 源码剖析-消息存储机制
源码剖析-消息存储机制
# 4.6 Kafka源码剖析之消息存储机制
log.dirs/<topic-name>-<partitionno>/{.index,.timeindex,.log}
1
首先查看Kafka如何处理生产的消息:

调用副本管理器,将记录追加到分区的副本中。
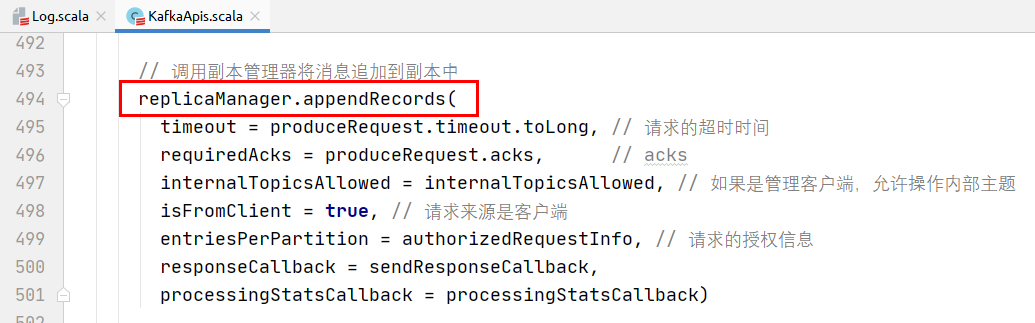
将数据追加到本地的Log日志中:
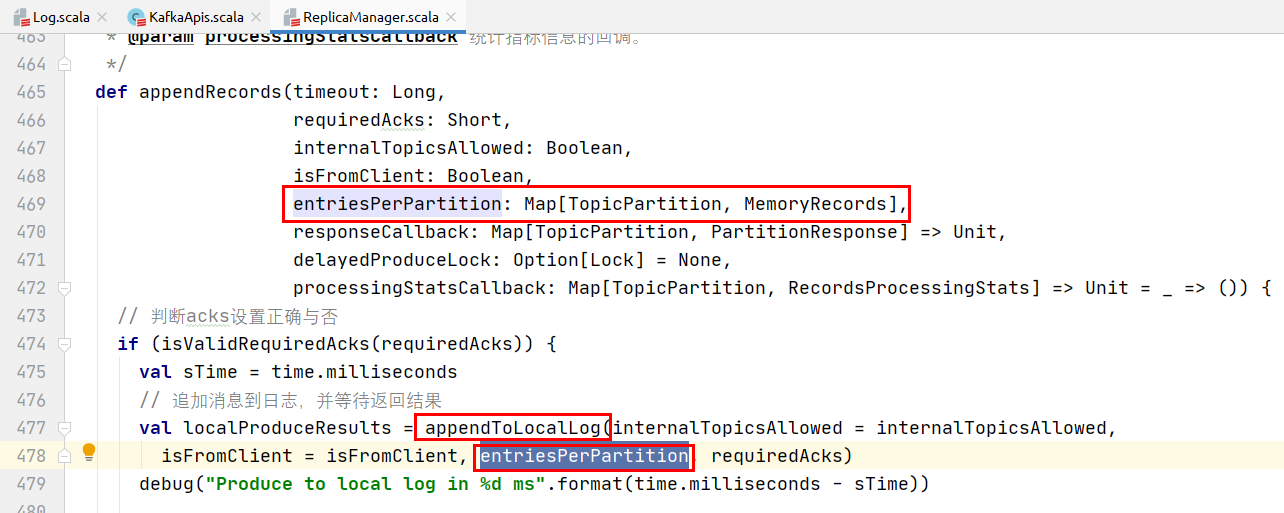
追加消息的实现:

遍历需要追加的每个主题分区的消息:

调用partition的方法将记录追加到该分区的leader分区中:

如果在本地找到了该分区的leader:
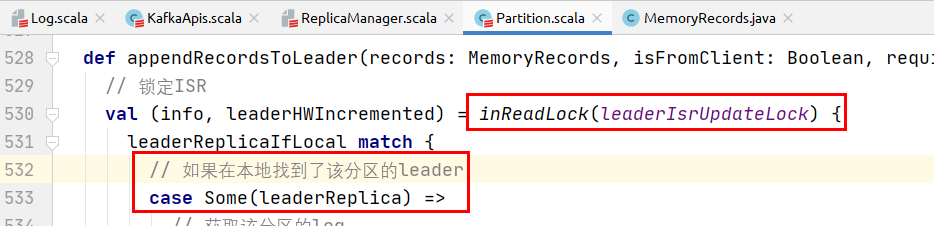
执行下述逻辑将消息追加到leader分区:
// 获取该分区的log
val log = leaderReplica.log.get
// 获取最小ISR副本数
val minIsr = log.config.minInSyncReplicas
// 计算同步副本的个数
val inSyncSize = inSyncReplicas.size
// 如果同步副本的个数小于要求的最小副本数,并且acks设置的是-1,则不追加消息
if (inSyncSize < minIsr && requiredAcks == -1) {
throw new NotEnoughReplicasException("Number of insync replicas for partition %s is [%d], below required minimum [%d]"
.format(topicPartition, inSyncSize, minIsr))
}
// 追加消息到leader
val info = log.appendAsLeader(records, leaderEpoch = this.leaderEpoch,isFromClient)
// 尝试锁定follower获取消息的请求,因为此时leader正在更新LEO。
replicaManager.tryCompleteDelayedFetch(TopicPartitionOperationKey(this.topic, this.partitionId))
// 如果ISR只有一个元素的话,需要HW+1
(info, maybeIncrementLeaderHW(leaderReplica))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
log.appendAsLeader(records, leaderEpoch = this.leaderEpoch, isFromClient)的实现:
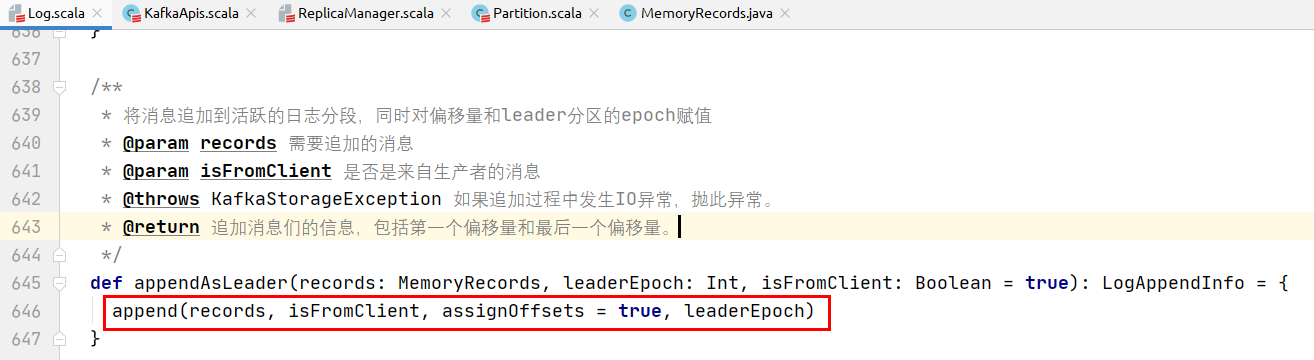
具体代码实现:
/**
* 验证如下信息:
* 每条消息与其CRC是否匹配
* 每条消息的字节数是否匹配
* 传入记录批的序列号与现有状态以及彼此之间是否一致。
* 同时计算如下值:
* 消息批中第一个偏移量
* 消息批中最后一个偏移量
* 消息个数
* 正确字节的个数
* 偏移量是否单调递增
* 是否使用了压缩编码解码器(如果使用了压缩编解码器,则给出最后一个)
*/
val appendInfo = analyzeAndValidateRecords(records, isFromClient =isFromClient)
// 如果没有消息需要追加或该消息集合与上一个消息集合重复,则返回
if (appendInfo.shallowCount == 0)
return appendInfo
// 在向磁盘日志追加之前剔除不正确的字节或剔除不完整的消息
var validRecords = trimInvalidBytes(records, appendInfo)
// 消息集合剩余的正确部分,插入到日志中
lock synchronized {
// 检查日志的MMap是否关闭了,如果关闭无法进行写操作,抛异常
