 Elastic-Job高级用法
Elastic-Job高级用法
# 1 Elastic-Job自定义分片策略
分片策略:将一作业任务拆分成若干个分片后,分片按照那种规则分配到服务中。
Elastic-Job官方提供的分片策略:
平均分片(默认策略):将分片平均分配到指定服务中;
eg:有一个作业任务拆分成10个分片,有3个运行服务。
第一个服务:0,1,2,3分片
第二个服务:4,5,6分片
第三个服务:7,8,9分
根据作业名的哈希值的奇偶数决定IP升降序算法的分片策略.
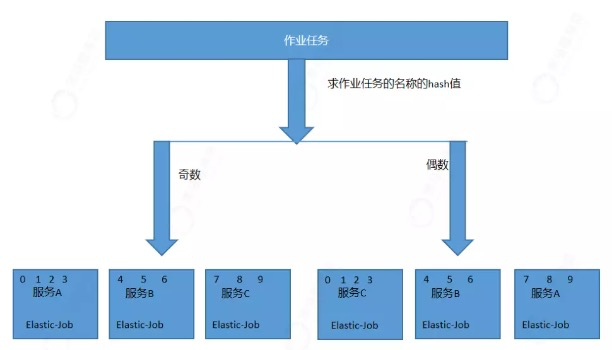
首先会计算作业任务名称的hash值。
判断hash值是奇数还是偶数
奇数:按照ip升序进行平均分片;
偶数:按照ip降序进行平均分片;
根据作业名的哈希值对服务器列表进行轮转的分片策略
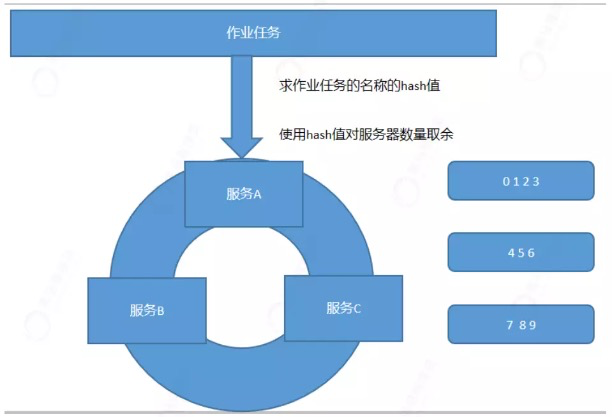
首先会计算作业任务名称的hash值。
对服务数量取余
根据余数决定从哪个服务开始进行平均分片;
自定义分片策略
需求:10个分片,如果有3个服务。
第一个服务[0 3 6 9]
第二个服务[1 4 7]
第三个服务[2 5 8]
(一)定义类实现JobShardingStrategy接口,重写sharding方法
(二)sharding方法中可以获取服务列表,作业任务名称,总分片项
(三)返回Map<服务,分片项集合>
@Override
public Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount) {
if (jobInstances.isEmpty()) {
return Collections.emptyMap();
}
Map<JobInstance,List<Integer>> map = new HashMap<>();
//1.生成分片项的列表
Queue<Integer> queue = new ArrayDeque<>();
for (int i = 0; i < shardingTotalCount; i++) {
// 0 1 2 3 4 5 6 7 8 9
queue.add(i);
}
//1.迭代服务列表
for (int i = 0; i < jobInstances.size(); i++) {
//获取服务
JobInstance jobInstance = jobInstances.get(i);
//获取该服务对应的分片项;
List<Integer> shardingItemList = getShardingItemList(i, jobInstances.size(), queue);
map.put(jobInstance,shardingItemList);
}
System.out.println(map);
return map;
}
private List<Integer> getShardingItemList(int jobInstanceIndex,int size,Queue<Integer> queue) {
//定义jobInstanceIndex 对应的分片列表
List<Integer> shardingItemList = new ArrayList<>();
for (int shardingItem : queue) {
if(shardingItem % size == jobInstanceIndex) {
shardingItemList.add(shardingItem);
}
}
return shardingItemList;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
(四)、使用自定义分片策略
Spring整合Elastic-Job
<job:simple id="mySimpleJob" registry-center-ref="zk" cron="0/10 * * * * ?" sharding-total-count="10" class="cn.itcast.MySimpleJob" overwrite="true" job-sharding-strategy-class="cn.itcast.strategy.MyJobShardingStrategy"></job:simple>
