 MyBatis
MyBatis
# 说一说你对Mybatis Plugin的了解
# 题目描述
说一说对Mybatis Plugin的了解
# 面试题分析
第一要可以讲出Mybatis插件的原理,第二要讲出它所涉及的JDK动态代理和责任链设计模式
# 前言
Mybatis作为一个应用广泛的优秀的ORM框架,已经成了JavaWeb世界近乎标配的部分,这个框架具有强大的灵活性,在四大组件(Executor、StatementHandler、ParameterHandler、ResultSetHandler)处提供了简单易用的插件扩展机制。Mybatis对持久层的操作就是借助于四大核心对象。MyBatis支持用插件对四大核心对象进行拦截,对mybatis来说插件就是拦截器,用来增强核心对象的功能,增强功能本质上是借助于底层的动态代理实现的,换句话说,MyBatis中的四大对象都是代理对象。
# 四大核心对象简介
MyBatis 四大核心对象
ParameterHandler:处理SQL的参数对象
ResultSetHandler:处理SQL的返回结果集
StatementHandler:数据库的处理对象,用于执行SQL语句
Executor:MyBatis的执行器,用于执行增删改查操作
# Mybatis插件原理
- Mybatis的插件借助于JDK动态代理和责任链设计模式进行对拦截的处理
- 使用动态代理对目标对象进行包装,达到拦截的目的
- 作用于Mybatis的作用域对象之上
# 拦截
插件具体是如何拦截并附加额外的功能的呢?
以ParameterHandler 来说
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object object, BoundSql sql, InterceptorChain interceptorChain)
{
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, object, sql);
parameterHandler = (ParameterHandler)
interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public Object pluginAll(Object target)
{
for(Interceptor interceptor: interceptors)
{
target = interceptor.plugin(target);
}
return target;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
interceptorChain 保存了所有的拦截器(interceptors),是mybatis初始化的时候创建的。调用拦截器链中的拦截器依次的对目标进行拦截或增强。interceptor.plugin(target)中的target就可以理解为mybatis中的四大对象。返回的target是被重重代理后的对象。
# 插件接口
Mybatis插件接口-Interceptor
1.Intercept方法,插件的核心方法
2.plugin方法,生成target的代理对象
3.setProperties方法,传递插件所需参数
# 插件实例
插件开发需要以下步骤
- 自定义插件需要实现上述接口
- 增加@Intercepts注解(声明是哪个核心组件的插件,以及对哪些方法进行扩展)
- 在xml文件中配置插件
/** 插件签名,告诉mybatis插件用来拦截那个对象的哪个方法 **/
@Intercepts(
{
@Signature(type = ResultSetHandler.class, method = "handleResultSets", args = Statement.class)
})
public class MyFirstInterceptor implements Interceptor
{
/** @Description 拦截目标对象的目标方法 **/
@Override
public Object intercept(Invocation invocation) throws Throwable
{
System.out.println("拦截的目标对象:" + invocation.getTarget());
Object object = invocation.proceed();
return object;
}
/**
* @Description 包装目标对象 为目标对象创建代理对象
* @Param target为要拦截的对象
* @Return 代理对象
*/
@Override
public Object plugin(Object target)
{
System.out.println("将要包装的目标对象:" + target);
return Plugin.wrap(target, this);
}
/** 获取配置文件的属性 **/
@Override
public void setProperties(Properties properties)
{
System.out.println("插件配置的初始化参数:" + properties);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
在mybatis.xml中配置插件
<!-- 自定义插件 -->
<plugins>
<plugin interceptor="mybatis.interceptor.MyFirstInterceptor">
<!--配置参数-->
<property name="name" value="Bob"/>
</plugin>
</plugins>
2
3
4
5
6
7
调用查询方法,查询方法会返回ResultSet
public class MyBatisTest
{
public static SqlSessionFactory sqlSessionFactory = null;
public static SqlSessionFactory getSqlSessionFactory()
{
if(sqlSessionFactory == null)
{
String resource = "mybatis-config.xml";
try
{
Reader reader = Resources.getResourceAsReader(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
}
catch (IOException e)
{
e.printStackTrace();
}
}
return sqlSessionFactory;
}
public void testGetById()
{
SqlSession sqlSession = this.getSqlSessionFactory().openSession();
PersonMapper personMapper = sqlSession.getMapper(PersonMapper.class);
Person person = personMapper.getById(2001);
System.out.println(person.toString());
}
public static void main(String[] args)
{
new MyBatisTest().testGetById();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
输出结果
插件配置的初始化参数:{name=Bob}
将要包装的目标对象:org.apache.ibatis.executor.CachingExecutor@754ba872
将要包装的目标对象:
org.apache.ibatis.scripting.defaults.DefaultParameterHandler@192b07fd
将要包装的目标对象:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler@7e0b0338
将要包装的目标对象:
org.apache.ibatis.executor.statement.RoutingStatementHandler@1e127982
拦截的目标对象:
org.apache.ibatis.executor.resultset.DefaultResultSetHandler@7e0b0338
Person{id=2001, username='Tom', email='email@0', gender='F'}
2
3
4
5
6
7
8
9
10
11
# JDK动态代理+责任链设计模式
Mybatis的插件其实就是个拦截器功能。它利用 JDK动态代理和责任链设计模式的综合运用 。采用责任链模式,通过动态代理组织多个拦截器,通过这些拦截器你可以做一些你想做的事。
# 1、JDK动态代理案例
public class MyProxy
{
/**
* 一个接口
*/
public interface HelloService
{
void sayHello();
}
/**
* 目标类实现接口
*/
static class HelloServiceImpl implements HelloService
{
@Override
public void sayHello()
{
System.out.println("sayHello......");
}
}
/**
* 自定义代理类需要实现InvocationHandler接口
*/
static class HWInvocationHandler implements InvocationHandler
{
/**
* 目标对象
*/
private Object target;
public HWInvocationHandler(Object target)
{
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable
{
System.out.println("------插入前置通知代码-------------");
//执行相应的目标方法
Object rs = method.invoke(target, args);
System.out.println("------插入后置处理代码-------------");
return rs;
}
public static Object wrap(Object target)
{
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), new HWInvocationHandler(target));
}
}
public static void main(String[] args)
{
HelloService proxyService = (HelloService) HWInvocationHandler.wrap(new HelloServiceImpl());
proxyService.sayHello();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
运行结果
------插入前置通知代码-------------
sayHello......
------插入后置处理代码-------------
2
3
# 2、优化
上面代理的功能是实现了,但是有个很明显的缺陷,就是 HWInvocationHandler是动态代理类 ,也可以理解成是个工具类,我们不可能会把业务代码写到写到到 invoke方法 里,
不符合面向对象的思想,可以抽象一下处理。可以设计一个 Interceptor接口 ,需要做什么拦截处理实现接口就行了。
public interface Interceptor
{
/**
* 具体拦截处理
*/
void intercept();
}
2
3
4
5
6
7
intercept() 方法就可以处理各种前期准备了
public class LogInterceptor implements Interceptor
{
@Override
public void intercept()
{
System.out.println("------插入前置通知代码-------------");
}
}
public class TransactionInterceptor implements Interceptor
{
@Override
public void intercept()
{
System.out.println("------插入后置处理代码-------------");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
代理对象也做一下修改
public class HWInvocationHandler implements InvocationHandler
{
private Object target;
private List < Interceptor > interceptorList = new ArrayList < > ();
public TargetProxy(Object target, List < Interceptor > interceptorList)
{
this.target = target;
this.interceptorList = interceptorList;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws
Throwable
{
//处理多个拦截器
for(Interceptor interceptor: interceptorList)
{
interceptor.intercept();
}
return method.invoke(target, args);
}
public static Object wrap(Object target, List < Interceptor > interceptorList)
{
HWInvocationHandler targetProxy = new HWInvocationHandler(target, interceptorList);
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), targetProxy);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
现在可以根据需要动态的添加拦截器了,在每次执行业务代码sayHello()之前都会拦截,看起来高级一点,来测试一下
public class Test
{
public static void main(String[] args)
{
List < Interceptor > interceptorList = new ArrayList < > ();
interceptorList.add(new LogInterceptor());
interceptorList.add(new TransactionInterceptor());
HelloService target = new HelloServiceImpl();
Target targetProxy = (Target) TargetProxy.wrap(target, interceptorList);
targetProxy.sayHello();
}
}
2
3
4
5
6
7
8
9
10
11
12
运行结果
------插入前置通知代码-------------
------插入后置处理代码-------------
sayHello......
