 Redis
Redis
# RocketMQ
# 如何从0到1设计一个消息队列中间件
# 题目描述
消息队列作为系统解耦,流量控制的利器,成为分布式系统核心组件之一。
如果你对消息队列背后的实现原理关注不多,其实了解消息队列背后的实现非常重要。
不仅知其然还要知其所以然,这才是一个优秀的工程师需要具备的特征。
今天,我们就一起来探讨设计一个消息队列背后的技术。
# 消息队列整体设计思路
主要是设计一个整体的消息被消费的数据流。
这里会涉及到:消息生产Producer、Broker(消息服务端)、消息消费者Consumer。
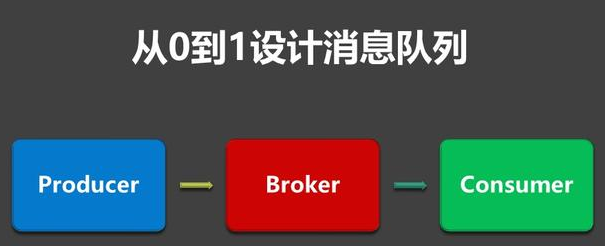
**1.Producer(消息生产者)😗*发送消息到Broker。
**2.Broker(服务端)😗*Broker这个概念主要来自于Apache的ActiveMQ,特指消息队列的服务端。
主要功能就是:把消息从发送端传送到接收端,这里会涉及到消息的存储、消息通讯机制等。
**3.Consumer(消息消费者)😗*从消息队列接收消息,consumer回复消费确认。
# Broker(消息队列服务端)设计重点
**1)消息的转储:**在更合适的时间点投递,或者通过一系列手段辅助消息最终能送达消费机。
**2)规范一种范式和通用的模式,**以满足解耦、最终一致性、错峰等需求。 broker再将消息转发一手到接收端。
3)其实简单理解就是一个消息转发器,把一次RPC做成两次RPC,发送者把消息投递到broker,broker再将消息转发一手到接收端。
总结起来就是两次RPC加一次转储,如果要做消费确认,则是三次RPC。
为了实现上述消息队列的基础功能:
消息的传输
存储
消费
就需要涉及到如下三个方面的设计:
存储选择
通信协议
消费关系维护
# 通讯协议
消息Message:既是信息的载体,消息发送者需要知道如何构造消息,消息接收者需要知道如何解析消息,它们需要按照一种统一的格式描述消息,这种统一的格式称之为消息协议。
传统的通信协议标准有XMPP和AMQP协议等,现在更多的消息队列从性能的角度出发使用自己设计实现的通信协议。
# 1.JMS
JMS(Java MessageService)实际上是指JMS API。JMS是由Sun公司早期提出的消息标准,旨在为java应用提供统一的消息操作,包括创建消息、发送消息、接收消息等。
JMS通常包含如下一些角色:
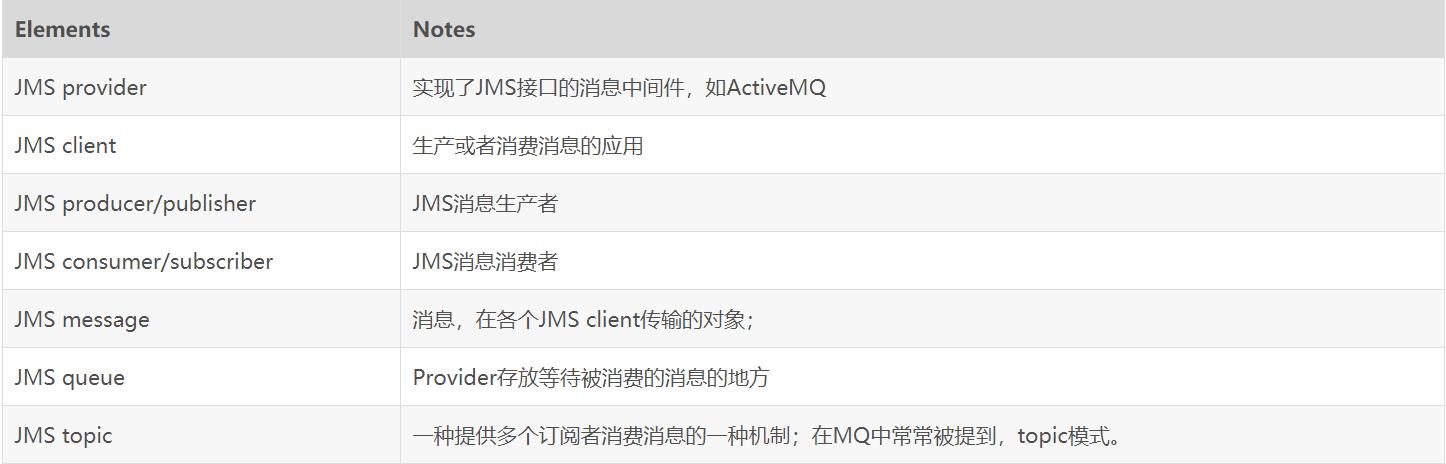
JMS提供了两种消息模型:
点对点
以及publish-subscribe(发布订阅)模型。
当采用点对点模型时,消息将发送到一个队列,该队列的消息只能被一个消费者消费。

而采用发布订阅模型时,消息可以被多个消费者消费。
在发布订阅模型中,生产者和消费者完全独立,不需要感知对方的存在。
# 2.AMQP
AMQP是 Advanced Message Queuing Protocol,即高级消息队列协议。
AMQP不是一个具体的消息队列实现,而 是一个标准化的消息中间件协议。
目标是让不同语言,不同系统的应用互相通信,并提供一个简单统一的模型和编程接口。 目前主流的ActiveMQ和RabbitMQ都支持AMQP协议。
AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。
JMS和AMQP比较
JMS: 只允许基于JAVA实现的消息平台的之间进行通信
AMQP: AMQP允许多种技术同时进行协议通信
# 3.Kafka的通信协议
Kafka的Producer、Broker和Consumer之间采用的是一套自行设计的基于TCP层的协议。Kafka的这
套协议完全是为了Kafka自身的业务需求而定制的。

# 4.存储选型
对于分布式系统,存储的选择有以下几种
内存
本地文件系统
分布式文件系统
nosql
DB
从速度上内存显然是最快的,对于允许消息丢失,消息堆积能力要求不高的场景(例如日志),内存会是比较好的选择。
DB则是最简单的实现可靠存储的方案,很适合用在可靠性要求很高,最终一致性的场景(例如交易消息),对于不需要100%保证数据完整性的场景,要求性能和消息堆积的场景,hbase也是一个很好的选择。
理论上,从速度来看,文件系统>分布式KV(持久化)>分布式文件系统>数据库,而可靠性却截然相反。
还是要从支持的业务场景出发作出最合理的选择,如果你们的消息队列是用来支持支付/交易等对可靠性要求非常高,但对性能和量的要求没有这么高,而且没有时间精力专门做文件存储系统的研究,DB是最好的选择。
对于不需要100%保证数据完整性的场景,要求性能和消息堆积的场景,hbase也是一个很好的选择,典型的比如 kafka的消息落地可以使用hadoop。
消费关系处理
现在我们的消息队列初步具备了转储消息的能力。
下面一个重要的事情就是解析发送接收关系,进行正确的消息投递了。
市面上的消息队列定义了一堆让人晕头转向的名词,如JMS 规范中的Topic/Queue,Kafka里面的Topic/Partition/ConsumerGroup,RabbitMQ里面的Exchange等等。
抛开现象看本质,无外乎是单播与广播的区别。
所谓单播,就是点到点;而广播,是一点对多点。
为了实现广播功能,我们必须要维护消费关系,通常消息队列本身不维护消费订阅关系,可以利用zookeeper等成熟的系统维护消费关系,在消费关系发生变化时下发通知。
# 5.消息队列需要支持高级特性
除了上述的消息队列基本功能以外,消息队列在某些特殊的场景还需要支持事务,消息重试等功能。
消息的顺序
投递可靠性保证
消息持久化
支持不同消息模型
多实例集群功能
事务特性等
# RocketMQ的架构设计、关键特性与应用场景
# 题目描述
RocketMQ的架构设计、关键特性与应用场景
# 面试题分析
根据题目要求我们可以知道:
RocketMQ的简介
RocketMQ的演进
RocketMQ的架构设计
RocketMQ的关键特性
RocketMQ的应用场景
分析需要全面并且有深度
容易被忽略的坑
分析片面 没有深入
# RocketMQ的简介
RocketMQ⼀个纯java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿⾥研发的⼀个队列模型的消息中间件,后开源给apache基⾦会成为了apache的顶级开源项⽬,具有⾼性能、⾼可靠、⾼实时、分布式特点。
# RocketMQ的演进
RocketMQ⼀共前后经历了三代演进:
1.第⼀代,推模式
数据存储采⽤关系型数据库,典型代表包括Notify、Napoli。
2.第⼆代,拉模式
⾃研的专有消息存储,在⽇志处理⽅⾯参考Kafka,典型代表MetaQ。
3.第三代,以拉模式为主,兼有推模式
低延迟消息引擎RocketMQ,在⼆代功能特性的基础上,为电商⾦融领域添加了可靠重试、基于⽂件存储的分布式事务等特性。使⽤在了阿⾥⼤量的应⽤上,典型如双11场景,具有万亿级消息流转。
# RocketMQ的架构设计
# 1.RocketMQ的核⼼组件
RocketMQ主要由NameServer、Broker、Producer以及Consumer四部分构成。
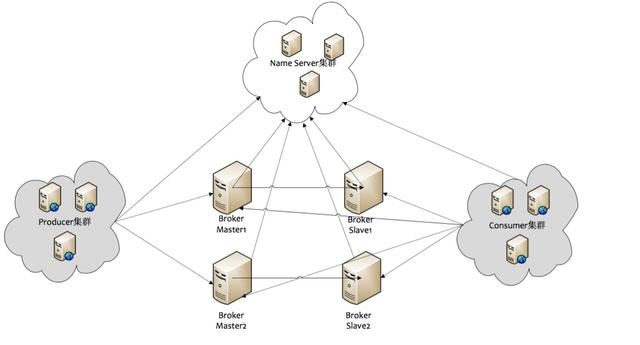
1)NameServer:主要负责对于源数据的管理,包括了对于Topic和路由信息的管理。
NameServer是⼀个功能⻬全的服务器,其⻆⾊类似Dubbo中的Zookeeper,但NameServer与Zookeeper相⽐更轻量。主要是因为每个NameServer节点互相之间是独⽴的,没有任何信息交互。
备注:下⾯的消息类型有Topic的介绍。
2)Producer
消息⽣产者,负责产⽣消息,⼀般由业务系统负责产⽣消息。
- Producer由⽤户进⾏分布式部署,消息由Producer通过多种负载均衡模式发送到Broker集群,发送低延时,⽀持快速失败。
3 )Broker
消息中转⻆⾊,负责存储消息,转发消息。
Broker是具体提供业务的服务器,单个Broker节点与所有的NameServer节点保持⻓连接及⼼跳,并会定时将Topic信息注册到NameServer,顺带⼀提底层的通信和连接都是基于Netty实现的。
Broker负责消息存储,以Topic为纬度⽀持轻量级的队列,单机可以⽀撑上万队列规模,⽀持消息推拉模型。
官⽹上有数据显示:具有上亿级消息堆积能⼒,同时可严格保证消息的有序性。
4)Consumer
消息消费者,负责消费消息,⼀般是后台系统负责异步消费。
- Consumer也由⽤户部署,⽀持PUSH和PULL两种消费模式,⽀持集群消费和⼴播消息,提供实时的消息订阅机制。
5)⼤致流程
Broker在启动的时候会去向NameServer注册并且定时发送⼼跳,Producer在启动的时候会到NameServer上去拉取Topic所属的Broker具体地址,然后向具体的Broker发送消息。具体如下图:
# 2.RocketMQ的消息领域模型
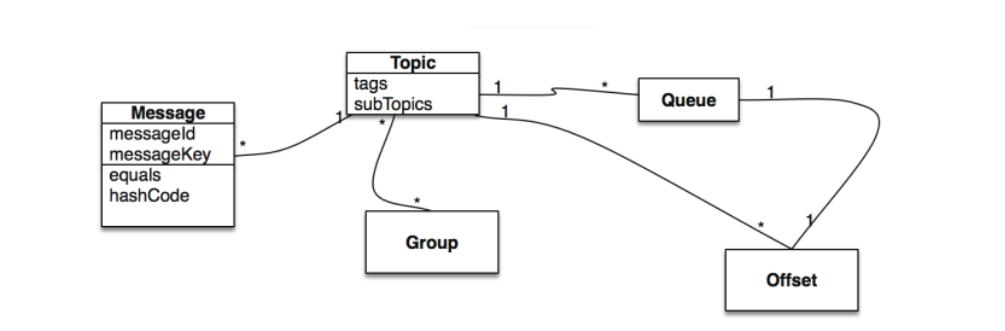
主要分为Message、Topic、Queue、Offset以及Group这⼏部分。
1)Topic
Topic表示消息的第⼀级类型,⽐如⼀个电商系统的消息可以分为:交易消息、物流消息等。⼀条消息必须有⼀个Topic。
最细粒度的订阅单位,⼀个Group可以订阅多个Topic的消息。
2)Tag
Tag表示消息的第⼆级类型,⽐如交易消息⼜可以分为:交易创建消息,交易完成消息等。RocketMQ提
供2级消息分类,⽅便灵活控制。
3)Group
组,⼀个组可以订阅多个Topic。
4)Message Queue
消息的物理管理单位。⼀个Topic下可以有多个Queue,Queue的引⼊使得消息的存储可以分布式集群化,具有了⽔平扩展能⼒。
在RocketMQ 中,所有消息队列都是持久化,⻓度⽆限的数据结构,所谓⻓度⽆限是指队列中的每个存储单元都是定⻓,访问其中的存储单元使⽤Offset 来访问,offset 为 java long 类型,64 位,理论上在 100年内不会溢出,所以认为是⻓度⽆限。
也可以认为 Message Queue 是⼀个⻓度⽆限的数组,Offset 就是下标。
# RocketMQ的关键特性
# 1.消息的顺序
消息的顺序指的是消息消费时,能按照发送的顺序来消费。例如:⼀个订单产⽣了 3 条消息,分别是订单创建、订单付款、订单完成。消费时,要按照这个顺序消费才有意义。但同时订单之间⼜是可以并⾏消费的。
RocketMQ是通过将“相同ID的消息发送到同⼀个队列,⽽⼀个队列的消息只由⼀个消费者处理“来实现顺序消息。如下图:
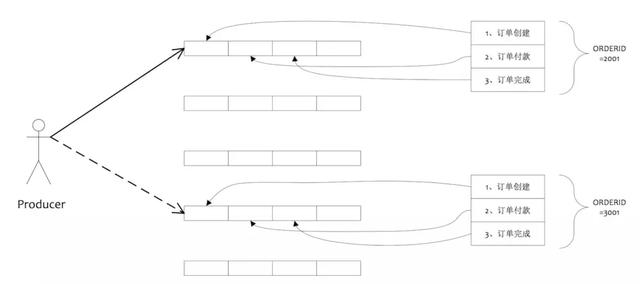
这样对于同⼀个订单的创建、付款和完成消息,确保按照这⼀顺序被发送和消费。
# 2.消息重复
1)消息重复的原因
消息领域有⼀个对消息投递的QoS定义,分为:
最多⼀次(At most once)
⾄少⼀次(At least once)
仅⼀次( Exactly once)
QoS:Quality of Service,服务质量
⼏乎所有的MQ产品都声称⾃⼰做到了At least once。既然是⾄少⼀次,那避免不了消息重复,尤其是在分布式⽹络环境下。⽐如:⽹络原因闪断,
ACK返回失败等等故障,确认信息没有传送到消息队列,导致消息队列不知道⾃⼰已经消费过该消息了,再次将该消息分发给其他的消费者。
不同的消息队列发送的确认信息形式不同,例如RabbitMQ是发送⼀个ACK确认消息,RocketMQ是返回⼀个CONSUME_SUCCESS成功标志,kafka实际上有个offset的概念。
RocketMQ没有内置消息去重的解决⽅案,最新版本是否⽀持还需确认。
2)消息去重
1)去重原则:使⽤业务端逻辑保持幂等性
幂等性:就是⽤户对于同⼀操作发起的⼀次请求或者多次请求的结果是⼀致的,不会因为多次点击⽽产⽣了副作⽤,数据库的结果都是唯⼀的,不可变的。
只要保持幂等性,不管来多少条重复消息,最后处理的结果都⼀样,需要业务端来实现。
2)去重策略:保证每条消息都有唯⼀编号(⽐如唯⼀流⽔号),且保证消息处理成功与去重表的⽇志同时出现。
建⽴⼀个消息表,拿到这个消息做数据库的insert操作。给这个消息做⼀个唯⼀主键(primary key)或者唯⼀约束,那么就算出现重复消费的情况,就会导致主键冲突,那么就不再处理这条消息。
# RocketMQ的应⽤场景
# 1.削峰填⾕
⽐如如秒杀等⼤型活动时会带来较⾼的流量脉冲,如果没做相应的保护,将导致系统超负荷甚⾄崩溃。
如果因限制太过导致请求⼤量失败⽽影响⽤户体验,可以利⽤MQ 超⾼性能的消息处理能⼒来解决。
# 2.异步解耦
通过上、下游业务系统的松耦合设计,⽐如:交易系统的下游⼦系统(如积分等)出现不可⽤甚⾄宕机,都不会影响到核⼼交易系统的正常运转。
# 3.顺序消息
与FIFO原理类似,MQ提供的顺序消息即保证消息的先进先出,可以应⽤于交易系统中的订单创建、⽀付、退款等流程。
# 4.分布式事务消息
⽐如阿⾥的交易系统、⽀付红包等场景需要确保数据的最终⼀致性,需要引⼊ MQ 的分布式事务,既实现了系统之间的解耦,⼜可以保证最终的数据⼀致性。
将⼤事务拆分成⼩事务,减少系统间的交互,既⾼效⼜可靠。再利⽤MQ 的可靠传输与多副本技术确保消息不丢,At-Least-Once 特性来最终确保数据的最终⼀致性。
# 扩展内容
分布式消息Kafka的原理、基础架构、使⽤场景
Kafka、RocketMQ、RabbitMQ的优劣势⽐较
详解RPC远程调⽤和消息队列MQ的区别
# Kafka
# 1 Kafka为什么速度这么快?
# 题目描述
Kafka为什么速度这么快? 解题思路
Kafka作为MQ也好,作为存储层也罢,主要是用到两个功能:一个是Producer生产的数据存储到 broker,二是Consumer从broker读取数据。那Kafka的速度快也就从写和读这两大方面考虑。
# 写数据分析
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafka采用了两个技 术, 顺序写入和MMFile
# 顺序写入
磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。在顺序读写的情况下,磁盘的顺序读写速度和内存持平。 因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
而且Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等。如果在内存 做这些操作的时候,一个是JAVA对象的内存开销很大,另一个是随着堆内存数据的增多,JAVA的GC时 间会变得很长,使用磁盘操作有以下几个好处:
1、顺序写入磁盘顺序读写速度超过内存随机读写
2、顺序写入JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题
3、顺序写入系统冷启动后,磁盘缓存依然可用
下图就展示了Kafka是如何写入数据的, 每一个Partition其实都是一个文件 ,收到消息后Kafka会把数 据插入到文件末尾(虚框部分):
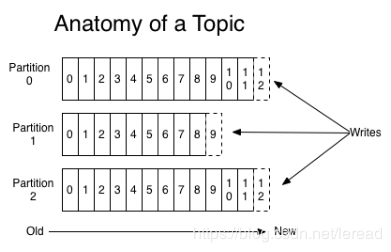
这种方法有一个缺陷——没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留 下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据 。
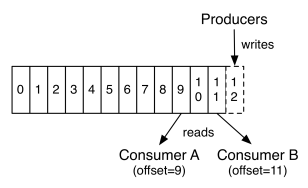
两个消费者
顺序写入Consumer1有两个offset分别对应Partition0、Partition1(假设每一个Topic一个 Partition);
顺序写入Consumer2有一个offset对应Partition2。
这个offset是由客户端SDK负责保存的,Kafka的Broker完全无视这个东西的存在;一般情况下SDK会把 它保存到Zookeeper里面,所以需要给Consumer提供zookeeper的地址。
**如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据: **
顺序写入一是基于时间。
顺序写入二是基于partition文件大小。
具体配置可以参看它的配置文档
# Memory Mapped Files
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
Memory Mapped Files(后面简称mmap)也被翻译成 内存映射文件 ,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。
完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存 为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销(调用文件的read会把 数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)
但也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程 序主动调用flush的时候才把数据真正的写到硬盘。
Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即 flush然后再返回Producer叫 同步 (sync);写入mmap之后立即返回Producer不调用flush叫异步 (async)。
# 读取数据分析
afka在读取磁盘时做了哪些优化?