SpringBoot整合Elastic-Job
修改注解,让用户传递分片策略
@Target(ElementType.TYPE) //注解定义位置
@Retention(RetentionPolicy.RUNTIME) //源码 编译 运行都有效
public @interface ElasticSimpleJob {
String name();
String cron();
int shardingTotalCount() default 1;
boolean overwrite() default false;
Class jobShardingStrategyClass() default AverageAllocationJobShardingStrategy.class;
}
2
3
4
5
6
7
8
9
设置分片策略
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(overwrite).jobShardingStrategyClass(jobShardingStrategyClass.getCanonicalName()).build();
@Slf4j
@Component
@ElasticSimpleJob(jobName = "mySimpleJob",corn = "0/5 * * * * ?", shardingTotalCount = 10,overwrite = true)
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
int totalCount = shardingContext.getShardingTotalCount(); //分片总数量
int item = shardingContext.getShardingItem();//当前分片
log.info("作业任务被执行了" + new Date() + "总分片数量" + totalCount + "当前分片:" + item);
}
}
2
3
4
5
6
7
8
9
10
11
# 2 Elastic-Job监听器
概念:监听任务作业执行前和执行后。
可通过配置多个任务监听器,在任务执行前和执行后执行监听的方法。
监听器分类:
同一个作业任务的每个节点都执行的监听器。
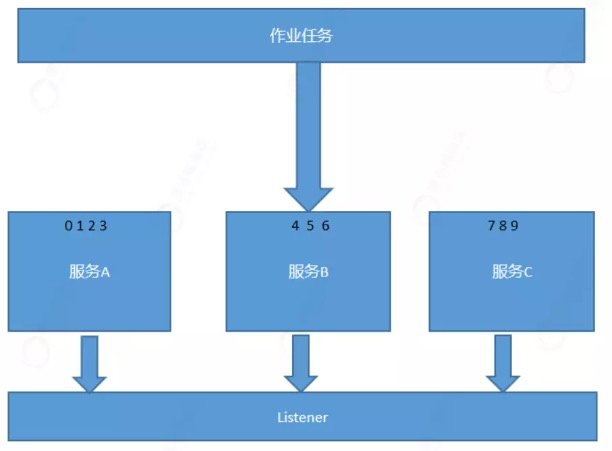
分布式环境中,只在一个节点执行监听器。
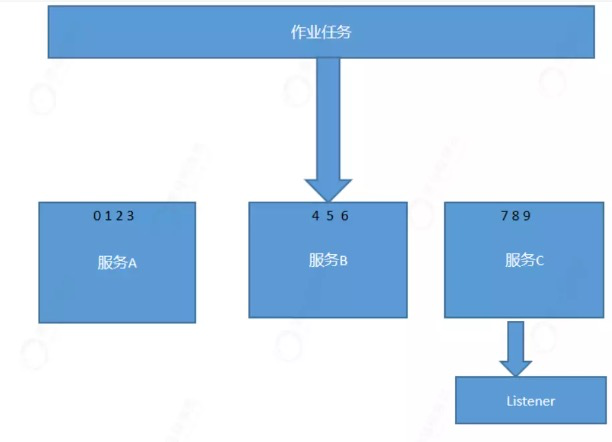
第一类监听器的实现
@Slf4j
public class MyListener implements ElasticJobListener {
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
String jobName = shardingContexts.getJobName();
log.info(jobName + "任务执行之前执行");
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
String jobName = shardingContexts.getJobName();
log.info(jobName + "任务执行之后执行");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
spring整合ElasticJob配置监听器
<job:simple id="mySimpleJob" registry-center-ref="zk" cron="0/10 * * * * ?" sharding-total-count="3"
class="cn.itcast.job.MySimpleJob" overwrite="true" >