2
3
# 3、再优化
上面的动态代理确实可以把代理类中的业务逻辑抽离出来,但是我们注意到,只有前置代理,无法做到前后代理,所以还需要在优化下。所以需要做更一步的抽象,把拦截对象信息进行封装,作为拦截器拦截方法的参数,把拦截目标对象真正的执行方法放到Interceptor中完成,这样就可以实现前后拦截,并且还能对拦截对象的参数等做修改。设计一个 Invocation 对象 。
public class Invocation
{
/**
* 目标对象
*/
private Object target;
/**
* 执行的方法
*/
private Method method;
/**
* 方法的参数
*/
private Object[] args;
//省略getset
public Invocation(Object target, Method method, Object[] args)
{
this.target = target;
this.method = method;
this.args = args;
}
/**
* 执行目标对象的方法
*/
public Object process() throws Exception
{
return method.invoke(target, args);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Interceptor拦截接口做修改
public interface Interceptor
{
/**
* 具体拦截处理
*/
Object intercept(Invocation invocation) throws Exception;
}
2
3
4
5
6
7
Interceptor实现类
public class TransactionInterceptor implements Interceptor
{
@Override
public Object intercept(Invocation invocation) throws Exception
{
System.out.println("------插入前置通知代码-------------");
Object result = invocation.process();
System.out.println("------插入后置处理代码-------------");
return result;
}
}
2
3
4
5
6
7
8
9
10
11
Invocation 类就是被代理对象的封装,也就是要拦截的真正对象。HWInvocationHandler修改如下:
public class HWInvocationHandler implements InvocationHandler
{
private Object target;
private Interceptor interceptor;
public TargetProxy(Object target, Interceptor interceptor)
{
this.target = target;
this.interceptor = interceptor;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws
Throwable
{
Invocation invocation = new Invocation(target, method, args);
return interceptor.intercept(invocation);
}
public static Object wrap(Object target, Interceptor interceptor)
{
HWInvocationHandler targetProxy = new HWInvocationHandler(target, interceptor);
return
Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getI nterfaces(), targetProxy);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
测试类
public class Test
{
public static void main(String[] args)
{
HelloService target = new HelloServiceImpl();
Interceptor transactionInterceptor = new TransactionInterceptor();
HelloService targetProxy = (Target)
TargetProxy.wrap(target, transactionInterceptor);
targetProxy.sayHello();
}
}
2
3
4
5
6
7
8
9
10
11
运行结果
------插入前置通知代码-------------
sayHello......
------插入后置处理代码-------------
2
3
# 4、再再优化
上面这样就能实现前后拦截,并且拦截器能获取拦截对象信息。但是测试代码的这样调用看着很别扭,对应目标类来说,只需要了解对他插入了什么拦截就好。
再修改一下,在拦截器增加一个插入目标类的方法。
public interface Interceptor
{
/**
* 具体拦截处理
*/
Object intercept(Invocation invocation) throws Exception;
/**
* 插入目标类
*/
Object plugin(Object target);
}
public class TransactionInterceptor implements Interceptor
{
@Override
public Object intercept(Invocation invocation) throws Exception
{
System.out.println("------插入前置通知代码-------------");
Object result = invocation.process();
System.out.println("------插入后置处理代码-------------");
return result;
}
@Override
public Object plugin(Object target)
{
return TargetProxy.wrap(target, this);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
这样目标类仅仅需要在执行前,插入需要的拦截器就好了,测试代码:
public class Test
{
public static void main(String[] args)
{
HelloService target = new HelloServiceImpl();
Interceptor transactionInterceptor = new TransactionInterceptor();
//把事务拦截器插入到目标类中
target = (HelloService) transactionInterceptor.plugin(target);
target.sayHello();
}
}
2
3
4
5
6
7
8
9
10
11
运行结果
------插入前置通知代码-------------
sayHello......
------插入后置处理代码-------------
2
3
# 5、多个拦截器如何处理
到这里就差不多完成了,那我们再来思考如果要添加多个拦截器呢,怎么搞?
public class Test
{
public static void main(String[] args)
{
HelloService target = new HelloServiceImpl();
Interceptor transactionInterceptor = new TransactionInterceptor();
target = (HelloService) transactionInterceptor.plugin(target);
LogInterceptor logInterceptor = new LogInterceptor();
target = (HelloService) logInterceptor.plugin(target);
target.sayHello();
}
}
2
3
4
5
6
7
8
9
10
11
12
运行结果
------插入前置通知代码-------------
------插入前置通知代码-------------
sayHello......
------插入后置处理代码-------------
------插入后置处理代码-------------
2
3
4
5
# 6、责任链设计模式
其实上面已经实现的没问题了,只是还差那么一点点,添加多个拦截器的时候不太美观,让我们再次利用面向对象思想封装一下。我们设计一个 InterceptorChain 拦截器链类
public class InterceptorChain
{
private List < Interceptor > interceptorList = new ArrayList < > ();
/**
* 插入所有拦截器
*/
public Object pluginAll(Object target)
{
for(Interceptor interceptor: interceptorList)
{
target = interceptor.plugin(target);
}
return target;
}
public void addInterceptor(Interceptor interceptor)
{
interceptorList.add(interceptor);
}
/**
* 返回一个不可修改集合,只能通过addInterceptor方法添加
* 这样控制权就在自己手里
*/
public List < Interceptor > getInterceptorList()
{
return Collections.unmodifiableList(interceptorList);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
其实就是通过pluginAll() 方法包一层把所有的拦截器插入到目标类去而已。测试代码:
public class Test
{
public static void main(String[] args)
{
HelloService target = new HelloServiceImpl();
Interceptor transactionInterceptor = new TransactionInterceptor();
LogInterceptor logInterceptor = new LogInterceptor();
InterceptorChain interceptorChain = new InterceptorChain();
interceptorChain.addInterceptor(transactionInterceptor);
interceptorChain.addInterceptor(logInterceptor);
target = (Target) interceptorChain.pluginAll(target);
target.sayHello();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这里展示的是 JDK动态代理+责任链设计模式 ,那么Mybatis拦截器就是基于该组合进行开发。
# 你知道MyBatis执行过程之初始化是如何执行的吗?
# 题目描述
你知道MyBatis执行过程之初始化是如何执行的吗?
# 题目解决
在了解MyBatis架构以及核心内容分析后,我们可以研究MyBatis执行过程,包括
MyBatis初始化
SQL执行过程
而且在面试会问到一下关于MyBatis初始化的问题,比如:
Mybatis需要初始化哪些?
MyBatis初始化的过程?
# MyBatis初始化
在 MyBatis 初始化过程中,会加载 mybatis-config.xml 配置文件、 Mapper.xml 映射配置文件以及Mapper 接口中的注解信息,解析后的配置信息会形成相应的对象并保存到 Configuration 对象中。
初始化过程可以分成三部分:
解析 mybatis-config.xml 配置文件
SqlSessionFactoryBuilder
XMLConfigBuilder
Configuration
解析 Mapper.xml 映射配置文件
XMLMapperBuilder::parse()
XMLStatementBuilder::parseStatementNode ()
XMLLanguageDriver
SqlSource
MappedStatement
解析Mapper接口中的注解
MapperRegistry
MapperAnnotationBuilder::parse()
# 解析mybatis-config.xml配置文件
MyBatis 的初始化流程的入口是 SqlSessionFactoryBuilder::build(Reader reader, String
environment, Properties properties) 方法,看看具体流程图:
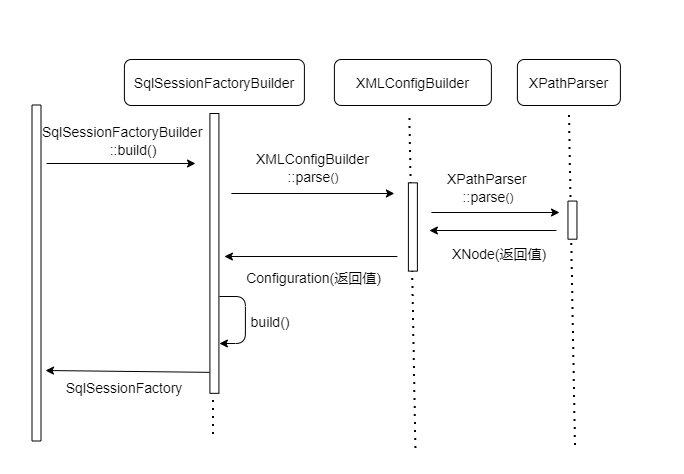
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties)
{
try
{
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse());
}
catch (Exception e)
{
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
}
finally
{
ErrorContext.instance().reset();
try
{
inputStream.close();
}
catch (IOException e)
{
// Intentionally ignore. Prefer previous error.
