小异,只是将初始化过程移到了静态代码块中。
优点缺点
与静态变量饿汉式的优缺点类似。
# 3.懒汉式
A类
public class A {
//私有的构造方法
private A() {}
//私有的静态变量
private static A a;
//对外的公有方法
public static A getInstance() {
if(a == null) {
a = new A();
}
return a;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
测试类和运行结果
同上。
优点
该方法的确做到了用到即加载,也就是当调用getInstance的时候,才判断是否有该对象,如果不为空,则直接放回,如果为空,则新建一个对象并返回,达到了懒加载的效果。
缺点
当多线程的时候,可能会产生多个实例。比如我有两个线程,同时调用getInstance方法,并都到了if语句,他们都新建了对象,那这里就不是单例的啦。
# 4.懒汉式(线程安全,同步方法)–可以使用
A类
public class A {
//私有的构造方法
private A() {}
//私有的静态变量
private static A a;
//对外的公有方法
public synchronized static A getInstance() {
if(a == null) {
a = new A();
}
return a;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
测试类和运行结果
同上。
优点
通过synchronize关键字,解决了线程不安全的问题。如果两个线程同时调用getInstance方法时,那就先执行一个线程,另一个等待,等第一个线程运行结束了,另一个等待的开始执行。
缺点
这种方法是解决了线程不安全的问题,却给性能带来了很大的问题,效率太低了,getInstance经常发生,每一次都要同步这个方法。
我们想着既然是方法同步导致了性能的问题,我们核心的代码就是新建对象的过程,也就是new A();的过程,我们能不能只对部分代码进行同步呢?
那就是方法5啦。
# 5.懒汉式(线程不安全)
A类
public class A {
//私有的构造方法
private A() {}
//私有的静态变量
private static A a;
public static A getInstance() {
if(a == null) {
synchronized(A.class) {
a = new A();
}
}
return a;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
测试类和运行结果
如上。
优点
懒汉式的通用优点,用到才创建,达到懒加载的效果。
缺点
这个没有意义,并没有解决多线程的问题。我们可以看到如果两个线程同时调用getInstance方法,并且都已经进入了if语句,即synchronized的位置,即便同步了,第一个线程先执行,进入synchronized同步的代码块,创建了对象,另一个进入等待状态,等第一个线程执行结束,第二个线程还是会进入synchronized同步的代码块,创建对象。这个时候我们可以发现,对这代码块加了synchronized没有任何意义,还是创建了多个对象,并不符合单例。
# 6.双重检查--强烈推荐使用
A类
public class A {
//私有的构造方法
private A() {}
//私有的静态变量
private volatile static A a;
//对外的公有方法
public static A getInstance() {
if(a == null) {
synchronized(A.class) {
if(a == null) {
a = new A();
}
}
}
return a;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
测试类和运行结果
同上。
优点
强烈推荐使用,这种写法既避免了在多线程中出现线程不安全的情况,也能提高性能。
咱具体来说,如果两个线程同时调用了getInstance方法,并且都已到达了if语句之后,synchronized语句之前,此时第一个线程进入synchronized之中,先判断是否为空,很显然第一次肯定为空,那么则新建了对象。等到第二个线程进入synchronized之中,先判断是否为空,显然第一个已经创建了,所以即不新建对象。下次,不管是一个线程或者多个线程,在第一个if语句那就判断出有对象了,便直接返回啦,根本进不了里面的代码。
缺点
就是这么完美,没有缺点,哈哈哈。
volatile(插曲)
咱先来看一个概念, 重排序 ,也就是语句的执行顺序会被重新安排。其主要分为三种:
1.编译器优化的重排序:可以重新安排语句的执行顺序。
2.指令级并行的重排序:现代处理器采用指令级并行技术,将多条指令重叠执行。
3.内存系统的重排序:由于处理器使用缓存和读写缓冲区,所以看上去可能是乱序的。
上面代码中的a = new A();可能被被JVM分解成如下代码:
// 可以分解为以下三个步骤
1 memory=allocate();// 分配内存 相当于c的malloc
2 ctorInstanc(memory) //初始化对象
3 s=memory //设置s指向刚分配的地址
// 上述三个步骤可能会被重排序为 1-3-2,也就是:
1 memory=allocate();// 分配内存 相当于c的malloc
3 s=memory //设置s指向刚分配的地址