<job:listener class="cn.itcast.lisenter.My"lisenter></job:listener>
</job:simple>
2
3
4
spring boot整合ElasticJob
(一)修改ElasticSimpleJob注解,让使用者将需要的listener传递进来
@Retention(RetentionPolicy.RUNTIME) //源码 编译 运行都有效
public @interface ElasticSimpleJob {
String name();
String cron();
int shardingTotalCount() default 1;
boolean overwrite() default false;
Class jobShardingStrategyClass() default
AverageAllocationJobShardingStrategy.class;
Class<? extends ElasticJobListener>[] listeners() default {};
}
2
3
4
5
6
7
8
9
10
配置:修改ElasticSimpleJobConfiguration,传递listener
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(overwrite).jobShardingStrategyClass(jobShardingStrategyClass.getCanonicalName()).build();
ElasticJobListener[] elasticJobListeners = new ElasticJobListener[listeners.length];
for (int i = 0; i < listeners.length; i++) {
elasticJobListeners[i] = (ElasticJobListener)listeners[i].newInstance();
}
new SpringJobScheduler(bean,coordinatorRegistryCenter, simpleJobRootConfig,elasticJobListeners).init();
2
3
4
5
6
分布式环境,只有一个节点监听代码实现:(略)
代码有Bug
# 4 Elastic-Job架构原理
# 4.1 Elastic-Job架构图
下面这张图是Elastic-Job的整体架构图。
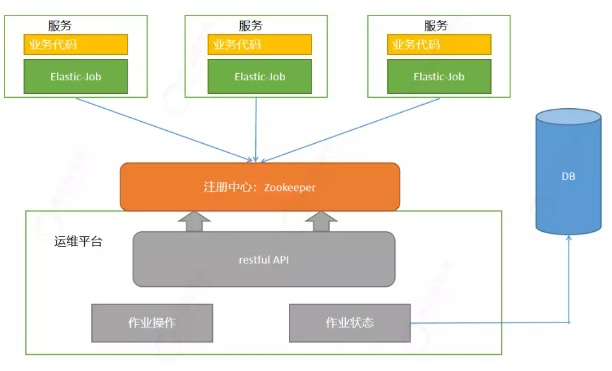
绿色部分:elastic-job的jar包,和应用是部署在一起。
zookeeper:主要完成的工作是服务注册和服务发现。
运维平台:通过使用restful的API,从Zookeeper 获取作业操作和作业状态。发布作业轨迹到数据库或者ELK;
# 4.2 作业分片
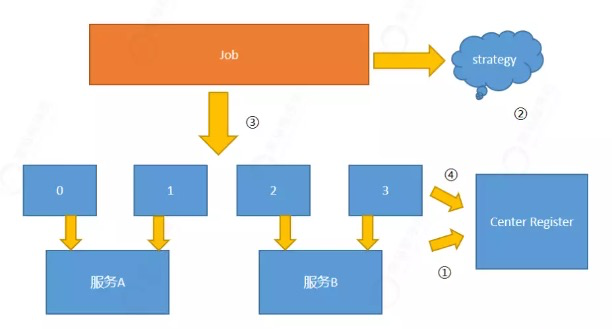
步骤1:服务首先要将自己的信息暴露给注册中心。;
步骤2:服务通过选举的方式,来选择一个主节点;
步骤3:主节点通过调用分片策略进行分片。eg:分为4片,0,1分片的服务A。2 ,3属于服务B。
步骤4:将分片信息存储到注册中心;
# 4.3 弹性扩容
Elastic-Job如何进行弹性扩容。
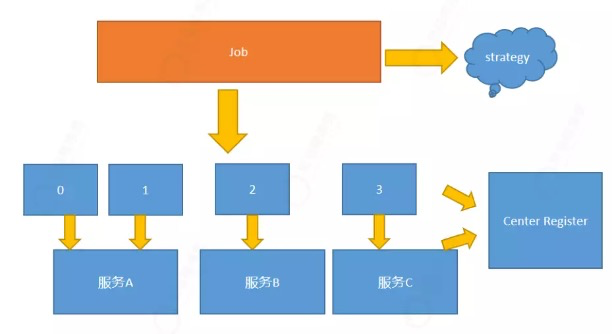
1.当有新的服务启动后,比如有一个新的服务服务C启动,首先需要将信息暴露到注册中心。暴露到注册中心后会在Zookeeper产生新的节点。
2.zookeepr中的节点监听器会监听到新服务的注册即服务发现。
- 一旦有新的服务注册,服务会进行重新选举,选出新的主节点。
- 由主节点调用分片策略,重新分片
- 将重新分片的信息存储到注册中心。
注意:分片调整的时机,并不是立即来做,而是先在Zookeeper中异步记录状态,然后在下一次任务执行之前,由主节点调用分片策略重新分片。
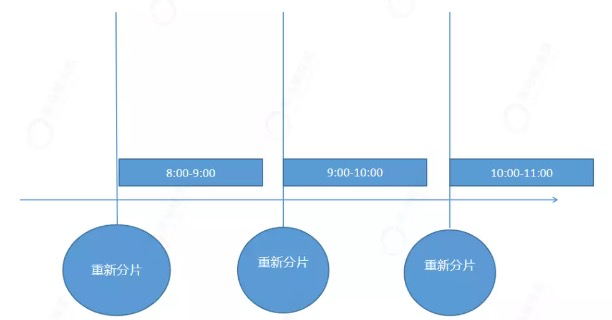