}
}
}
123456789101112131415
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
首先会使用 XMLConfigBuilder::parser() 解析 mybatis-config.xml 配置文件,
先解析标签 configuration 内的数据封装成 XNode , configuration 也是 MyBatis 中最重要的一个标签
根据 XNode 解析 mybatis-config.xml 配置文件的各个标签转变为各个对象
private void parseConfiguration(XNode root)
{
try
{
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
}
catch (Exception e)
{
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause:
" + e, e);
}
}
123456789101112131415161718192021
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
再基于 Configuration 使用 SqlSessionFactoryBuilder::build() 生成DefaultSqlSessionFactory 供给后续执行使用。
# 解析Mapper.xml映射配置文件
首先使用 XMLMapperBuilder::parse() 解析 Mapper.xml ,看看加载流程图来分析分析
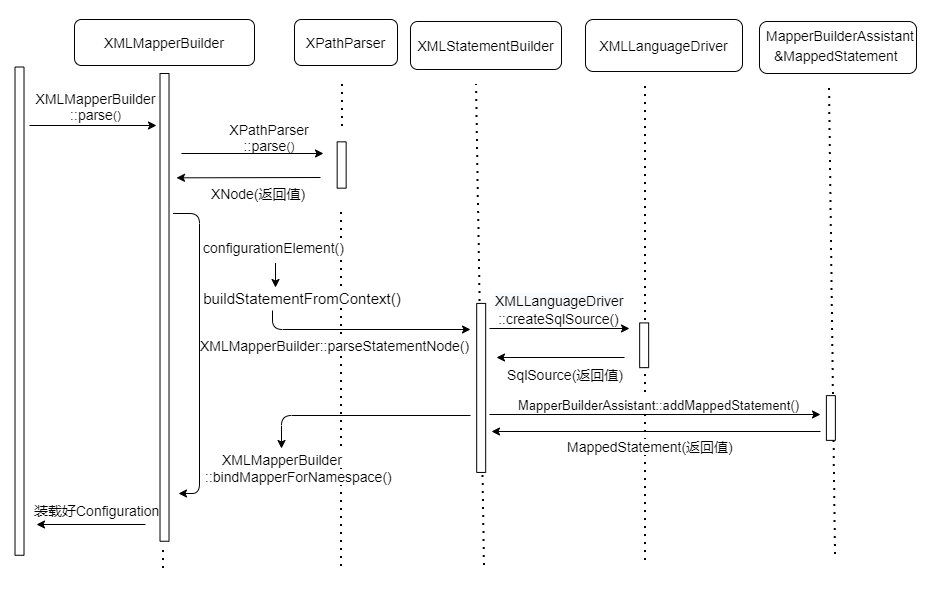
通过 XPathParser::evalNode 将 mapper 标签中内容解析到 XNode
public void parse()
{
if(!this.configuration.isResourceLoaded(this.resource))
{
this.configurationElement(this.parser.evalNode("/mapper"));
this.configuration.addLoadedResource(this.resource);
this.bindMapperForNamespace();
}
this.parsePendingResultMaps();
this.parsePendingCacheRefs();
this.parsePendingStatements();
}
1234567891011
2
3
4
5
6
7
8
9
10
11
12
13
再由 configurationElement() 方法去解析 XNode 中的各个标签:
namespace
parameterMap
resultMap
select|insert|update|delete
private void configurationElement(XNode context)
{
try
{
String namespace = context.getStringAttribute("namespace");
if(namespace == null || namespace.equals(""))
{
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
//解析MapperState
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
}
catch (Exception e)
{
throw new BuilderException("Error parsing Mapper XML. The XML location is'" + resource + "'.Cause: " + e, e);
}
}
123456789101112131415161718
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
其中,基于 XMLMapperBuilder::buildStatementFromContext() ,遍历 、 、 、 节点们,逐个创建 XMLStatementBuilder 对象,执行解析,通过 XMLStatementBuilder::parseStatementNode() 解析,
parameterType
resultType
selectKey 等
并会通过 LanguageDriver::createSqlSource() (默认 XmlLanguageDriver )解析动态sql生成
SqlSource (详细内容请看下个小节),
- 使用 GenericTokenParser::parser() 负责将 SQL 语句中的 #{} 替换成相应的 ? 占位符,并获取该 ? 占位符对应的
而且通过 MapperBuilderAssistant::addMappedStatement() 生成 MappedStatement
public void parseStatementNode()
{
//获得 id 属性,编号
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
// 判断 databaseId 是否匹配
if(!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId))
{
return;
}
//解析获得各种属性
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String parameterType = context.getStringAttribute("parameterType");
Class < ? > parameterTypeClass = resolveClass(parameterType);
String resultMap = context.getStringAttribute("resultMap");
String resultType = context.getStringAttribute("resultType");
String lang = context.getStringAttribute("lang");
//获得 lang 对应的 LanguageDriver 对象
LanguageDriver langDriver = getLanguageDriver(lang);
//获得 resultType 对应的类
Class < ? > resultTypeClass = resolveClass(resultType);
String resultSetType = context.getStringAttribute("resultSetType");
//获得 statementType 对应的枚举值
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
//获得 resultSet 对应的枚举值
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
String nodeName = context.getNode().getNodeName();
//获得 SQL 对应的 SqlCommandType 枚举值
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
//解析获得各种属性
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
//创建 XMLIncludeTransformer 对象,并替换 <include /> 标签相关的内容
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
//解析 <selectKey /> 标签
processSelectKeyNodes(id, parameterTypeClass, langDriver);
//创建 SqlSource生成动态sql
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
String resultSets = context.getStringAttribute("resultSets");
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if(configuration.hasKeyGenerator(keyStatementId))
{
keyGenerator = configuration.getKeyGenerator(keyStatementId);
}
else
{
keyGenerator = context.getBooleanAttribute("useGeneratedKeys", configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)) ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
//创建 MappedStatement 对象
this.builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, (KeyGenerator) keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
12345678910111213141516171819202122232425262728293031323334353637383940414243444
546474849505152535455565758596061626364
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 解析Mapper接口中的注解
当执行完 XMLMapperBuilder::configurationElement() 方法后,会调用XMLMapperBuilder::bindMapperForNamespace() 会转换成对接口上注解进行扫描,具体通过MapperRegistry::addMapper() 调用 MapperAnnotationBuilder 实现的
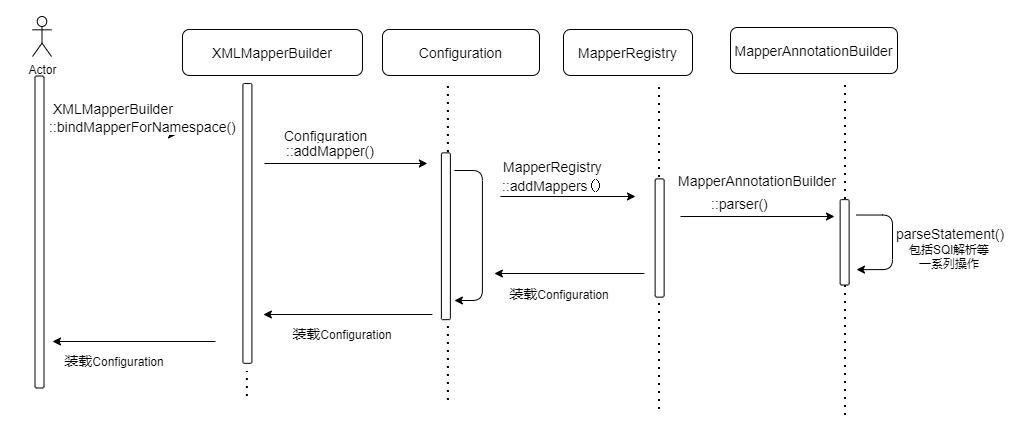
MapperAnnotationBuilder::parse() 是注解构造器,负责解析 Mapper 接口上的注解,解析时需要注意避免和 XMLMapperBuilder::parse() 方法冲突,重复解析,最终使用 parseStatement 解析,那怎么操作?