checkIfMemoryMappedBufferClosed()
if (assignOffsets) {
// 如果需要给消息添加偏移量
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = offset.value
val now = time.milliseconds
val validateAndOffsetAssignResult = try {
// 校验消息和赋值给消息的偏移量是否正确无误
LogValidator.validateMessagesAndAssignOffsets(validRecords,
offset,
time,
now,
appendInfo.sourceCodec,
appendInfo.targetCodec,
config.compact,
config.messageFormatVersion.messageFormatVersion.value,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs,
leaderEpoch,
isFromClient)
}
catch {
case e: IOException => throw new KafkaException("Error in validating messages while appending to log '%s'".format(name), e)
}
// 正确的消息集合,此时处于内存中
validRecords = validateAndOffsetAssignResult.validatedRecords
// 要追加消息的最大时间戳
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
// 要追加的消息的最大时间戳对应的偏移量
appendInfo.offsetOfMaxTimestamp =validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp
// 最后一个偏移量是偏移量的值-1
appendInfo.lastOffset = offset.value - 1
appendInfo.recordsProcessingStats =validateAndOffsetAssignResult.recordsProcessingStats
if (config.messageTimestampType == TimestampType.LOG_APPEND_TIME)
// 如果消息时间戳的类型是日志追加的时间,则需要赋值当前系统时间
appendInfo.logAppendTime = now
// 需要重新验证消息的大小,以防消息发生改变,如重新压缩或者转换了消息格式
if (validateAndOffsetAssignResult.messageSizeMaybeChanged) {
for (batch <- validRecords.batches.asScala) {
// 如果消息集合的字节数大于配置的消息最大字节数,抛异常
if (batch.sizeInBytes > config.maxMessageSize) {
// we record the original message set size instead of the trimmed size
// to be consistent with pre-compression bytesRejectedRate recording
brokerTopicStats.topicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes)
brokerTopicStats.allTopicsStats.bytesRejectedRate.mark(records.sizeInBytes)
throw new RecordTooLargeException("Message batch size is %d bytes which exceeds the maximum configured size of %d."