# 1、基于sendfile实现Zero Copy
传统模式下,当需要对一个文件进行传输的时候,其具体流程细节如下:
1.1、基于sendfile实现Zero Copy调用read函数,文件数据被copy到内核缓冲区
1.2、read函数返回,文件数据从内核缓冲区copy到用户缓冲区
1.3、write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
1.4、数据从socket缓冲区copy到相关协议引擎。
以上细节是传统read/write方式进行网络文件传输的方式,我们可以看到,在这个过程当中,文件数据 实际上是经过了四次copy操作:
硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎 而sendfile系统调用则提供了一种减少以上多次copy,提升文件传输性能的方法。
在内核版本2.1中,引入了sendfile系统调用,以简化网络上和两个本地文件之间的数据传输。sendfile的引入不仅减少了数据复制,还减少了上下文切换。
sendfile(socket, file, len);
运行流程如下:
1、sendfile系统调用,文件数据被copy至内核缓冲区 2、再从内核缓冲区copy至内核中socket相关的缓冲区 3、最后再socket相关的缓冲区copy到协议引擎
相较传统read/write方式,2.1版本内核引进的sendfile已经减少了内核缓冲区到user缓冲区,再由user 缓冲区到socket相关缓冲区的文件copy,而在内核版本2.4之后,文件描述符结果被改变,sendfile实现 了更简单的方式,再次减少了一次copy操作。
在Apache、Nginx、lighttpd等web服务器当中,都有一项sendfile相关的配置,使用sendfile可以大幅 提升文件传输性能。
Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把文件发送给消费 者,配合mmap作为文件读写方式,直接把它传给sendfile。
# 2、批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消 息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要 考虑。
2.1、如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩 而不是单个消息压缩
2.2、Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压 缩格式,直到被消费者解压缩
2.3、Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议
# 应用场景分析
- 消息队列
比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成 为了一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的 端到端延时,并常常依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消 息系统,如ActiveMQ或RabbitMQ。
- 日志收集