public void parse()
{
String resource = type.toString();
//判断当前 Mapper 接口是否应加载过。
if(!configuration.isResourceLoaded(resource))
{
//加载对应的 XML Mapper,注意避免和 `XMLMapperBuilder::parse()` 方法冲突
loadXmlResource();
//标记该 Mapper 接口已经加载过
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
//解析 @CacheNamespace 注解
parseCache();
parseCacheRef();
//遍历每个方法,解析其上的注解
Method[] methods = type.getMethods();
for(Method method: methods)
{
try
{
if(!method.isBridge())
{
//执行解析
parseStatement(method);
}
}
catch (IncompleteElementException e)
{
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
//解析待定的方法
parsePendingMethods();
}
12345678910111213141516171819202122232425262728
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
那其中最重要的 parseStatement() 是怎么操作?其实跟解析 Mapper.xml 类型主要处理流程类似:
通过加载LanguageDriver , GenericTokenParser 等为生成 SqlSource 动态sql作准备
使用MapperBuilderAssistant::addMappedStatement() 生成注解@mapper , @CacheNamespace 等的 MappedStatement 信息
void parseStatement(Method method)
{
//获取接口参数类型
Class < ? > parameterTypeClass = getParameterType(method);
//加载语言处理器,默认XmlLanguageDriver
LanguageDriver languageDriver = getLanguageDriver(method);
//根据LanguageDriver,GenericTokenParser生成动态SQL
SqlSource sqlSource = getSqlSourceFromAnnotations(method, parameterTypeClass, languageDriver);
if(sqlSource != null)
{
//获取其他属性
Options options = method.getAnnotation(Options.class);
final String mappedStatementId = type.getName() + "." + method.getName();
Integer fetchSize = null;
Integer timeout = null;
StatementType statementType = StatementType.PREPARED;
ResultSetType resultSetType = null;
SqlCommandType sqlCommandType = getSqlCommandType(method);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = !isSelect;
boolean useCache = isSelect;
//获得 KeyGenerator 对象
KeyGenerator keyGenerator;
String keyProperty = null;
String keyColumn = null;
if(SqlCommandType.INSERT.equals(sqlCommandType) || SqlCommandType.UPDATE.equals(sqlCommandType))
{ // 有
// first check for SelectKey annotation - that overrides everything
else
//如果有 @SelectKey 注解,则进行处理
SelectKey selectKey = method.getAnnotation(SelectKey.class);
if(selectKey != null)
{
keyGenerator = handleSelectKeyAnnotation(selectKey, mappedStatementId, getParameterType(method), languageDriver);
keyProperty = selectKey.keyProperty();
//如果无 @Options 注解,则根据全局配置处理
}
else if(options == null)
{
keyGenerator = configuration.isUseGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
// 如果有 @Options 注解,则使用该注解的配置处理
}
else
{
keyGenerator = options.useGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
keyProperty = options.keyProperty();
keyColumn = options.keyColumn();
}
// 无
}
else
{
keyGenerator = NoKeyGenerator.INSTANCE;
}
//初始化各种属性
if(options != null)
{
if(FlushCachePolicy.TRUE.equals(options.flushCache()))
{
flushCache = true;
}
else if(FlushCachePolicy.FALSE.equals(options.flushCache()))
{
flushCache = false;
}
useCache = options.useCache();
fetchSize = options.fetchSize() > -1 || options.fetchSize() == Integer.MIN_VALUE ? options.fetchSize() : null; //issue #348
timeout = options.timeout() > -1 ? options.timeout() : null;
statementType = options.statementType();
resultSetType = options.resultSetType();
}
// 获得 resultMapId 编号字符串
String resultMapId = null;
//如果有 @ResultMap 注解,使用该注解为 resultMapId 属性
ResultMap resultMapAnnotation = method.getAnnotation(ResultMap.class);
if(resultMapAnnotation != null)
{
String[] resultMaps = resultMapAnnotation.value();
StringBuilder sb = new StringBuilder();
for(String resultMap: resultMaps)
{
if(sb.length() > 0)
{
sb.append(",");
}
sb.append(resultMap);
}
resultMapId = sb.toString();
// 如果无 @ResultMap 注解,解析其它注解,作为 resultMapId 属性
}
else if(isSelect)
{
resultMapId = parseResultMap(method);
}
//构建 MappedStatement 对象
assistant.addMappedStatement(mappedStatementId, sqlSource, statementType, sqlCommandType, fetchSize, timeout,
// ParameterMapID
null, parameterTypeClass, resultMapId, getReturnType(method), resultSetType, flushCache, useCache,
// TODO gcode issue #577
false, keyGenerator, keyProperty, keyColumn,
// DatabaseID
null, languageDriver,
// ResultSets
options != null ? nullOrEmpty(options.resultSets()) : null);
}
}
12345678910111213141516171819202122232425262728293031323334353637383940414243444
54647484950515253545556575859606162636465666768697071727374757677787980818283848
58687888990919293949596979899100101102103104105
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
# 生成动态SqlSource
当在执行 langDriver::createSqlSource(configuration, context, parameterTypeClass) 中的时候, 是怎样从 Mapper XML 或方法注解上读取 SQL 内容生成动态 SqlSource 的呢?现在来一探究竟,
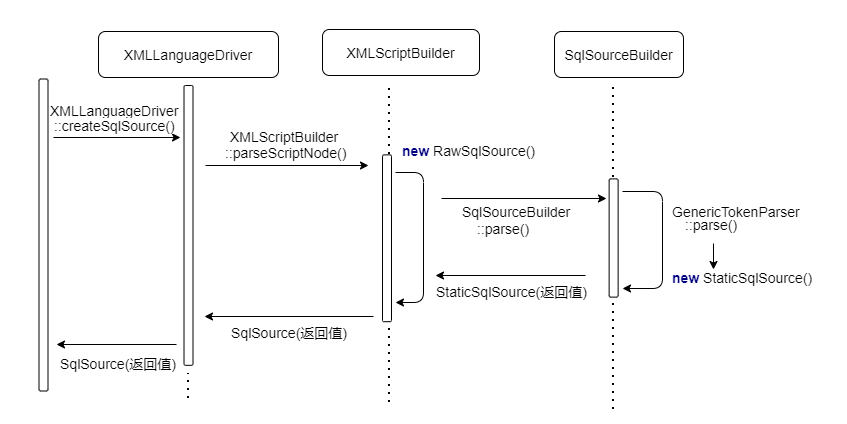
首先需要获取 langDriver 实现 XMLLanguageDriver / RawLanguageDriver ,现在使用默认的XMLLanguageDriver::createSqlSource(configuration, context, parameterTypeClass) 开启创建,再使用 XMLScriptBuilder::parseScriptNode() 解析生成 SqlSource
DynamicSqlSource : 动态的 SqlSource 实现类 , 适用于使用了 OGNL 表达式,或者使用了
${}表达式的 SQLRawSqlSource : 原始的 SqlSource 实现类 , 适用于仅使用 #{} 表达式,或者不使用任何表达式的情况
public SqlSource parseScriptNode()
{
MixedSqlNode rootSqlNode = this.parseDynamicTags(this.context);
Object sqlSource;
if(this.isDynamic)
{
sqlSource = new DynamicSqlSource(this.configuration, rootSqlNode);
}
else
{
sqlSource = new RawSqlSource(this.configuration, rootSqlNode, this.parameterType);
}
return (SqlSource) sqlSource;
}
1234567891011
2
3
4
5
6
7
8
9
10
11
12
13
14
15
那就选择其中一种来分析一下 RawSqlSource ,怎么完成构造的呢?看看 RawSqlSource 构造函数:
public RawSqlSource(Configuration configuration, String sql, Class < ? > parameterType)
{
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class < ? > clazz = parameterType == null ? Object.class : parameterType;
this.sqlSource = sqlSourceParser.parse(sql, clazz, new HashMap());
}
12345
2
3
4
5
6
7
使用 SqlSourceBuilder::parse() 去解析SQl,里面又什么神奇的地方呢?
public SqlSource parse(String originalSql, Class < ? > parameterType, Map < String, Object > additionalParameters)
{
SqlSourceBuilder.ParameterMappingTokenHandler handler = new
SqlSourceBuilder.ParameterMappingTokenHandler(this.configuration, parameterType, additionalParameters);
//创建基于#{}的GenericTokenParser
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
String sql = parser.parse(originalSql);
return new StaticSqlSource(this.configuration, sql, handler.getParameterMappings());
}
1234567
2
3
4
5
6
7
8
9
10
ParameterMappingTokenHandler 是 SqlSourceBuilder 的内部私有静态类,
ParameterMappingTokenHandler ,负责将匹配到的#{和}对,替换成相应的 ? 占位符,并获取该 ?占位符对应的 org.apache.ibatis.mapping.ParameterMapping 对象。
并基于 ParameterMappingTokenHandler 使用 GenericTokenParser::parse() 将SQL中的 #{} 转化占位符? 占位符后创建一个 StaticSqlSource 返回。
# 总结
在 MyBatis 初始化过程中,会加载 mybatis-config.xml 配置文件、 Mapper.xml 映射配置文件以及Mapper 接口中的注解信息,解析后的配置信息会形成相应的对象并全部保存到 Configuration 对象中,并创建 DefaultSqlSessionFactory 供SQl执行过程创建出顶层接口 SqlSession 供给用户进行操作。
# MyBatis 的一级缓存和二级缓存
# 一、前言
先说缓存,合理使用缓存是优化中最常见的,将从数据库中查询出来的数据放入缓存中,下次使用时不必从数据库查询,而是直接从缓存中读取,避免频繁操作数据库,减轻数据库的压力,同时提高系统性能。
# 二、一级缓存
一级缓存 是 SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构用于存储缓存数据。
不同的sqlSession之间的缓存数据区域是互相不影响的。也就是他只能作用在同一个sqlSession中,不同的sqlSession中的缓存是互相不能读取的。
一级缓存的工作原理:
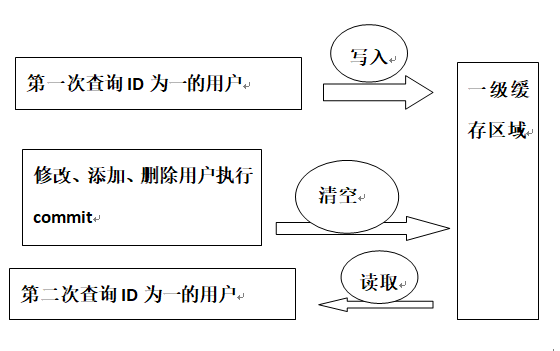
用户发起查询请求,查找某条数据,sqlSession 先去缓存中查找,是否有该数据,如果有,读取;
如果没有,从数据库中查询,并将查询到的数据放入一级缓存区域,供下次查找使用。
但 sqlSession 执行commit,即增删改操作时会清空缓存。这么做的目的是避免脏读。
如果commit不清空缓存,会有以下场景:
A查询了某商品库存为10件,并将10件库存的数据存入缓存中,之后被客户买走了10件,数据被delete了,但是下次查询这件商品时,并不从数据库中查询,而是从缓存中查询,就会出现错误。
既然有了一级缓存,那么为什么要提供二级缓存呢?