每隔1小时执行一次任务,如果在执行过程中有新的服务加入,或者服务宕机。并不是在作业执行过程中进行重新分片,重新分片的时机在下一次任务执行之前。
# 4.4 高可用
弹性扩容讲解完毕后,理解高可用就非常的容易。
如果作业在运行过程中,我们将服务进行了下线,或者机器出现了故障。分片就会指向存活的节点。
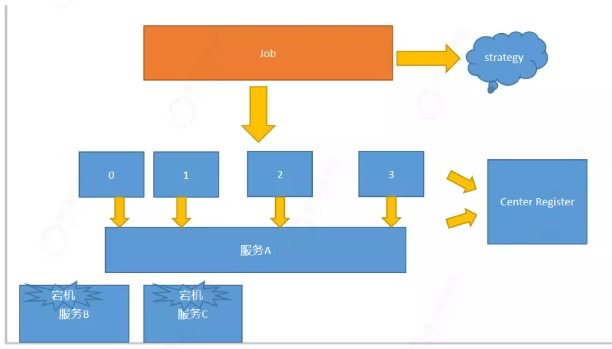
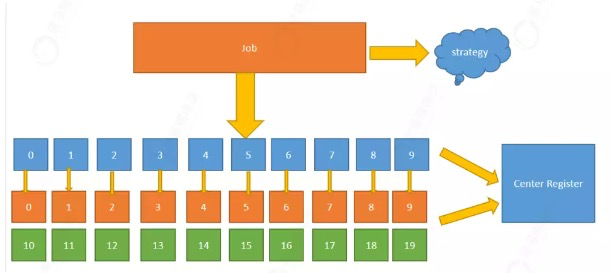
假如我们的作业非常重要,我们也可以这么做:eg:我们可以把作业任务分成10个分片。使用20的服务来运行。
这20个服务中,其中有10个运行,10个在等待,等到有服务宕机,就可以进行候补
# 4.5 失效转移
失效转移解决的问题:在作业运行过程中可能中,某些分片所在的服务产生宕机。导致一部分分片执行成功,一部分分片执行失败。
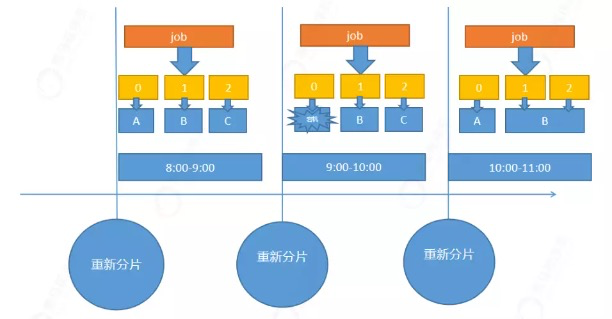
Elastic-Job的解决方案:开启失效转移
spring整合Elastic-Job
<job:simple id="mySimpleJob" registry-center-ref="zk" cron="0/10 * * * * ?"
sharding-total-count="3"
class="cn.itcast.job.MySimpleJob" overwrite="true" failover="true" >
</job:simple>
2
3
4
spring boot整合Elastic-Job
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder(name, cron, shardingTotalCount).failover(true).build();
一旦我们设置failover为true后,Elastic-Job中FailoverListenerManager(失效转移监听管理器)中的一个监听器(JobCrashedJobListener)就开启。
该监听器会监听Zookeeper中instances下节点的删除事件。如果其中某个被删除。说明对应服务宕机。就会触发失败转移的逻辑。 失败转移逻辑
首先:在leader下创建一个failover/items节点。并且在items节点下记录宕机服务原来分配的分片(即失败的分片)。
接下来:其他存活的服务,都会监听到Zookeeper中节点删除的时间。存活的服务就会争抢
failover/items下面失败的分片。 为了保证失败的分片不会被重复执行。在Elastic-Job中采用了分布式锁解决。
最后:分片执行完毕后,会删除failover/items节点下失效的分片;
# 4.6 幂等性

假如:任务调度周期为每1小时执行一次,正常每次调度任务处理需要耗时30分钟,如果在某一段时间由于数据库压力变大,导致原本只需要30分钟就能处理完成的任务,现在需要1.10小时才能运行,在一批数据处理未完成的情况下,每1小时又会触发一次调度,这样同一条任务数据可能将被多次处理,如果业务方法未实现幂等,则会引发非常严重的问题,那ElasticJob如何避免这个问题呢。
elasticJob提供了一个配置参数:
monitorExecution=true,开启幂等性
在下一个调度周期到达之后,只要发现这个任务的任何一个分片正在执行(running),则为该任务的所有分片都设置为mis-fire,然后忽略本次任务触发。
在任务执行完成后,如果开启misfire
misfire=true
ElasticJob检查Zookeeper是否存在misfire状态分片,如果存在,则首先清除misfie相关的信息,然后补偿执行任务。
如果没有开启misfire,任务执行完成后,会等待下一个调度周期到达后触发。
# 4.7 总结
失效转移和幂等性比较适合于作业时间相对较长的任务,作业一次只处理一块数据,比如报表统计,金额汇总,数据一次都不能丢,否则数据可能不完整。
对于一些几个秒执行一次的作业任务。比如超时订单处理。失效转移和幂等性其实可以不使用。