日志收集方面,其实开源产品有很多,包括Scribe、Apache Flume。很多人使用Kafka代替 日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一 个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉文件的细节,将其更清晰 地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源 和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高 效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟。
# RabbitMQ
# 如何保证消息的顺序性?
# 面试官心理分析
其实这个也是用 MQ 的时候必问的话题,第一看看你了不了解顺序这个事儿?第二看看你有没有办法保
证消息是有顺序的?这是生产系统中常见的问题。
# 面试题剖析
我举个例子,我们以前做过一个 mysql binlog 同步的系统,压力还是非常大的,日同步数据要达到上亿,就是说数据从一个 mysql 库原封不动地同步到另一个 mysql 库里面去(mysql -> mysql)。常见的一点在于说比如大数据 team,就需要同步一个 mysql 库过来,对公司的业务系统的数据做各种复杂的操作。
你在 mysql 里增删改一条数据,对应出来了增删改 3 条 binlog 日志,接着这三条 binlog 发送到MQ 里面,再消费出来依次执行,起码得保证人家是按照顺序来的吧?不然本来是:增加、修改、删除;你愣是换了顺序给执行成删除、修改、增加,不全错了么。
本来这个数据同步过来,应该最后这个数据被删除了;结果你搞错了这个顺序,最后这个数据保留下来了,数据同步就出错了。
先看看顺序会错乱的俩场景:
RabbitMQ:一个 queue,多个 consumer。比如,生产者向 RabbitMQ 里发送了三条数据,顺序依次是 data1/data2/data3,压入的是 RabbitMQ 的一个内存队列。有三个消费者分别从 MQ中消费这三条数据中的一条,结果消费者2先执行完操作,把 data2 存入数据库,然后是data1/data3。这不明显乱了。
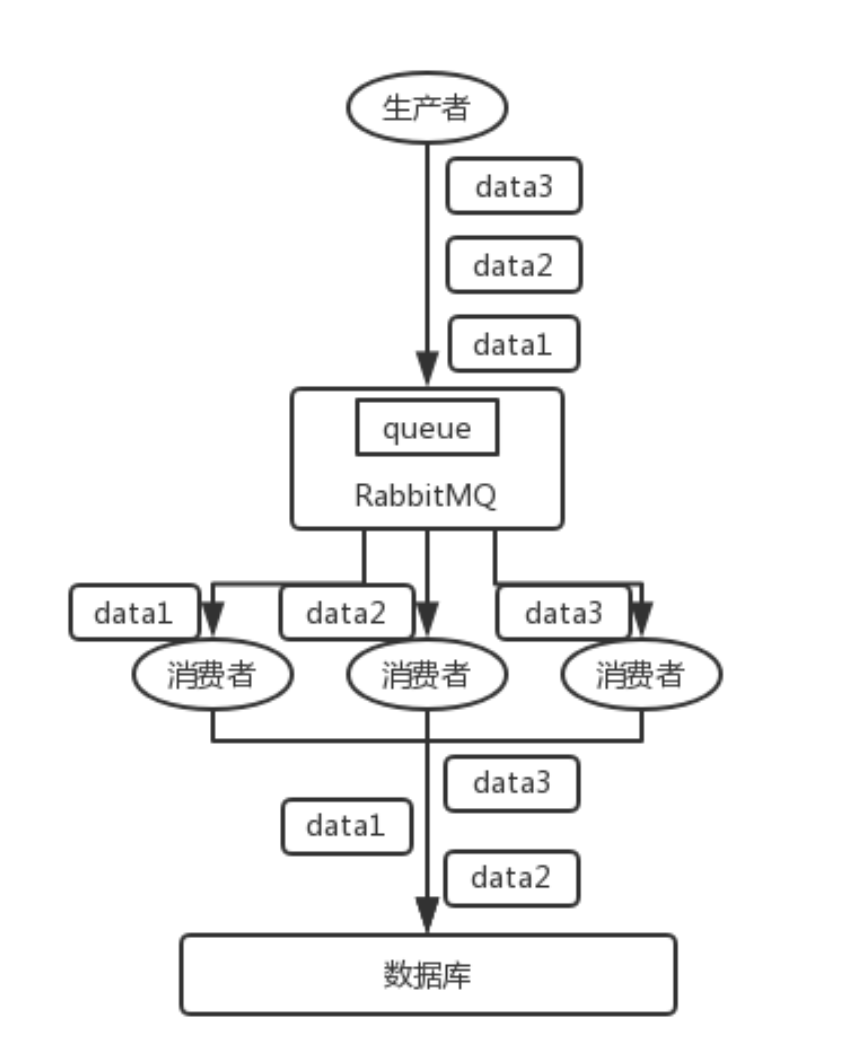
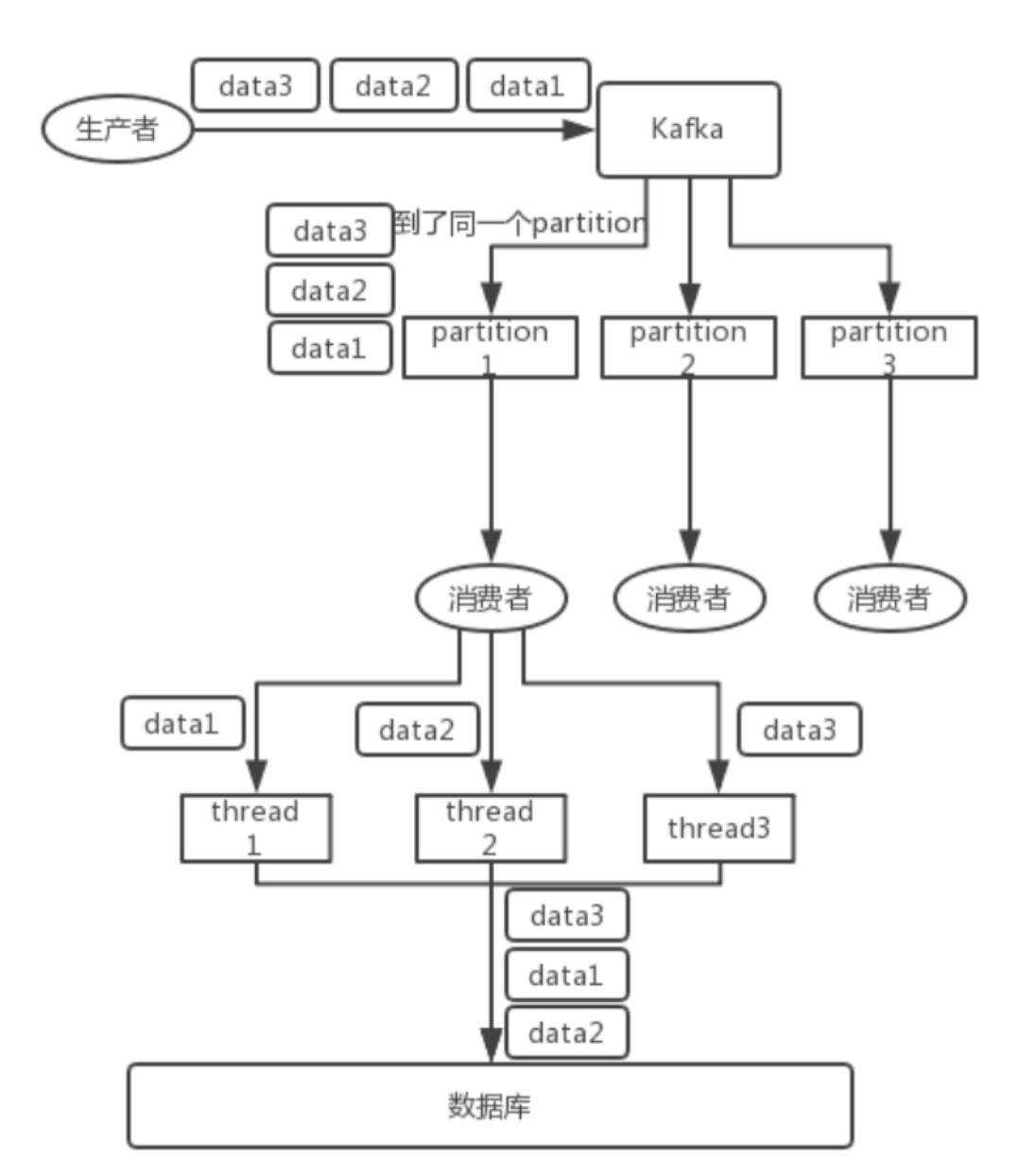
Kafka:比如说我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个partition 中去,而且这个 partition 中的数据一定是有顺序的。
消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,我们在消费者里可能会搞多个线程来并发处理消息。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
# 解决方案
# RabbitMQ
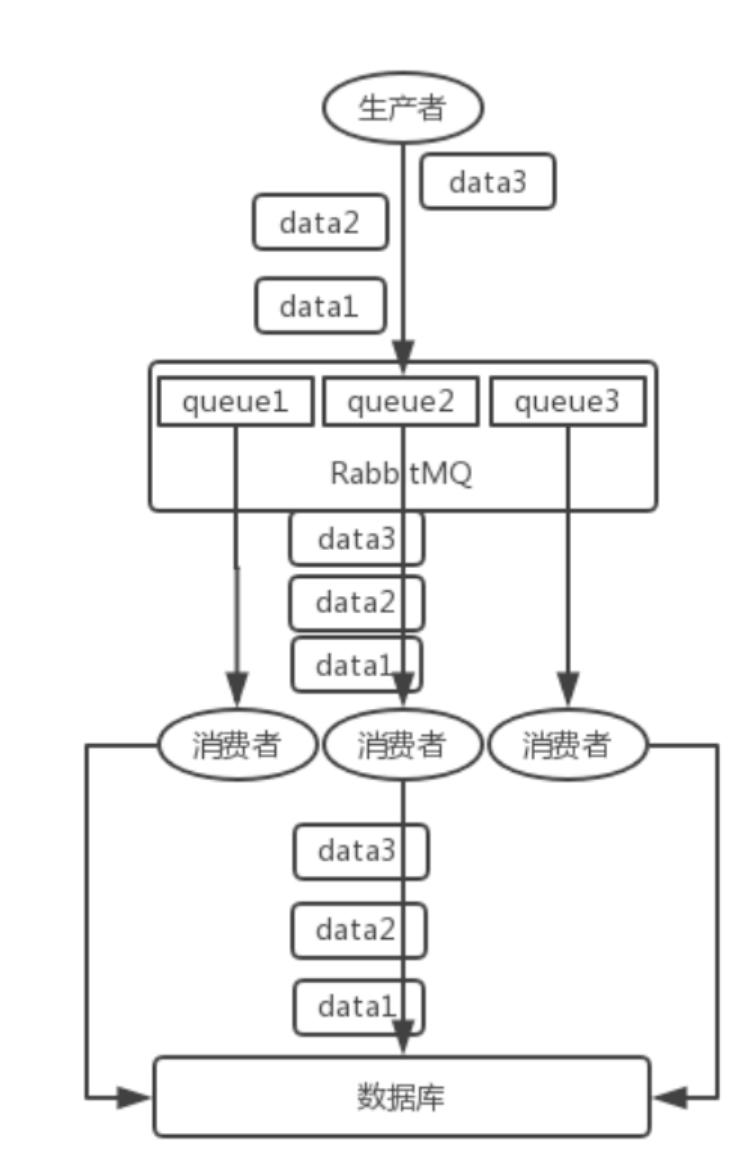
拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点;或者就一个queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