二级缓存是 mapper 级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。二级缓存的作用范围更大。
还有一个原因,实际开发中,MyBatis 通常和 Spring 进行整合开发。
Spring 将事务放到 Service 中管理,对于每一个 service 中的 sqlsession 是不同的,这是通过 mybatis-spring 中的 org.mybatis.spring.mapper.MapperScannerConfigurer 创建 sqlsession 自动注入到 service 中的。
每次查询之后都要进行关闭 sqlSession ,关闭之后数据被清空。
所以 spring 整合之后,如果没有事务,一级缓存 是没有意义的。
# 三、二级缓存
二级缓存原理:
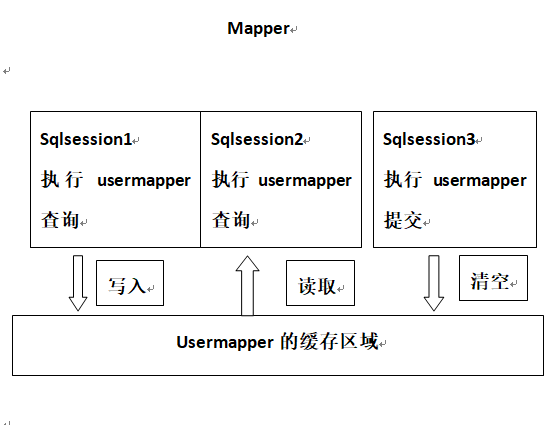
二级缓存是 mapper 级别的缓存,多个 SqlSession 去操作同一个Mapper的sql语句,多个 SqlSession可以共用二级缓存,二级缓存是跨 SqlSession 的。
UserMapper有一个二级缓存区域(按 namespace 划分),每个 mapper 也有自己的二级缓存区域(按namespace分)。
每一个 namespace 的 mapper 都有一个二级缓存区域,如果相同两个 mapper 的 namespace ,这两个mapper执行sql查询到数据将存在相同的二级缓存区域中。
# 3.1、开启二级缓存:
1,打开总开关
在MyBatis的全局配置文件中加入:
<settings>
<!-- 开启二级缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
2
3
4
2,在需要开启二级缓存的 mapper.xml 中加入 cache 标签 :
<cache/>
3,让使用二级缓存的 POJO 类实现 Serializable 接口
public class User implements Serializable {
}
2
3
# 3.2、测试
@Test
public void testCache2() throws Exception
{
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
User user1 = userMapper1.findUserById(1);
System.out.println(user1);
sqlSession1.close();
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
User user2 = userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
输出结果:
DEBUG [main] - Cache Hit Ratio [com.iot.mybatis.mapper.UserMapper]: 0.0
DEBUG [main] - Opening JDBC Connection
DEBUG [main] - Created connection 103887628.
DEBUG [main] - Setting autocommit to false on JDBC Connection
[com.mysql.jdbc.JDBC4Connection@631330c]
DEBUG [main] - ==> Preparing: SELECT * FROM user WHERE id=?
DEBUG [main] - ==> Parameters: 1(Integer)
DEBUG [main] - <== Total: 1
User [id=1, username=张三, sex=1, birthday=null, address=null]
DEBUG [main] - Resetting autocommit to true on JDBC Connection
[com.mysql.jdbc.JDBC4Connection@631330c]
DEBUG [main] - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@631330c]
DEBUG [main] - Returned connection 103887628 to pool.
DEBUG [main] - Cache Hit Ratio [com.iot.mybatis.mapper.UserMapper]: 0.5
User [id=1, username=张三, sex=1, birthday=null, address=null]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们可以从打印的信息看出,两个sqlSession,去查询同一条数据,只发起一次select查询语句,第二次直接从Cache中读取。
前面我们说到,Spring和MyBatis整合时, 每次查询之后都要进行关闭sqlSession,关闭之后数据被清空。所以spring整合之后,如果没有事务,一级缓存是没有意义的。
那么如果开启二级缓存,关闭 sqlsession 后,会把该 sqlsession 一级缓存中的数据添加到namespace的二级缓存中。这样,缓存在sqlsession关闭之后依然存在。
# 3.3、cache标签的属性
<cache
eviction="FIFO" // 回收策略为先进先出
flushInterval="60000" // 自动刷新时间60s
size="512" // 最多缓存512个引用对象
readOnly="true"/> // 只读
2
3
4
5
cache 标签可指定如下属性,每种属性的指定都是针对都是针对底层Cache的一种装饰,采用的是装饰器的模式。
blocking:默认为false,当指定为true时将采用BlockingCache进行封装,blocking,阻塞的意思。
使用BlockingCache会在查询缓存时锁住对应的Key,如果缓存命中了则会释放对应的锁,否则会在查询数据库以后再释放锁,这样可以阻止并发情况下多个线程同时查询数据,详情可参考BlockingCache的源码。
简单理解,也就是设置true时,在进行增删改之后的并发查询,只会有一条去数据库查询,而不会并发。
eviction:eviction 就是 驱逐的意思,也就是元素驱逐算法,默认是LRU。
LRU 对应的就是LruCache,其默认只保存1024个Key,超出时按照最近最少使用算法进行驱逐,详情请参考LruCache的源码。
如果想使用自己的算法,则可以将该值指定为自己的驱逐算法实现类,只需要自己的类实现Mybatis的Cache接口即可。
除了LRU以外,系统还提供:
FIFO(先进先出,对应FifoCache)
SOFT(采用软引用存储Value,便于垃圾回收,对应SoftCache)
WEAK(采用弱引用存储Value,便于垃圾回收,对应WeakCache)这三种策略。
这里,根据个人需求选择了,没什么要求的话,默认的LRU即可。
flushInterval:清空缓存的时间间隔,单位是毫秒,默认是不会清空的。
当指定了该值时会再用ScheduleCache包装一次,其会在每次对缓存进行操作时判断距离最近一次清空缓存的时间是否超过了flushInterval指定的时间,如果超出了,则清空当前的缓存,详情可参考ScheduleCache的实现。
readOnly:是否只读 。默认为false。
当指定为false时,底层会用SerializedCache包装一次,其会在写缓存的时候将缓存对象进行序列化,然后在读缓存的时候进行反序列化,这样每次读到的都将是一个新的对象,即使你更改了读取到的结果,也不会影响原来缓存的对象,即非只读,你每次拿到这个缓存结果都可以进行修改,而不会影响原来的缓存结果;
当指定为true时,那就是每次获取的都是同一个引用,对其修改会影响后续的缓存数据获取,这种情况下是不建议对获取到的缓存结果进行更改,意为只读。 (不建议设置为true)
这是Mybatis二级缓存读写和只读的定义,可能与我们通常情况下的只读和读写意义有点不同。每次都进行序列化和反序列化无疑会影响性能,但是这样的缓存结果更安全,不会被随意更改,具体可根据实际情况进行选择。详情可参考SerializedCache的源码。
size:用来指定缓存中最多保存的Key的数量。
其是针对LruCache而言的,LruCache默认只存储最多1024个Key,可通过该属性来改变默认值,当然,如果你通过eviction指定了自己的驱逐算法,同时自己的实现里面也有setSize方法,那么也可以通过cache的size属性给自定义的驱逐算法里面的size赋值。
type:指定当前底层缓存实现类,默认是PerpetualCache。
如果我们想使用自定义的Cache,则可以通过该属性来指定,对应的值是我们自定义的Cache的全路径名称。
# 3.4、cache-ref标签
<cache-ref namespace="cn.chenhaoxiang.dao.UserMapper"/>
cache-ref 可以用来指定其它 Mapper.xml 中定义的Cache,有的时候可能我们多个不同的 Mapper 需要共享同一个缓存的
是希望在MapperA中缓存的内容在MapperB中可以直接命中的,这个时候我们就可以考虑使用cache-ref,这种场景只需要保证它们的缓存的Key是一致的即可命中,二级缓存的Key是通过Executor接口的createCacheKey()方法生成的,其实现基本都是BaseExecutor。
# 四、总结:
对于查询多、commit少且用户对查询结果实时性要求不高,此时采用 mybatis 二级缓存技术降低数据库访问量,提高访问速度。
但不能滥用二级缓存,二级缓存也有很多弊端,从MyBatis默认二级缓存是关闭的就可以看出来。
二级缓存是建立在同一个 namespace下的,如果对表的操作查询可能有多个 namespace,那么得到的数据就是错误的。
举个简单的例子:
订单 和 订单详情 分别是 orderMapper、orderDetailMapper。
在查询订单详情(orderDetailMapper)时,我们需要把订单信息(orderMapper)也查询出来,那么这个订单详情(orderDetailMapper)的信息被二级缓存在 orderDetailMapper 的 namespace中,这个时候有人要修改订单的基本信息(orderMapper),那就是在 orderMapper 的 namespace 下修改,他是不会影响到 orderDetailMapper 的缓存的,那么你再次查找订单详情时,拿到的是缓存的数据,这个数据其实已经是过时的。
二级缓存的使用原则
- 只能在一个命名空间下使用二级缓存
由于二级缓存中的数据是基于namespace的,即不同 namespace 中的数据互不干扰。
在多个namespace中存在对同一个表的操作,那么这多个namespace中的数据可能就会出现不一致现象。
- 在单表上使用二级缓存
如果一个表与其它表有关联关系,那么就非常有可能存在多个 namespace 对同一数据的操作。
而不同 namespace 中的数据相互干扰,所以就有可能出现多个 namespace 中的数据不一致现象。
- 查询多于修改时使用二级缓存
在查询操作远远多于增删改操作的情况下可以使用二级缓存。因为任何增删改操作都将刷新二级缓存,对二级缓存的频繁刷新将降低系统性能。
# Mybatis动态sql
# 题⽬描述
Mybatis动态sql是做什么的?都有哪些动态sql?能简述⼀下动态sql的执⾏原理吗?