2 ctorInstanc(memory) //初始化对象
一旦假设发生了这样的重排序,比如线程A在执行了步骤1和步骤3,但是步骤2还没有执行完。这个时候线程B有进入了第一个if语句,它会判断a不为空,即直接返回了a。其实这是一个未初始化完成的a,即会出现问题。
所以我们会将入volatile关键字,来禁止这样的重排序,即可正常运行。
# 7.静态内部类--强烈推荐使用
A类
public class A {
//私有构造函数
private A() {}
//私有的静态内部类
private static class B {
//私有的静态变量
private static A a = new A();
}
//对外的公有方法
public static A getInstance() {
return B.a;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
优点
B在A装载的时候并不会装载,而是会在调用getInstance的时候装载,这利用了JVM的装载机制。这样
一来,优点有两点,其一就是没有A加载的时候,就装载了a对象,而是在调用的时候才装载,避免了资
源的浪费。其二是多线程状态下,没有线程安全性的问题。
缺点
没有缺点,太完美啦。
# 8.枚举--Java粑粑强烈推荐使用
问题1:私有构造器并不安全
如果我们的对象是通过反射方法invoke出来,这样新建的对象与通过调用getInstance新建的对象是不一样的,具体咱来看代码。
public class test {
public static void main(String[] args) throws Exception {
A a = A.getInstance();
A b = A.getInstance();
System.out.println("a的hash:" + a.hashCode() + ",b的hash:" + b.hashCode());
Constructor < A > constructor = A.class.getDeclaredConstructor();
constructor.setAccessible(true);
A c = constructor.newInstance();
System.out.println("a的hash:" + a.hashCode() + ",c的hash:" + c.hashCode());
}
}
2
3
4
5
6
7
8
9
10
11
我们来看下运行结果:
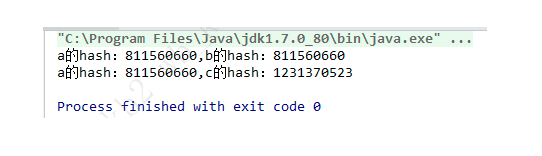
我们可以看到c的hashcode是和a,b不一样,因为c是通过构造器反射出来的,由此可以证明私有构造器
所组成的单例模式并不是十分安全的。
问题2:序列化问题
我们先将A类实现一个Serializable接口,具体代码如下,跟之前的双重if检查一样,只是多了个接口。
public class A implements Serializable {
//私有的构造方法
private A() {}
//私有的静态变量
private volatile static A a;
//对外的公有方法
public static A getInstance() {
if(a == null) {
synchronized(A.class) {
if(a == null) {
a = new A();
}
}
}
return a;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
测试类:
public class test {
public static void main(String[] args) throws Exception {
A s = A.getInstance();
//写
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("学习Java的小姐姐 "));
oos.writeObject(s);
oos.flush();
oos.close();
//读
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("学习Java的小姐姐 "));
A s1 = (A) ois.readObject();
ois.close();
System.out.println(s + "\n" + s1);
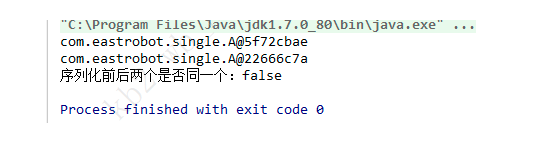
System.out.println("序列化前后两个是否同一个:" + (s == s1));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
我们来看下运行结果,很显然序列化前后两个对象并不相等。为什么会出现这种问题呢?这个讲起来,又可以写一篇文章了。简单来说,任何一个readObject方法,不管是显式的还是默认的,它都会返回一个新建的实例,这个新建的实例不同于该类初始化时创建的实例。
A类
public enum A {
a;
public A getInstance() {
return a;
}
}
2
3
4
5
6
看着代码量很少,我们将其编译下,代码如下:
public final class A extends Enum < A > {
public static final A a;
public static A[] values();
public static AvalueOf(String s);
static {};
}
2
3
4
5
6
如何解决问题1?