# Kafka
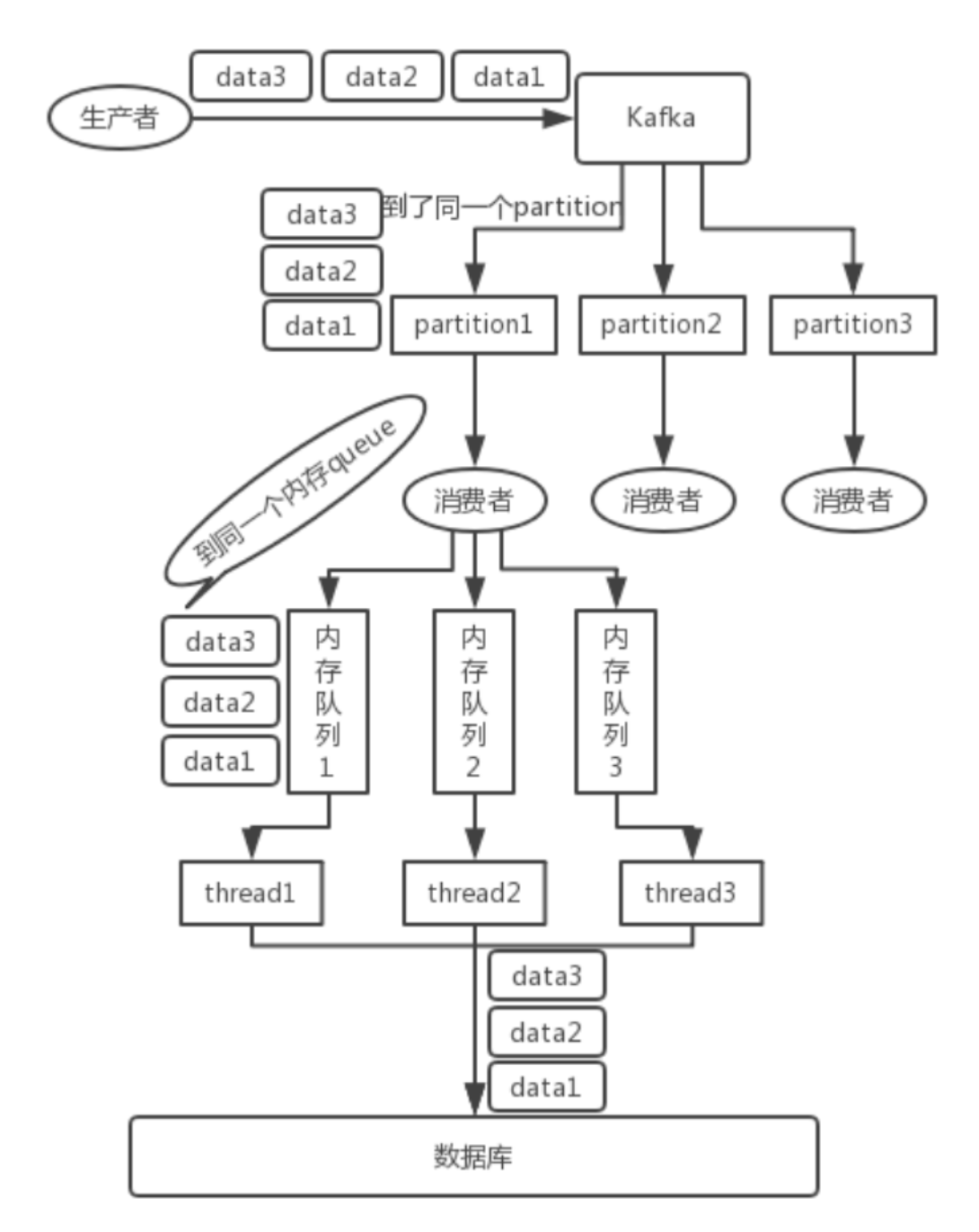
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
# 总结
以上两种解决方案,可根据实际项目中所使用的消息中间件,选择合适的方案来叙述。
# 如何保证消息队列的高可用?
# 面试官心理分析
如果有人问到你 MQ 的知识,高可用是必问的。我们知道,MQ 会导致系统可用性降低。所以只要你用了 MQ,接下来问的一些要点肯定就是围绕着 MQ 的那些缺点怎么来解决了。
要是你傻乎乎的就干用了一个 MQ,各种问题从来没考虑过,那你就悲剧了,面试官对你的感觉就是,只会简单使用一些技术,没任何思考,马上对你的印象就不太好了。这样的同学招进来要是做个 20k 薪资以内的普通小弟还凑合,要是做薪资 20k+ 的高工,那就惨了,让你设计个系统,里面肯定一堆坑,出了事故公司受损失,团队一起背锅。
# 面试题剖析
这个问题这么问是很好的,因为不能问你 Kafka 的高可用性怎么保证?ActiveMQ 的高可用性怎么保证?一个面试官要是这么问就显得很没水平,人家可能用的就是 RabbitMQ,没用过 Kafka,你上来问人家 Kafka 干什么?这不是摆明了刁难人么。
所以有水平的面试官,问的是 MQ 的高可用性怎么保证?这样就是你用过哪个 MQ,你就说说你对那个MQ 的高可用性的理解。
# RabbitMQ 的高可用性
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。
RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
# 单机模式
单机模式,就是 Demo 级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式。
# 普通集群模式(无高可用性)
普通集群模式,意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的queue,只会放在一个RabbitMQ实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。
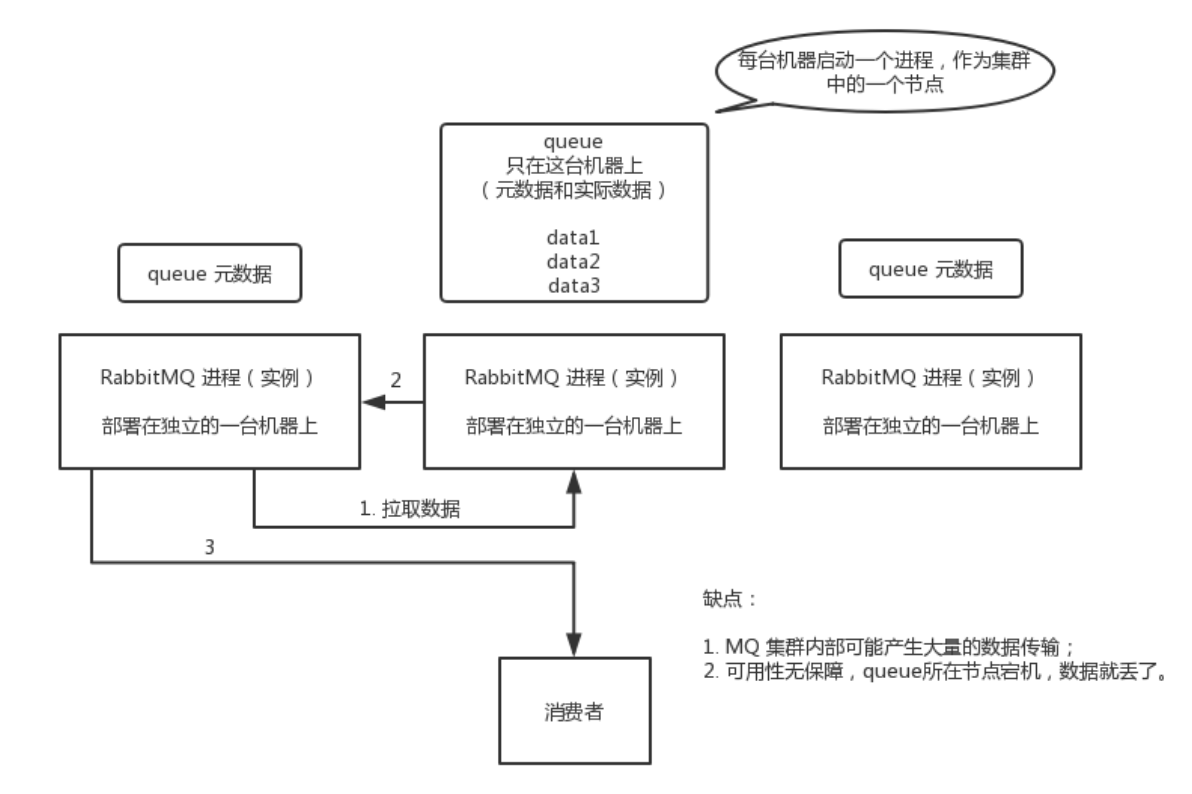
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放 queue 的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让 RabbitMQ 落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个 queue 拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
# 镜像集群模式(高可用性)
这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
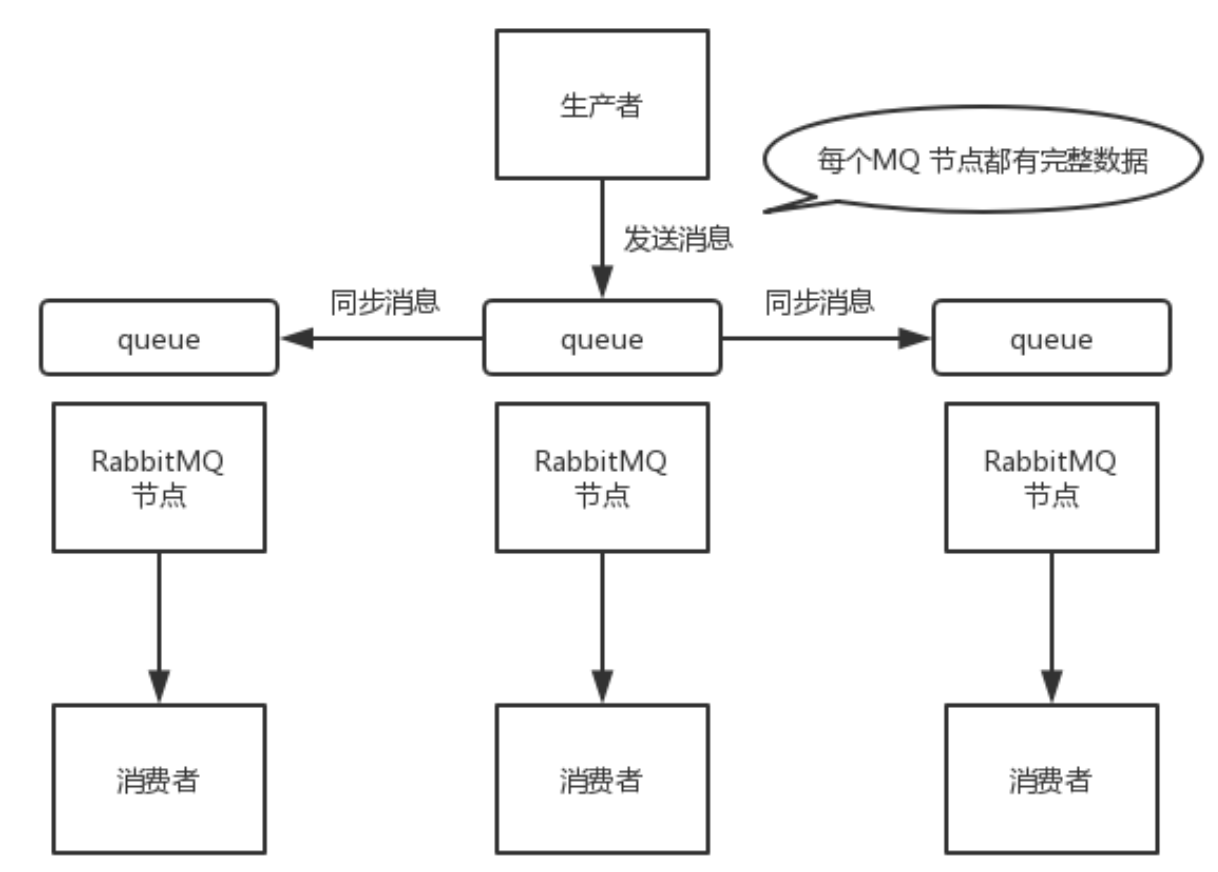
那么如何开启这个镜像集群模式呢?其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!第二,这么玩儿,不是分布式的,就没有扩展性可言了,如果某个 queue 负载很重,你加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展你的 queue。你想,如果这个 queue 的数据量很大,大到这个机器上的容量无法容纳了,此时该怎么办呢?