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:动态sql的应⽤、具体有哪些动态sql、动态sql执⾏原理
# 动态sq的应⽤
动态 SQL 是 MyBatis 的强⼤特性之⼀。如果你使⽤过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后⼀个列名的逗号。利⽤动态 SQL,可以彻底摆脱这种痛苦。
使⽤动态 SQL 并⾮⼀件易事,但借助可⽤于任何 SQL 映射语句中的强⼤的动态 SQL 语⾔,MyBatis 显著地提升了这⼀特性的易⽤性。
如果你之前⽤过 JSTL 或任何基于类 XML 语⾔的⽂本处理器,你对动态 SQL 元素可能会感觉似曾相识。
在 MyBatis 之前的版本中,需要花时间了解⼤量的元素。借助功能强⼤的基于 OGNL 的表达式,MyBatis 3 替换了之前的⼤部分元素,⼤⼤精简了元素种类,现在要学习的元素种类⽐原来的⼀半还要少。
# 具体有哪些动态sql
# if
使⽤动态 SQL 最常⻅情景是根据条件包含 where ⼦句的⼀部分。⽐如:
<select id="findActiveBlogWithTitleLike" resultType="Blog">
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
<if test="title != null">
AND title = #{title}
</if>
</select>
2
3
4
5
6
7
这条语句提供了可选的查找⽂本功能。如果不传⼊ “title”,那么所有处于 “ACTIVE” 状态的 BLOG都会返回;如果传⼊了 “title” 参数,那么就会对 “title” ⼀列进⾏匹配查找并返回对应的 BLOG 结果。
# choose , when, otherwise
有时候,我们不想使⽤所有的条件,⽽只是想从多个条件中选择⼀个使⽤。针对这种情况,
MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
还是上⾯的例⼦,但是策略变为:传⼊了 “title” 就按 “title” 查找,传⼊了 “author” 就按 “author” 查找的情形。若两者都没有传⼊,就返回标记为 featured 的 BLOG(这可能是管理员认为,与其返回⼤量的⽆意义随机 Blog,还不如返回⼀些由管理员挑选的 Blog)。
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
# trim, where, set
如果没有匹配的条件会怎么样?最终这条 SQL 会变成这样:
SELECT * FROM BLOG
WHERE
2
这会导致查询失败。如果匹配的只是第⼆个条件⼜会怎样?这条 SQL 会是这样:
SELECT * FROM BLOG
WHERE
AND title like ‘someTitle’
2
3
这个查询也会失败。这个问题不能简单地⽤条件元素来解决。这个问题是如此的难以解决,以⾄于解决过的⼈不会再想碰到这种问题。
MyBatis 有⼀个简单且适合⼤多数场景的解决办法。⽽在其他场景中,可以对其进⾏⾃定义以符合需求。⽽这,只需要⼀处简单的改动:
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
2
3
4
5
6
7
8
9
10
11
12
13
14
where 元素只会在⼦元素返回任何内容的情况下才插⼊ “WHERE” ⼦句。⽽且,若⼦句的开头为“AND” 或 “OR”,where 元素也会将它们去除。
如果 where 元素与你期望的不太⼀样,你也可以通过⾃定义 trim 元素来定制 where 元素的功能。
⽐如,和 where 元素等价的⾃定义 trim 元素为:
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
2
3
prefixOverrides 属性会忽略通过管道符分隔的⽂本序列(注意此例中的空格是必要的)。上述例⼦会移除所有 prefixOverrides 属性中指定的内容,并且插⼊ prefix 属性中指定的内容。
⽤于动态更新语句的类似解决⽅案叫做 set。set 元素可以⽤于动态包含需要更新的列,忽略其它不更新的列。⽐如:
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
2
3
4
5
6
7
8
9
10
这个例⼦中,set 元素会动态地在⾏⾸插⼊ SET 关键字,并会删掉额外的逗号(这些逗号是在使⽤条件语句给列赋值时引⼊的)。
来看看与 set 元素等价的⾃定义 trim 元素吧:
<trim prefix="SET" suffixOverrides=",">
...
</trim>
2
3
注意,我们覆盖了后缀值设置,并且⾃定义了前缀值。
# foreach
动态 SQL 的另⼀个常⻅使⽤场景是对集合进⾏遍历(尤其是在构建 IN 条件语句的时候)。⽐如:
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list" open="(" separator="," close=")">
#{item}
</foreach>
</select>
2
3
4
5
6
7
8
foreach 元素的功能⾮常强⼤,它允许你指定⼀个集合,声明可以在元素体内使⽤的集合项
(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。这个元素也不会错误地添加多余的分隔符,看它多智能!
# 动态sql执⾏原理
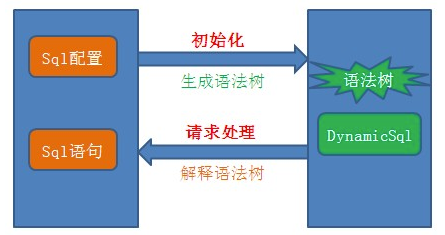
- SqlResource
该接⼝含义是作为sql对象的来源,通过该接⼝可以获取sql对象。其唯⼀的实现类是
XmlSqlResource,表示通过xml⽂件⽣成sql对象。
- Sql
该接⼝可以⽣成sql语句和获取sql相关的上下⽂环境(如ParameterMap、ResultMap等),有三个实现类: RawSql表示为原⽣的sql语句,在初始化即可确定sql语句;SimpleDynamicSql表示简单的动态sql,即sql语句中参数通过$property$⽅式指定,参数在sql⽣成过程中会被替换,不作为sql执⾏参数;DynamicSql表示动态sql,即sql描述⽂件中包含isNotNull、isGreaterThan等条件标签。
- SqlChild
该接⼝表示sql抽象语法树的⼀个节点,包含sql语句的⽚段信息。该接⼝有两个实现类: SqlTag表示动态sql⽚段,即配置⽂件中的⼀个动态标签,内含动态sql属性值(如prepend、property值等);SqlText表示静态sql⽚段,即为原⽣的sql语句。每条动态sql通过SqlTag和SqlText构成相应的抽象语法树。
- SqlTagHandler
该接⼝表示SqlTag(即不同的动态标签)对应的处理⽅式。⽐如实现类IsEmptyTagHandler⽤于处理标签,IsEqualTagHandler⽤于处理标签等。
- SqlTagContext
⽤于解释sql抽象语法树时使⽤的上下⽂环境。通过解释语法树每个节点,将⽣成的sql存⼊
SqlTagContext。最终通过SqlTagContext获取完整的sql语句。
# 总结
从设计上看,dynamic sql的实现主要涉及三个模式:
解释器模式: 初始化过程中构建出抽象语法树,请求处理时根据参数对象解释语法树,⽣成sql语句。
⼯⼚模式: 为动态标签的处理⽅式创建⼯⼚类(SqlTagHandlerFactory),根据标签名称获取对应的处理⽅式。
策略模式: 将动态标签处理⽅式抽象为接⼝,针对不同标签有相应的实现类。解释抽象语法树时,定义统⼀的解释流程,再调⽤标签对应的处理⽅式完成解释中的各个⼦环节。
最后,以⼀张图总结动态sql的实现原理:
# Mybatis延迟加载的原理是什么,它有那些使用场景?
# 题目描述
Mybatis延迟加载的原理是什么,它有那些使用场景?