public class test {
public static void main(String[] args) throws Exception {
A a1 = A.a;
A a2 = A.a;
System.out.println("正常情况下,实例化两个实例是否相同:" + (a1 == a2));
Constructor < A > constructor = null;
constructor = A.class.getDeclaredConstructor();
constructor.setAccessible(true);
A a3 = null;
a3 = constructor.newInstance();
System.out.println("a1的hash:" + a1.hashCode() + ",a2的hash:" + a2.hashCode() + ",a3的hash:" + a3.hashCode());
System.out.println("通过反射攻击单例模式情况下,实例化两个实例是否相同:" + (a1 == a3));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
运行结果:
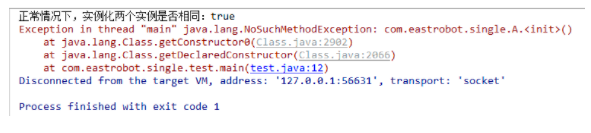
我们看到报错了,是在寻找构造函数的时候报错的,即没有无参的构造方法,那我们看下他继承的父类ENUM有没有构造函数,看下源码,发现有个两个参数String和int类型的构造方法,我们再看下是不是构造方法的问题。
我们再用父类的有参构造方法试下,代码如下:
public class test {
public static void main(String[] args) throws Exception {
A a1 = A.a;
A a2 = A.a;
System.out.println("正常情况下,实例化两个实例是否相同:" + (a1 == a2));
Constructor < A > constructor = null;
constructor = A.class.getDeclaredConstructor(String.class, int.class); //其父类的构造器
constructor.setAccessible(true);
A a3 = null;
a3 = constructor.newInstance("学习Java的小姐姐", 1);
System.out.println("a1的hash:" + a1.hashCode() + ",a2的hash:" + a2.hashCode() + ",a3的hash:" + a3.hashCode());
System.out.println("通过反射攻击单例模式情况下,实例化两个实例是否相同:" + (a1 == a3));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
运行结果如下:
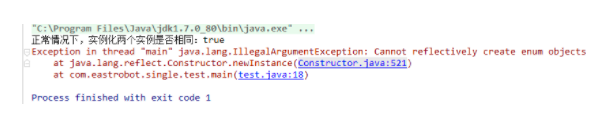
我们发现报错信息的位置已经换了,现在是已经有构造方法,而是在newInstance方法的时候报错了,我们跟下源码发现,人家已经明确写明了如果是枚举类型,直接抛出异常,代码如下,所以是无法使用反射来操作枚举类型的数据的。
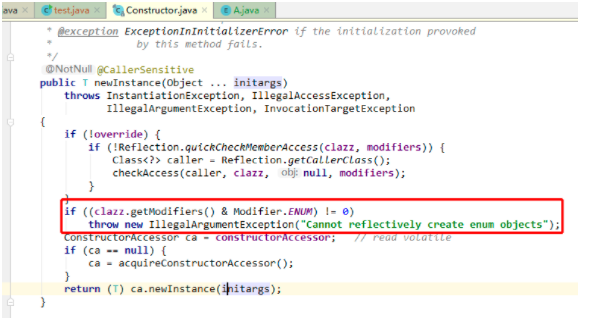
如何解决问题2?
public class test {
public static void main(String[] args) throws Exception {
A s = A.a;
//写
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("学习Java的小姐姐 "));
oos.writeObject(s);
oos.flush();
oos.close();
//读
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("学习Java的小姐姐 "));
A s1 = (A) ois.readObject();
ois.close();
System.out.println(s + "\n" + s1);
System.out.println("序列化前后两个是否同一个:" + (s == s1));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
运行结果:

优点
避免了反射带来的对象不一致问题和反序列问题,简单来说,就是简单高效没问题。
# 4 什么是DDD
# 题⽬描述
了解DDD吗,简单描述⼀下
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:什么是领域驱动模型,与传统软件开发模式的不同