# Kafka的高可用性
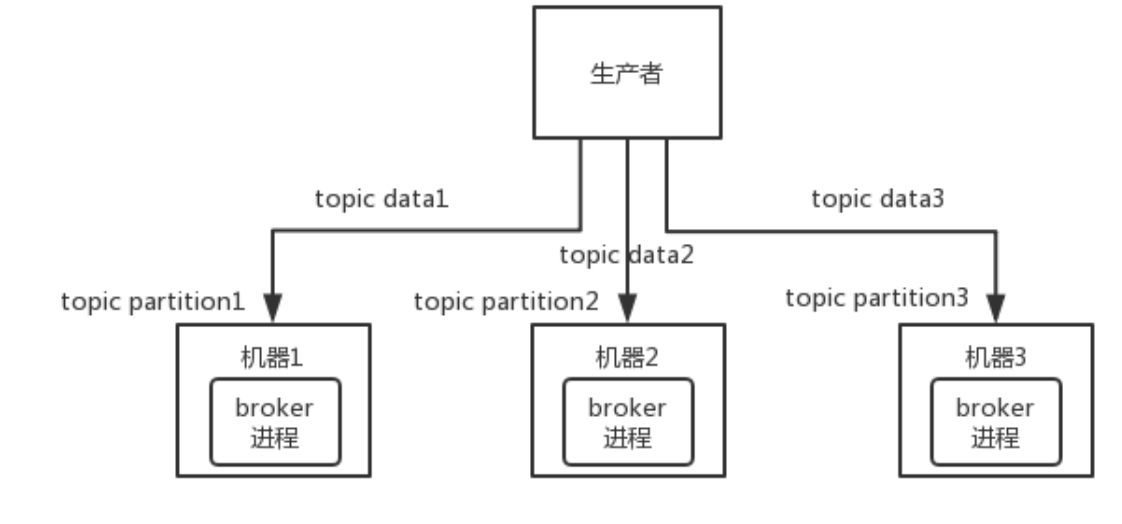
Kafka 一个最基本的架构认识:由多个 broker 组成,每个 broker 是一个节点;你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据。
这就是天然的分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
实际上 RabbitMQ 之类的,并不是分布式消息队列,它就是传统的消息队列,只不过提供了一些集群、HA(High Availability, 高可用性) 的机制而已,因为无论怎么玩儿,RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
Kafka 0.8 以前,是没有 HA 机制的,就是任何一个 broker 宕机了,那个 broker 上的 partition 就废了,没法写也没法读,没有什么高可用性可言。
比如说,我们假设创建了一个 topic,指定其 partition 数量是 3 个,分别在三台机器上。但是,如果第二台机器宕机了,会导致这个 topic 的 1/3 的数据就丢了,因此这个是做不到高可用的。
Kafka 0.8 以后,提供了 HA 机制,就是 replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。只能读写 leader?很简单,要是你可以随意读写每个 follower**,那么就要care数据一致性的问题**,系统复杂度太高,很容易出问题。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
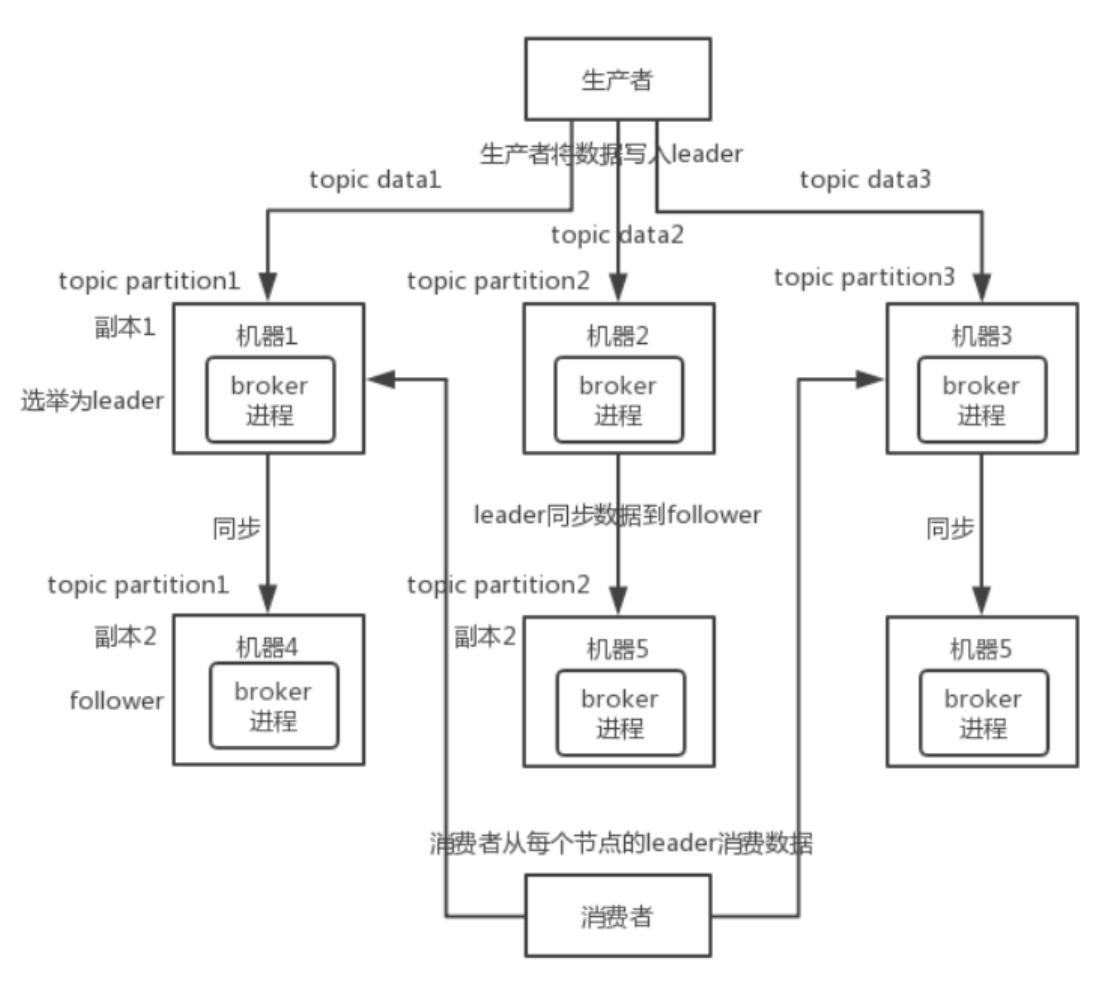
这么搞,就有所谓的高可用性了,因为如果某个 broker 宕机了,没事儿,那个 broker上面的 partition在其他机器上都有副本的。如果这个宕机的 broker 上面有某个 partition 的 leader,那么此时会从follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
# 总结
相信你大致明白了消息队列是如何保证高可用机制的了,对吧?不至于一无所知,现场还能给面试官画画图。要是遇上面试官确实是个中高手,深挖了问,那你只能说不好意思,太深入的你没研究过。
# 什么是流量削峰?如何解决秒杀业务的削峰场景?
# 题目描述
什么是流量削峰?如何解决秒杀业务的削峰场景?
# 流量削峰的由来
主要是还是来自于互联网的业务场景,例如,马上即将开始的春节火车票抢购,大量的用户需要同一时间去抢购;以及大家熟知的阿里双11秒杀,短时间上亿的用户涌入,瞬间流量巨大(高并发),比如:200万人准备在凌晨12:00准备抢购一件商品,但是商品的数量是有限的100-500件左右。
这样真实能购买到该件商品的用户也只有几百人左右, 但是从业务上来说,秒杀活动是希望更多的人来参与,也就是抢购之前希望有越来越多的人来看购买商品。
但是,在抢购时间达到后,用户开始真正下单时,秒杀的服务器后端却不希望同时有几百万人同时发起抢购请求。
我们都知道服务器的处理资源是有限的,所以出现峰值的时候,很容易导致服务器宕机,用户无法访问的情况出现。
这就好比出行的时候存在早高峰和晚高峰的问题,为了解决这个问题,就有了错峰限行的解决方案。
同理,在线上的秒杀等业务场景,也需要类似的解决方案,需要平安度过同时抢购带来的流量峰值的问题,这就是流量削峰的由来。
# 怎样来实现流量削峰方案
削峰从本质上来说就是更多地延缓用户请求,以及层层过滤用户的访问需求,遵从“最后落地到数据库的请求数要尽量少”的原则。
# 1.消息队列解决削峰
要对流量进行削峰,最容易想到的解决方案就是用消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。
结果没想到我们运气居然这么好,碰上个 CEO 带着我们走上了康庄大道,业务发展迅猛,过了几个月,注册用户数达到了 2000 万!每天活跃用户数 100 万!每天单表数据量 10 万条!高峰期每秒最大请求达到 1000!同时公司还顺带着融资了两轮,进账了几个亿人民币啊!公司估值达到了惊人的几亿美金!这是小独角兽的节奏!
好吧,没事,现在大家感觉压力已经有点大了,为啥呢?因为每天多 10 万条数据,一个月就多 300 万条数据,现在咱们单表已经几百万数据了,马上就破千万了。但是勉强还能撑着。高峰期请求现在是1000,咱们线上部署了几台机器,负载均衡搞了一下,数据库撑 1000QPS 也还凑合。但是大家现在开始感觉有点担心了,接下来咋整呢......
再接下来几个月,我的天,CEO 太牛逼了,公司用户数已经达到 1 亿,公司继续融资几十亿人民币啊!公司估值达到了惊人的几十亿美金,成为了国内今年最牛逼的明星创业公司!
但是我们同时也是不幸的,因为此时每天活跃用户数上千万,每天单表新增数据多达 50 万,目前一个表总数据量都已经达到了两三千万了!扛不住啊!数据库磁盘容量不断消耗掉!高峰期并发达到惊人的5000~8000 !你的系统肯定支撑不到现在,已经挂掉了!
好吧,所以你看到这里差不多就理解分库分表是怎么回事儿了,实际上这是跟着你的公司业务发展走的,你公司业务发展越好,用户就越多,数据量越大,请求量越大,那你单个数据库一定扛不住。
消息队列中间件主要解决应用耦合,异步消息, 流量削锋等问题。常用消息队列系统:目前在生产环境,使用较多的消息队列有 ActiveMQ、RabbitMQ、 ZeroMQ、Kafka、MetaMQ、RocketMQ 等。
在这里,消息队列就像“水库”一样,拦蓄上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的。
具体的消息队列MQ选型和应用场景可以参考分布式之消息队列的特点、选型、及应用场景详解。
# 2.流量削峰漏斗:层层削峰
针对秒杀场景还有一种方法,就是对请求进行分层过滤,从而过滤掉一些无效的请求。
分层过滤其实就是采用“漏斗”式设计来处理请求的。 尽量把数据量和请求量一层一层地过滤和减少了。
1)分层过滤的核心思想
通过在不同的层次尽可能地过滤掉无效请求。
通过CDN过滤掉大量的图片,静态资源的请求。
再通过类似Redis这样的分布式缓存,过滤请求等就是典型的在上游拦截读请求。
2)分层过滤的基本原则
对写数据进行基于时间的合理分片,过滤掉过期的失效请求。
对写请求做限流保护,将超出系统承载能力的请求过滤掉。
涉及到的读数据不做强一致性校验,减少因为一致性校验产生瓶颈的问题。
对写数据进行强一致性校验,只保留最后有效的数据。
最终,让“漏斗”最末端(数据库)的才是有效请求。例如:当用户真实达到订单和支付的流程,这个是需要数据强一致性的。
# 流量削峰总结
1.对于秒杀这样的高并发场景业务,最基本的原则就是将请求拦截在系统上游,降低下游压力。如果不在前端拦截很可能造成数据库(mysql、oracle等)读写锁冲突,甚至导致死锁,最终还有可能出现雪崩等场景。
2.划分好动静资源,静态资源使用CDN进行服务分发。
3.充分利用缓存(redis等):增加QPS,从而加大整个集群的吞吐量。
4.高峰值流量是压垮系统很重要的原因,所以需要Kafka等消息队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。
# 为什么使用消息队列?
# 题目描述
面试官有时在面试中会直接问你:在你的项目中看到使用了消息队列,你能给我说下你们为什么使用MQ吗?
# 面试官心理分析(解题思维方向)
面试官的实际想听的:
你知不知道你们系统为什么加消息队列这个东西。
在面试中有不少人会这么说,自己项目里用了 Redis、MQ,但是其实他并不知道自己为什么要用这个东西。说白了,就是为了用而用,或者是别人设计的架构,他从头到尾都没思考过。 没有对自己的架构问过为什么的人,一定是平时没有思考的人,面试官对这类候选人印象通常很不好。因为面试官担心你进了团队之后只会木头木脑的干呆活儿,不会自己思考。
# 面试题剖析
为什么使用消息队列
其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么?