# 面试题分析
首先要先知道延迟加载的概念,再明白它的原理,最后了解应用场景
# 1.什么是延迟加载
MyBatis中的延迟加载,也称为懒加载,是指在进行表的关联查询时,按照设置延迟规则推迟对关联对象的select查询。例如在进行一对多查询的时候,只查询出一方,当程序中需要多方的数据时,mybatis再发出sql语句进行查询,这样子延迟加载就可以的减少数据库压力。MyBatis 的延迟加载只是对关联对象的查询有迟延设置,对于主加载对象都是直接执行查询语句的。
注意:延迟加载的应用要求:关联对象的查询与主加载对象的查询必须是分别进行的select语句,不能是使用多表连接所进行的select查询
# 2.加载时机
mybatis对于延迟加载的时机支持三种形式
直接加载:执行完对主加载对象的 select 语句,马上执行对关联对象的 select 查询。
侵入式延迟: 执行对主加载对象的查询时,不会执行对关联对象的查询。但当要访问主加载对象的详情属性时,就会马上执行关联对象的select查询。
深度延迟: 执行对主加载对象的查询时,不会执行对关联对象的查询。访问主加载对象的详情时也不会执行关联对象的select查询。只有当真正访问关联对象的详情时,才会执行对关联对象的 select 查询。
# 3.延迟加载使用场景
首先我们先思考一个问题,假设:在一对多中,我们有一个用户,他有100个账户。
问题1:在查询用户的时候,要不要把关联的账户查出来?
问题2:在查询账户的时候,要不要把关联的用户查出来?
解答:在查询用户的时候,用户下的账户信息应该是我们什么时候使用,什么时候去查询。
在查询账户的时候,账户的所属用户信息应该是随着账户查询时一起查询出来。
在对应的四种表关系中,一对多、多对多通常情况下采用延迟加载,多对一、一对一通常情况下采用立即加载。
理解了延迟加载的特性以后再看Mybatis中如何实现查询方法的延迟加载,在MyBatis 的配置文件中通过设置settings的lazyLoadingEnabled属性为true进行开启全局的延迟加载,通过aggressiveLazyLoading属性开启立即加载。看一下官网的介绍,然后通过一个实例来实现Mybatis的延迟加载,在例子中我们展现一对多表关系情况下,通过实现查询用户信息同时查询出该用户所拥有的账户信息的功能展示一下延迟加载的实现方式以及延迟加载和立即加载的结果的不同之处。
1.用户类以及账户类
public class User implements Serializable
{
private Integer id;
private String username;
private Date birthday;
private String sex;
private String address;
private List < Account > accountList;
get和set方法省略.....
}
public class Account implements Serializable
{
private Integer id;
private Integer uid;
private Double money;
get和set方法省略.....
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
注意因为我们是查找用户的同时查找出其所拥有的账户所以我们需要在用户类中增加账户的集合的属性,用来封装返回的结果。
2.在UserDao接口中声明findAll方法
/**
* 查询所有的用户
*
* @return
*/
List < User > findAll();
2
3
4
5
6
3.在UserDao.xml中配置findAll方法的映射
<resultMap id="userAccountMap" type="com.example.domain.User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<collection property="accountList" ofType="com.example.domain.Account" column="id" select="com.example.dao.AccountDao.findAllByUid"/>
</resultMap>
<select id="findAll" resultMap="userAccountMap">
SELECT * FROM USER;
</select>
2
3
4
5
6
7
8
9
10
11
主要的功能实现位于 中,对于账户列表的信息通过collection集合来映射,通过select指定集合中的每个元素如何查询,在本例中select的属性值为AccountDao.xml文件的namespace
com.example.dao.AccountDao路径以及指定该映射文件下的findAllByUid方法,通过这个唯一标识指定集合中元素的查找方式。因为在这里需要用到根据用户ID查找账户,所以需要同时配置一下findAllByUid方法的实现。
4.配置collection中select属性所使用的方法 findAllByUid
AccountDao接口中添加
/**
* 根据用户ID查询账户信息
* @return
*/
List<Account> findAllByUid(Integer uid);
2
3
4
5
AccountDao.xml文件中配置
<select id="findAllByUid" resultType="com.example.domain.Account">
SELECT * FROM account WHERE uid = #{uid};
</select>
2
3
5.在Mybatis的配置文件中开启全局延迟加载
<configuration>
<settings>
<!--开启全局的懒加载-->
<setting name="lazyLoadingEnabled" value="true"/>
<!--关闭立即加载,其实不用配置,默认为false-->
<setting name="aggressiveLazyLoading" value="false"/>
<!--开启Mybatis的sql执行相关信息打印-->
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
<typeAliases>
<typeAlias type="com.example.domain.Account" alias="account"/>
<typeAlias type="com.example.domain.User" alias="user"/>
<package name="com.example.domain"/>
</typeAliases>
<environments default="test">
<environment id="test">
<!--配置事务-->
<transactionManager type="jdbc"></transactionManager>
<!--配置连接池-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test1"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<!--配置映射文件的路径-->
<mappers>
<mapper resource="com/example/dao/UserDao.xml"/>
<mapper resource="com/example/dao/AccountDao.xml"/>
</mappers>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
6.测试方法
private InputStream in ;
private SqlSession session;
private UserDao userDao;
private AccountDao accountDao;
private SqlSessionFactory factory;
@Before
public void init() throws Exception
{
//获取配置文件
in = Resources.getResourceAsStream("SqlMapConfig.xml");
//获取工厂
factory = new SqlSessionFactoryBuilder().build(in);
session = factory.openSession();
userDao = session.getMapper(UserDao.class);
accountDao = session.getMapper(AccountDao.class);
}
@After
public void destory() throws Exception
{
session.commit();
session.close();
in.close();
}
@Test
public void findAllTest()
{
List < User > userList = userDao.findAll();
// for (User user: userList){
// System.out.println("每个用户的信息");
// System.out.println(user);
// System.out.println(user.getAccountList());
// }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
7.测试结果
(1)注释for循环,不使用数据,这时候不需要查询账户信息,通过第五步的sql语句控制台打印看出来,不使用数据的时候,就没有发起对账户的查询。
(2)通过for循环打印查询的数据,使用数据,这时候因为使用了数据所以将查询账户信息,我们可以通过控制台的sql语句打印发现用户和账户查询都进行了执行
# 说一说Mybatis与Hibernate的区别
# 题目描述
Mybatis与Hibernate的区别
# 面试题分析
首先要先知道这两个框架的概念,再明白它的各自的区别,最后指出各自的优缺点
# 这两个框架的概念
Hibernate :Hibernate 是当前最流行的ORM框架,对数据库结构提供了较为完整的封装。
Mybatis:Mybatis同样也是非常流行的ORM框架,主要着力点在于POJO 与SQL之间的映射关系。
# 两者的区别
# 1.两者最大的区别:
针对简单逻辑,Hibernate和MyBatis都有相应的代码生成工具,可以生成简单基本的DAO层方法。
针对高级查询,Mybatis需要手动编写SQL语句,以及ResultMap。而Hibernate有良好的映射机制,开发者无需关心SQL的生成与结果映射,可以更专注于业务流程。
# 2.开发难度对比
Hibernate的开发难度要大于Mybatis。主要由于Hibernate比较复杂、庞大,学习周期较长。
而Mybatis则相对简单一些,并且Mybatis主要依赖于sql的书写,让开发者感觉更熟悉。
# 3.sql书写比较
Mybatis的SQL是手动编写的,所以可以按需求指定查询的字段。不过没有自己的日志统计,所以要借助log4j来记录日志。
Hibernate也可以自己写SQL来指定需要查询的字段,但这样就破坏了Hibernate开发的简洁性。不过Hibernate具有自己的日志统计。
# 4.数据库扩展性比较
Mybatis由于所有SQL都是依赖数据库书写的,所以扩展性,迁移性比较差。
Hibernate与数据库具体的关联都在XML中,所以HQL对具体是用什么数据库并不是很关心。
# 5.缓存机制比较
相同点:Hibernate和Mybatis的二级缓存除了采用系统默认的缓存机制外,都可以通过实现你自己的缓存或为其他第三方缓存方案,创建适配器来完全覆盖缓存行为。
**不同点:**Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置是那种缓存。
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
**两者比较:**因为Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。
而MyBatis在这一方面,使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围,避免Cache的盲目使用。否则,脏数据的出现会给系统的正常运行带来很大的隐患。
# 6.总结:
mybatis:小巧、方便、高效、简单、直接、半自动
hibernate:强大、方便、高效、复杂、绕弯子、全自动
Hibernate与MyBatis都可以是通过SessionFactoryBuider由XML配置文件生成SessionFactory,然后由SessionFactory 生成Session,最后由Session来开启执行事务和SQL语句。
而MyBatis的优势是MyBatis可以进行更为细致的SQL优化,可以减少查询字段,并且容易掌握。
Hibernate的优势是DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。
# 两者各自的特点
mybatis
入门简单,即学即用,提供了数据库查询的自动对象绑定功能,而且延续了很好的SQL使用经验,对于没有那么高的对象模型要求的项目来说,相当完美。
可以进行更为细致的SQL优化,可以减少查询字段。
缺点就是框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
二级缓存机制不佳。
hibernate:
功能强大,数据库无关性好,O/R映射能力强,如果你对Hibernate相当精通,而且对Hibernate进行了适当的封装,那么你的项目整个持久层代码会相当简单,需要写的代码很少,开发速度很快,非常爽。
有更好的二级缓存机制,可以使用第三方缓存。
缺点就是学习门槛不低,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡取得平衡,以及怎样用好Hibernate方面需要你的经验和能力都很强才行。
举个形象的比喻:
mybatis:机械工具,使用方便,拿来就用,但工作还是要自己来作,不过工具是活的,怎么使由我决定。
hibernate:智能机器人,但研发它(学习、熟练度)的成本很高,工作都可以摆脱他了,但仅限于它能做的事。
# MyBatis Mapper接⼝的⼯作原理,Mapper接⼝⾥的⽅法参数不同是,⽅法能重载吗
# 题⽬描述
通常⼀个Xml映射⽂件,都会写⼀个Mapper接⼝与之对应,请问,这个Mapper接⼝的⼯作原理是什么?Mapper接⼝⾥的⽅法,参数不同时,⽅法能重载吗?