# 什么是DDD(领域驱动模型)
2004年Eric Evans 发表《领域驱动设计——软件核⼼复杂性应对之道》(Domain-Driven Design –Tackling Complexity in the Heart of Software),简称Evans DDD,领域驱动设计思想进⼊软件开发者的视野。领域驱动设计分为两个阶段:
1、以⼀种领域专家、设计⼈员、开发⼈员都能理解的通⽤语⾔作为相互交流的⼯具,在交流的过程中发现领域概念,然后将这些概念设计成⼀个领域模型;
2、由领域模型驱动软件设计,⽤代码来实现该领域模型;
简单地说,软件开发不是⼀蹴⽽就的事情,我们不可能在不了解产品(或⾏业领域)的前提下进⾏软件开发,在开发前,通常需要进⾏⼤ᰁ的业务知识梳理,⽽后到达软件设计的层⾯,最后才是开发。⽽在业务知识梳理的过程中,我们必然会形成某个领域知识,根据领域知识来⼀步步驱动软件设计,就是领域驱动设计的基本概念。⽽领域驱动设计的核⼼就在于建⽴正确的领域驱动模型。
# 传统软件开发与贫⾎模型
传统开发四层架构:View,Service,Dao,Model
在传统模型中,对象是数据的载体,只有简单的getter/setter⽅法,没有⾏为。以数据为中⼼,以数据库ER设计作驱动。分层架构在这种开发模式下,可以理解为是对数据移动、处理和实现的过程。
业务逻辑都是写在Service中的,实体类充其ᰁ只是个数据载体,没有任何⾏为,是⼀种贫⾎模型。简单的业务系统采⽤这种贫⾎模型和过程化设计是没有问题的,但在业务逻辑复杂了,业务逻辑、状态会散落到在⼤ᰁ⽅法中,原本的代码意图会渐渐不明确,我们将这种情况称为由贫⾎症引起的失忆症。
传统架构的特点:
a. 以数据库为中⼼
b. 贫⾎模型
c. 业务逻辑散落在⼤ᰁ的⽅法中
d. 当系统越来越复杂时,开发时间指数增⻓,维护成本很⾼
# DDD设计思想
采⽤DDD的设计思想,业务逻辑不再集中在⼏个⼤型的类上,⽽是由⼤ᰁ相对⼩的领域对象(类)组成,这些类具备⾃⼰的状态和⾏为,每个类是相对完整的独⽴体,并与现实领域的业务对象映射。领域模型就是由这样许多的细粒度的类组成。
# 建⽴领域知识(Build Domain Model)
说了这么多领域模型的概念,到底什么是领域模型呢?作为⼀个软件开发者,我们很难在对⼀个领域不了解的情况下着⼿开发,所以我们⾸先需要和领域专家沟通,建⽴领域只是。以⻜机航⾏为例⼦:
现要为航空公司开发⼀款能够为⻜机提供导航,保证⽆路线冲突监控软件。那我们应该从哪⾥开始下⼿呢?根据DDD的思路,我们第⼀步是 建⽴领域知识 :作为平时管理和维护机场⻜⾏秩序的⼯作⼈员来说,他们⾃然就是这个领域的专家,我们第⼀个⽬标就是与他们沟通,也许我们并不能从中获取所有想要的知识,但⾄少可以筛选出主要的内容和元素。你可能会听到诸如起⻜,着陆,⻜⾏冲突,延误等领域名词,让们从⼀个简单的例⼦开始:
- 起点->⻜机->终点
这个模型很直接,但有点过于简单,因为我们⽆法看出⻜机在空中做了什么,也⽆法得知⻜机怎么从起点到的终点,那么如此似乎会好些:
- ⻜机->路线->起点/终点
既然点构成线,那何不:
- ⻜机->路线->points(含起点,终点)
这个过程,是我们不断建⽴领域知识的过程,其中的᯿点就是寻找领域专家频繁沟通,从中提炼必要领域元素。
# 通⽤语⾔(Ubiquitous Language)
上⾯的例⼦的确看起来简单,但过程并⾮容易:我们(开发⼈员)和领域专家在沟通的过程中是存在天然屏障的:我们满脑⼦都是类,⽅法,设计模式,算法,继承,封装,多态,如何⾯向对象等等;这些领域专家是不懂的,他们只知道⻜机故障,经纬度,航班路线等专业术语。
所以,在建⽴领域知识的时候,我们(开发⼈员和领域专家)必须要交换知识,知识的范围范围涉及领域模型的各个元素,如果⼀⽅对模型的描述令对⽅感到困惑,那么应该⽴刻换⼀种描述⽅式,直到双⽅都能够接受并且理解为⽌。在这⼀过程中,就需要建⽴⼀种通⽤语⾔,作为开发⼈员和领域专家的沟通桥梁。
可如何形成这种通⽤语⾔呢?其实答案并不唯⼀,确切的说也没有什么标准答案。
(a) UML
利⽤UML可以清晰的表现类,并且展示它们之间的关系。但是⼀旦聚合关系复杂,UML叶⼦节点将会变的⼗分庞⼤,可能就没有那么直观易懂了。最᯿要的是,它⽆法精确的描述类的⾏为。为了弥补这种缺陷,可以为具体的⾏为部分补充必要说明(可以是标签或者⽂档),但这往往⼜很耗时,⽽且更新维护起来⼗分不便。
(b) ⽂档/绘图
⽂档耗时很⻓,可能不久就要变化,为模型从⼀开 始到它达到⽐较稳定的状态会发⽣很多次变化, 可能在完成之前它们就已经作废了。对于复杂系统,绘图容易混乱。
(c) 伪代码
极限编程推荐这么做,但是使⽤难度⼤
# 总结
领域驱动设计的核⼼是领域模型,这⼀⽅法论可以通俗的理解为先找到业务中的领域模型,以领域模型为中⼼驱动项⽬的开发。⽽领域模型的设计精髓**在于⾯向对象分析,在于对事物的抽象能⼒,**⼀个领域驱动架构师必然是⼀个⾯向对象分析的⼤师。
在⾯向对象编程中讲究封装,讲究设计低耦合,⾼内聚的类。⽽对于⼀个软件⼯程来讲,仅仅只靠类的设计是不够的,我们需要把紧密联系在⼀起的业务设计为⼀个领域模型,让领域模型内部隐藏⼀些细节,这样⼀来领域模型和领域模型之间的关系就会变得简单。这⼀思想有效的降低了复杂的业务之间千丝万缕的耦合关系。