面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务场景有个什么技术挑战,如果不用 MQ 可能会很麻烦,但是你现在用了 MQ 之后带给了你很多的好处。
要回答这个问题,我们得先说一下消息队列常见的使用场景,其实场景有很多,但是比较核心的只有 3个:解耦、异步、削峰。
解耦
假设有这么个场景。A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?
在这个场景中,A 系统跟其它各种系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A系统将这个数据发送过来。A 系统要时时刻刻考虑 BCDE 四个系统如果挂了该咋办?要不要重发,要不要把消息存起来?
如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。
削峰
每天 0:00 到 12:00,A 系统风平浪静,每秒并发请求数量就 50 个。结果每次一到 12:00 ~ 13:00 ,每秒并发请求数量突然会暴增到 5k+ 条。但是系统是直接基于 MySQL 的,大量的请求涌入 MySQL,每秒钟对 MySQL 执行约 5k 条 SQL。
一般的 MySQL,扛到每秒 2k 个请求就差不多了,如果每秒请求到 5k 的话,可能就直接把 MySQL 给打死了,导致系统崩溃,用户也就没法再使用系统了。
但是高峰期一过,到了下午的时候,就成了低峰期,可能也就 1w 的用户同时在网站上操作,每秒中的请求数量可能也就 50 个请求,对整个系统几乎没有任何的压力。
如果使用 MQ,每秒 5k 个请求写入 MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok,这样下来,哪怕是高峰期的时候,A 系统也绝对不会挂掉。而 MQ 每秒钟 5k 个请求进来,就 2k 个请求出去,结果就导致在中午高峰期(1 个小时),可能有几十万甚至几百万的请求积压在 MQ 中。
这个短暂的高峰期积压是 ok 的,因为高峰期过了之后,每秒钟就 50 个请求进 MQ,但是 A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要高峰期一过,A 系统就会快速将积压的消息给解决掉。
异步
A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 5ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求,等待个 1s,这几乎是不可接受的。
一般互联网类的企业,对于用户直接的操作,一般要求是每个请求都必须在 200 ms 以内完成,对用户几乎是无感知的。
如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms,对于用户而言,其实感觉上就是点个按钮,8ms 以后就直接返回了!
# 考题变形
在开发中为什么要使用消息队列
消息队列有什么好处
消息队列的使用场景
# 面试技巧:
你需要去考虑一下你负责的系统中是否有类似的场景,就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用 MQ 给它异步化解耦,也是可以的,你就需要去考虑在你的项目里,是不是可以运用这个MQ 去进行系统的解耦。在简历中体现出来这块东西,用 MQ 作解耦。
# 总结
综上所述,如果在当前系统中有以上几点需求时会使用消息队列来进行系统中的性能优化,用以提升用
户体验度、满意度。那么有必要用当前系统中的一个使用案例来描述一下,说明当时决定使用MQ时的
原因,主要使用MQ的哪个特性。如果能加上使用后的提升情况那就更好了。
# 延伸面试题
Kafka、RabbitMQ、RocketMQ 都有什么区别,以及适合哪些场景?
# RabbitMQ 怎么对消息确认机制的
# 问题回顾
在使用RabbitMQ的时候,我们可以通过消息持久化操作来解决因为服务器的异常奔溃导致的消息丢失,除此之外我们还会遇到一个问题,当消息的发布者在将消息发送出去之后,消息到底有没有正确到达broker代理服务器呢?如果不进行特殊配置的话,默认情况下发布操作是不会返回任何信息给生产者的,也就是默认情况下我们的生产者是不知道消息有没有正确到达broker的,如果在消息到达broker之前已经丢失的话,持久化操作也解决不了这个问题,因为消息根本就没到达代理服务器,你怎么进行持久化,那么这个问题该怎么解决呢?
# 解决方式
RabbitMQ为我们提供了两种方式:
- 通过AMQP事务机制实现,这也是AMQP协议层面提供的解决方案;
- 通过将channel设置成confirm模式来实现;
# 事务机制
RabbitMQ中与事务机制有关的方法有三个:txSelect(), txCommit()以及txRollback(), txSelect用于将当前channel设置成transaction模式,txCommit用于提交事务,txRollback用于回滚事务,在通过txSelect开启事务之后,我们便可以发布消息给broker代理服务器了,如果txCommit提交成功了,则消息一定到达了broker了,如果在txCommit执行之前broker异常崩溃或者由于其他原因抛出异常,这个时候我们便可以捕获异常通过txRollback回滚事务了。
# 关键代码:
channel.txSelect();
channel.basicPublish(ConfirmConfig.exchangeName, ConfirmConfig.routingKey,
MessageProperties.PERSISTENT_TEXT_PLAIN, ConfirmConfig.msg_10B.getBytes());
channel.txCommit();
2
3
4
# 结果展示
- 带事务的
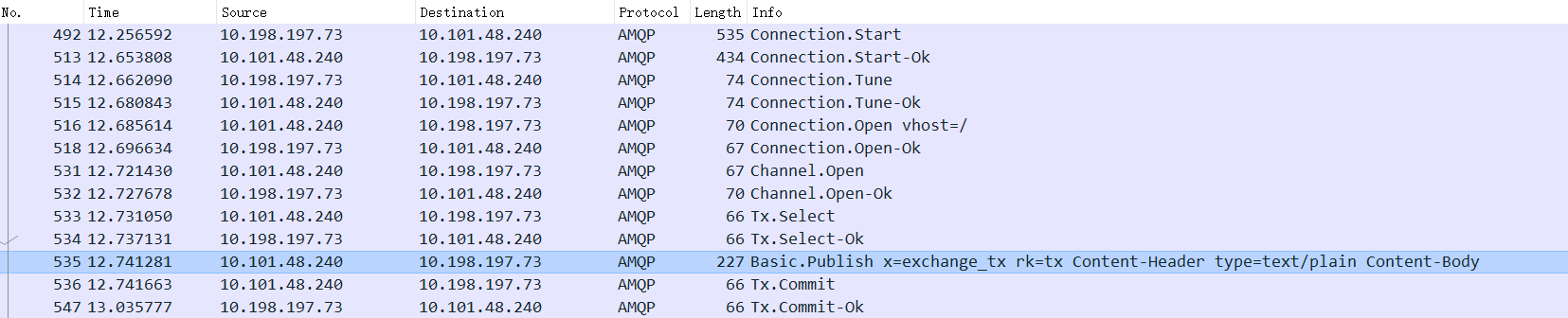
- 不带事务的

可以看到带事务的多了四个步骤:
client发送Tx.Select
broker发送Tx.Select-Ok(之后publish)
client发送Tx.Commit
broker发送Tx.Commit-Ok
# 事务回滚
下面我们来看下事务回滚是什么样子的。关键代码如下:
try {
channel.txSelect();
channel.basicPublish(exchange, routingKey,
MessageProperties.PERSISTENT_TEXT_PLAIN, msg.getBytes());
int result = 1 / 0;
channel.txCommit();
} catch (Exception e) {
e.printStackTrace();
channel.txRollback();
}
2
3
4
5
6
7
8
9
10
数据展示
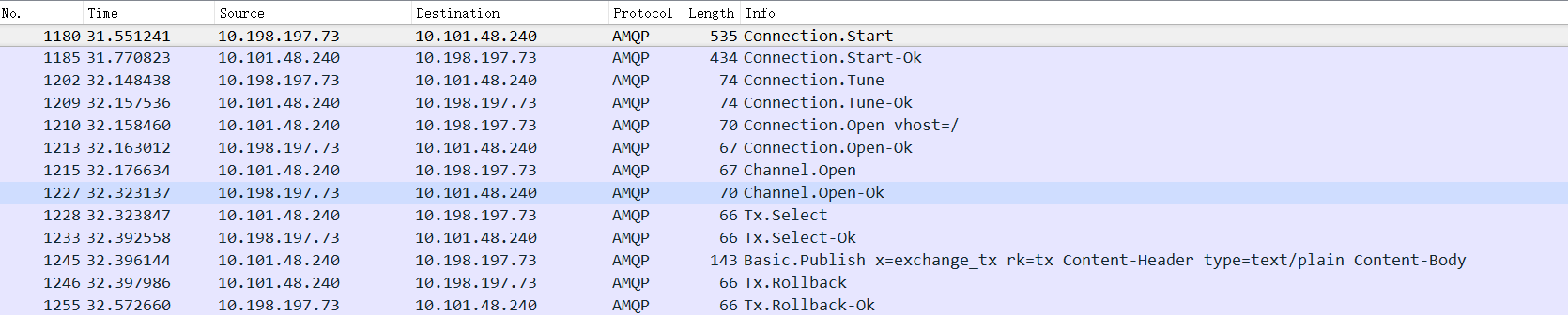
代码中先是发送了消息至broker中但是这时候发生了异常,之后在捕获异常的过程中进行事务回滚。
# 总结
事务确实能够解决producer与broker之间消息确认的问题,只有消息成功被broker接受,事务提交才能成功,否则我们便可以在捕获异常进行事务回滚操作同时进行消息重发,但是使用事务机制的话会降低RabbitMQ的性能,那么有没有更好的方法既能保障producer知道消息已经正确送到,又能基本上不带来性能上的损失呢?从AMQP协议的层面看是没有更好的方法,但是RabbitMQ提供了一个更好的方案,即将channel信道设置成confirm模式。
# 存在的问题
生成者不知道消息是否真正到达broker,随后通过AMQP协议层面为我们提供了事务机制解决了这个问题,但是采用事务机制实现会降低RabbitMQ的消息吞吐量,那么有没有更加高效的解决方式呢
# Confirm模式
# producer端confirm模式的实现原
生产者将信道设置成confirm模式,一旦信道进入confirm模式,所有在该信道上面发布的消息都会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,broker就会发送一个确认给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了,如果消息和队列是可持久化的,那么确认消息会将消息写入磁盘之后发出,broker回传给生产者的确认消息中deliver-tag域包含了确认消息的序列号,此外broker也可以设置basic.ack的multiple域,表示到这个序列号之前的所有消息都已经得到了处理。
confirm模式最大的好处在于他是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,如果RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息,生产者应用程序同样可以在回调方法中处理该nack消息。
在channel 被设置成 confirm 模式之后,所有被 publish 的后续消息都将被 confirm(即 ack) 或者被nack一次。但是没有对消息被 confirm 的快慢做任何保证,并且同一条消息不会既被 confirm又被nack 。
# 开启confirm模式的方法
生产者通过调用channel的confirmSelect方法将channel设置为confirm模式,如果没有设置no-wait标志的话,broker会返回confirm.select-ok表示同意发送者将当前channel信道设置为confirm模式(从目前RabbitMQ最新版本3.6来看,如果调用了channel.confirmSelect方法,默认情况下是直接将no-wait设置成false的,也就是默认情况下broker是必须回传confirm.select-ok的)。