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:Mapper接⼝开发规范,Mapper接⼝的⼯作原理,Mapper接⼝⽅法参数不同时,⽅法是否能重载?
# Mapper接⼝开发规范
Mapper接⼝开发需要遵循以下规范:
1、 Mapper.xml⽂件中的namespace与mapper接⼝的类路径相同。
2、 Mapper接⼝⽅法名和Mapper.xml中定义的每个statement的id相同
3、 Mapper接⼝⽅法的输⼊参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
4、 Mapper接⼝⽅法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 命名空间,对sql进⾏分类化管理(sql隔离) -->
<mapper namespace="com.lagou.mapper.UserMapper">
<!-- 在映射⽂件中配置sql语句 -->
<!-- 通过select执⾏查询,id⽤于标识映射⽂件中的sql(Statement-id)
将sql语句封装到mappedstatement中
\#{}表示占位符
parameterType-指定输⼊参数的类型
\#{id}-id表示输⼊的参数,参数名称就是id,如果输⼊参数是简单类型,#{}中的参数可以任意
resultType-指定sql输出结果所映射的java对象类型
-->
<!-- 通过id查询⽤户表的记录 -->
<select id="findUserById" parameterType="int"
resultType="com.lagou.po.User">
select *from user where id=#{id}
</select>
<!-- 根据⽤户名称模糊查询⽤户信息 -->
<!-- resultType-指定单条记录所映射的对象类型
${}拼接sql串,接收参数的内容,不加任何修饰,拼接在sql中(存在sql漏洞)
${}接收输⼊参数的内容,如果传⼊的类型是简单类型,${}中只能使⽤value
-->
<select id="findUserByName" parameterType="java.lang.String"
resultType="com.lagou.po.User">
SELECT *FROM USER WHERE username LIKE '%${value}%'
</select>
<!-- 添加⽤户 -->
<!-- 指定输⼊参数类型是pojo(包括⽤户信息)
\#{}中指定pojo(User)属性名,接收到pojo的属性值
Mybatis通过OGNL获取对象的属性值
-->
<insert id="insertUser" parameterType="com.lagou.po.User">
<!-- 获取刚增加的记录主键
返回id到poio对象(User)
SELECT LAST_INSERT_ID():得到刚插⼊⾦进去记录的主键值,只适⽤于⾃增逐主键
keyProperty:将查询到的主键值设置到parameterType指定的对象User⾥⾯的⽤来做
id的属性,这⾥是:id, 然后在执⾏插⼊的时候,从parameterType(也
就是这⾥的User)的Id⾥⾯取出来,进⾏插⼊
order:指SELECT LAST_INSERT_ID()的执⾏顺序,相对于insert来说
(before/after)
resultType:指定SELECT LAST_INSERT_ID()的结果类型
-->
<selectKey keyProperty="id" order="AFTER"
resultType="java.lang.Integer">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO USER (id,username,birthday,sex,address) VALUES(#{id},#
{username},#{birthday},#{sex},#{address})
<!-- 使⽤mysql的uuid⽣成主键返回
执⾏过程:
⾸先通过uuid得到主键,然后将主键设置到id属性中
其次在Inster执⾏的时候从User对象中取出id的属性值
-->
<!-- <selectKey keyProperty="id" order="BEFORE" resultType="java.lang.String">
SELECT UUID()
</selectKey>
INSERT INTO USER (id,username,birthday,sex,address) VALUES(#{id},#{username},#{birthday},#{sex},#{address}) -->
</insert>
<!-- 根据id删除⽤户 -->
<delete id="deleteUser" parameterType="java.lang.Integer">
DELETE FROM USER WHERE id=#{id}
</delete>
<!-- 根据id更新⽤户传⼊⽤户id以及相关更新信息
#{id}:从输⼊的user对象中获取user的属性值
-->
<update id="updateUser" parameterType="com.lagou.po.User">
UPDATE USER SET username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} WHERE id=#{id}
</update>
</mapper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
# Mapper接⼝⼯作原理
Dao接⼝,就是⼈们常说的Mapper接⼝,接⼝的全限名,就是映射⽂件中的namespace的值,接⼝的⽅法名,就是映射⽂件中MappedStatement的id值,接⼝⽅法内的参数,就是传递给sql的参数。
Mapper接⼝是没有实现类的,当调⽤接⼝⽅法时,接⼝全限名+⽅法名拼接字符串作为key值,可唯⼀定位⼀个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯⼀找到namespace为com.mybatis3.mappers.StudentDao下⾯id = findStudentById的MappedStatement。在Mybatis中,每⼀个``、、、
Mapper 接口的实现类,通过 MyBatis 使用 JDK Proxy 自动生成其代理对象 Proxy ,而代理对象 Proxy 会拦截接口方法,从而“调用”对应的 MappedStatement 方法,最终执行 SQL ,返回执行结果。整体流程如下图:
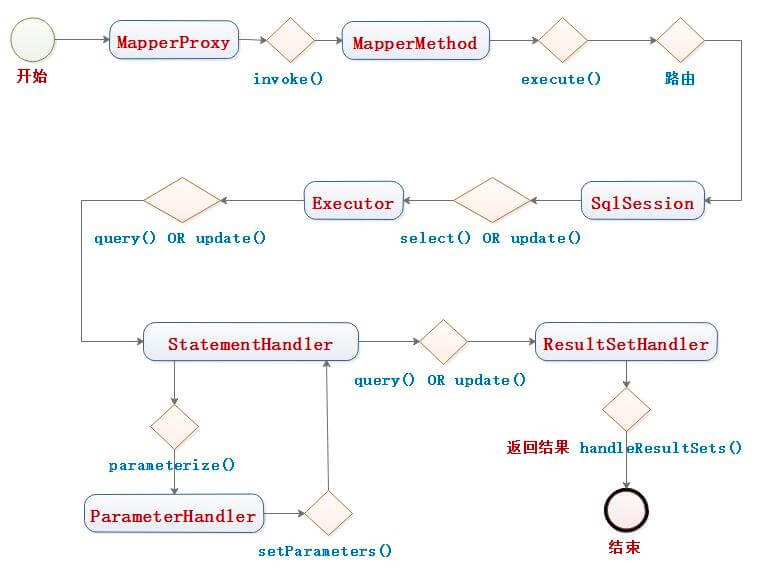
其中,SqlSession 在调用 Executor 之前,会获得对应的 MappedStatement 方法。例如:DefaultSqlSession#select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) 方法,代码如下:
// DefaultSqlSession.java
@Override
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
// 获得 MappedStatement 对象
MappedStatement ms = configuration.getMappedStatement(statement);
// 执行查询
executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
Mapper 接口里的方法,是不能重载的,因为是全限名 + 方法名的保存和寻找策略。