.format(batch.sizeInBytes, config.maxMessageSize))
}
}
}
} else {
// 如果不需要分配消息偏移量,则使用给定的消息偏移量
if (!appendInfo.offsetsMonotonic)
// 如果偏移量不是单调递增的,抛异常
throw new OffsetsOutOfOrderException(s"Out of order offsets found in append to $topicPartition: " + records.records.asScala.map(_.offset))
// 如果消息批的第一个偏移量小于分区leader日志中下一条记录的偏移量,抛异常。
if (appendInfo.firstOffset < nextOffsetMetadata.messageOffset) {
// we may still be able to recover if the log is empty
// one example: fetching from log start offset on the leader which is not batch aligned,
// which may happen as a result of AdminClient#deleteRecords()
// appendInfo.firstOffset maybe either first offset or last offset of the first batch.
// get the actual first offset, which may require decompressing the data
val firstOffset = records.batches.asScala.head.baseOffset()
throw new UnexpectedAppendOffsetException(
s"Unexpected offset in append to $topicPartition. First offset or last offset of the first batch " +
s"${appendInfo.firstOffset} is less than the next offset ${nextOffsetMetadata.messageOffset}. " +
s"First 10 offsets in append: ${records.records.asScala.take(10).map(_.offset)}, last offset in" +
s" append: ${appendInfo.lastOffset}. Log start offset = $logStartOffset",
firstOffset, appendInfo.lastOffset)
}
}
// 使用leader给消息赋值的epoch值更新缓存的epoch值。
validRecords.batches.asScala.foreach {
batch =>
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2)
// 需要在epoch中记录leader的epoch值和消息集合的起始偏移量
leaderEpochCache.assign(batch.partitionLeaderEpoch,batch.baseOffset)
}
// 检查消息批的字节大小是否大于日志分段的最大值,如果是,则抛异常
if (validRecords.sizeInBytes > config.segmentSize) {
throw new RecordBatchTooLargeException("Message batch size is %d bytes which exceeds the maximum configured segment size of %d."
.format(validRecords.sizeInBytes, config.segmentSize))
}
// 消息批的消息都正确,偏移量也都赋值了,时间戳也更新了
// 此时需要验证生产者的幂等性/事务状态,并收集一些元数据
val (updatedProducers, completedTxns, maybeDuplicate) =analyzeAndValidateProducerState(validRecords, isFromClient)
// 如果是重复的消息批,则直接返回被重复的消息批的appendInfo
maybeDuplicate.foreach {
duplicate =>
appendInfo.firstOffset = duplicate.firstOffset
appendInfo.lastOffset = duplicate.lastOffset
appendInfo.logAppendTime = duplicate.timestamp
appendInfo.logStartOffset = logStartOffset
return appendInfo
}
// 如果当前日志分段写满了,则滚动日志分段
val segment = maybeRoll(messagesSize = validRecords.sizeInBytes,
maxTimestampInMessages = appendInfo.maxTimestamp,
maxOffsetInMessages = appendInfo.lastOffset)
val logOffsetMetadata = LogOffsetMetadata(
messageOffset = appendInfo.firstOffset,
segmentBaseOffset = segment.baseOffset,
relativePositionInSegment = segment.size)
// 日志片段中追加消息
segment.append(firstOffset = appendInfo.firstOffset,
largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// 更新生产者状态
for ((producerId, producerAppendInfo) <- updatedProducers) {
producerAppendInfo.maybeCacheTxnFirstOffsetMetadata(logOffsetMetadata)
producerStateManager.update(producerAppendInfo)
}
// update the transaction index with the true last stable offset. The last offset visible
// to consumers using READ_COMMITTED will be limited by this value and the high watermark.
for (completedTxn <- completedTxns) {
val lastStableOffset = producerStateManager.completeTxn(completedTxn)
segment.updateTxnIndex(completedTxn, lastStableOffset)
}
// always update the last producer id map offset so that the snapshot reflects the current offset
// even if there isn't any idempotent data being written
producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1)
// leader的LEO+1
updateLogEndOffset(appendInfo.lastOffset + 1)
// update the first unstable offset (which is used to compute LSO)
updateFirstUnstableOffset()
trace(s"Appended message set to log with last offset ${appendInfo.lastOffset} " +
s"first offset: ${appendInfo.firstOffset}, " +
s"next offset: ${nextOffsetMetadata.messageOffset}, " +
s"and messages: $validRecords")
// 如果未刷盘的消息个数大于配置的消息个数,刷盘
if (unflushedMessages >= config.flushInterval)
// 刷盘
flush()
appendInfo
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
上次更新: 2025/04/03, 11:07:08