# 编码部分
- 第一种普通confirm模式
简单 每发送一条消息后,调用waitForConfirms()方法,等待服务器端confirm。实际上是一种串行confirm了。。
关键代码如下:
channel.basicPublish(ConfirmConfig.exchangeName, ConfirmConfig.routingKey,
MessageProperties.PERSISTENT_TEXT_PLAIN, ConfirmConfig.msg_10B.getBytes());
if(!channel.waitForConfirms()){
System.out.println("send message failed.");
}
2
3
4
5
- 第二种 批量confirm模式
稍微复杂一点 每发送一批消息后,调用waitForConfirms()方法,等待服务器端confirm。客户端程序需要定期(每隔多少秒)或者定量(达到多少条)或者两则结合起来publish消息,然后等待服务器端confirm, 相比普通confirm模式,批量极大提升confirm效率,但是问题在于一旦出现confirm返回false或者超时的情况时,客户端需要将这一批次的消息全部重发,这会带来明显的重复消息数量,并且,当消息经常丢失时,批量confirm性能应该是不升反降的。
关键代码:
channel.confirmSelect();
for(int i=0;i<batchCount;i++){
channel.basicPublish(ConfirmConfig.exchangeName, ConfirmConfig.routingKey,
MessageProperties.PERSISTENT_TEXT_PLAIN, ConfirmConfig.msg_10B.getBytes());
}
if(!channel.waitForConfirms()){
System.out.println("send message failed.");
}
2
3
4
5
6
7
8
9
10
- 第三种异步confirm模式
最复杂 提供一个回调方法,服务端confirm了一条或者多条消息后Client端会回调这个方法。
Channel对象提供的ConfirmListener()回调方法只包含deliveryTag(当前Chanel发出的消息序号),我们需要自己为每一个Channel维护一个unconfirm的消息序号集合,每publish一条数据,集合中元素加1,每回调一次handleAck方法,unconfirm集合删掉相应的一条(multiple=false)或多条(multiple=true)记录。从程序运行效率上看,这个unconfirm集合最好采用有序集合SortedSet存储结构。实际上,SDK中的waitForConfirms()方法也是通过SortedSet维护消息序号的。
关键代码:
SortedSet<Long> confirmSet = Collections.synchronizedSortedSet(new TreeSet<Long>());
channel.confirmSelect();
channel.addConfirmListener(new ConfirmListener() {
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
if (multiple) {
confirmSet.headSet(deliveryTag + 1).clear();
} else {
confirmSet.remove(deliveryTag);
}
}
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("Nack, SeqNo: " + deliveryTag + ", multiple:" + multiple);
if (multiple) {
confirmSet.headSet(deliveryTag + 1).clear();
} else {
confirmSet.remove(deliveryTag);
}
}
});
while (true) {
long nextSeqNo = channel.getNextPublishSeqNo();
channel.basicPublish(ConfirmConfig.exchangeName,
ConfirmConfig.routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN,
ConfirmConfig.msg_10B.getBytes());
confirmSet.add(nextSeqNo);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 性能测试
Client端机器和RabbitMQ机器配置:CPU:24核,2600MHZ, 64G内存,1TB硬盘。
Client端发送消息体大小10B,线程数为1即单线程,消息都持久化处理(deliveryMode:2)。
分别采用事务模式、普通confirm模式,批量confirm模式和异步confirm模式进行producer实验,比对各个模式下的发送性能。
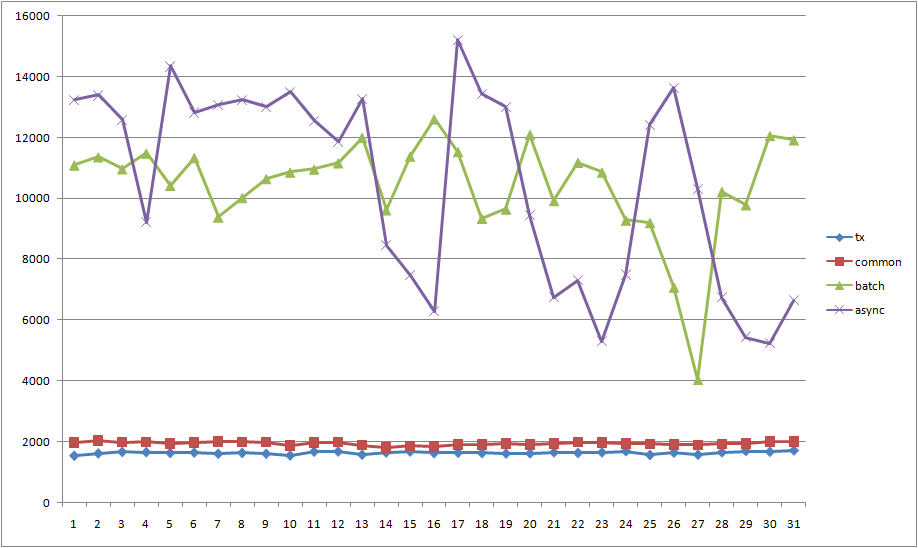
发送平均速率:
事务模式(tx):1637.484
普通confirm模式(common):1936.032
批量confirm模式(batch):10432.45
异步confirm模式(async):10542.06
# 总结
可以看到事务模式性能是最差的,普通confirm模式性能比事务模式稍微好点,但是和批量confirm模式还有异步confirm模式相比,还是小巫见大巫。批量confirm模式的问题在于confirm之后返回false之后进行重发这样会使性能降低,异步confirm模式(async)编程模型较为复杂,至于采用哪种方式,那是仁者见仁智者见智了。
# 如何保证RabbitMq消息不丢失
# 题⽬描述
如何保证RabbitMq消息不丢失
# 解题思路
⾯试官问题可以从⼏个⽅⾯来回答:消息丢失的场景,如何防⽌消息丢失
# 丢失消息的场景
# 1.成产者弄丢了数据
⽣产者将数据发送到rabbitmq的时候,可能在传输过程中因为⽹络等问题⽽将数据弄丢了。
# 2.RabbitMq⾃⼰丢失了数据
如果没有开启rabbitmq的持久化,那么rabbitmq⼀旦重启,那么数据就丢了。所依必须开启持久化将消息持久化到磁盘,这样就算rabbitmq挂了,恢复之后会⾃动读取之前存储的数据,⼀般数据不会丢失。除⾮极其罕⻅的情况,rabbitmq还没来得及持久化⾃⼰就挂了,这样可能导致⼀部分数据丢失。
# 3.消费端丢失了数据
主要是因为消费者消费时,刚消费到,还没有处理,结果消费者就挂了,这样你重启之后,rabbitmq就认为你已经消费过了,然后就丢了数据。
# 如何防⽌消息丢失
# 1.⽣产者丢失消息
可以选择使⽤rabbitmq提供是事物功能,就是⽣产者在发送数据之前开启事物,然后发送消息,如果消息没有成功被rabbitmq接收到,那么⽣产者会受到异常报错,这时就可以回滚事物,然后尝试重新发送;如果收到了消息,那么就可以提交事物。
缺点:rabbitmq事物已开启,就会变为同步阻塞操作,⽣产者会阻塞等待是否发送成功,太耗性能会造成吞吐量的下降。
可以开启confirm模式。在⽣产者哪⾥设置开启了confirm模式之后,每次写的消息都会分配⼀个唯⼀的id,然后如何写⼊了rabbitmq之中,rabbitmq会给你回传⼀个nack消息,告诉你这个消息发送OK了;如果rabbitmq没能处理这个消息,会回调你⼀个nack接⼝,告诉你这个消息失败了,你可以进⾏重试。⽽且你可以结合这个机制知道⾃⼰在内存⾥维护每个消息的id,如果超过⼀定时间还没接收到这个消息的回调,那么你可以进⾏重发。
# 2.RabbitMq⾃⼰丢失了数据
设置消息持久化到磁盘。设置持久化有两个步骤:
①创建queue的时候将其设置为持久化的,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue⾥⾯的数据。
②发送消息的时候讲消息的deliveryMode设置为2,这样消息就会被设为持久化⽅式,此时rabbitmq就会将消息持久化到磁盘上。
必须要同时开启这两个才可以。
⽽且持久化可以跟⽣产的confirm机制配合起来,只有消息持久化到了磁盘之后,才会通知⽣产者ack,这样就算是在持久化之前rabbitmq挂了,数据丢了,⽣产者收不到ack回调也会进⾏消息重发。
# 3.消费者丢失了数据
使⽤rabbitmq提供的ack机制,⾸先关闭rabbitmq的⾃动ack,然后每次在确保处理完这个消息之后,在代码⾥⼿动调⽤ack。这样就可以避免消息还没有处理完就ack。
# 总结
设置了队列和消息的持久化,当 RabbitMQ 服务重启之后,消息依旧会存在;
仅设置队列持久化,重启之后消息会丢失;
仅设置消息持久化,重启之后队列会消失,因此消息也就丢失了,所以只设置消息持久化⽽不设置队列持久化是没有意义的;
将所有的消息都设置为持久化(写⼊磁盘的速度⽐写⼊内存的速度慢的多),可能会影响RabbitMQ 的性能,对于可靠性不是那么⾼的消息可以不采⽤持久化来提⾼ RabbitMQ 的吞吐量。
