 Elastic-Job基础使用
Elastic-Job基础使用
# 1 什么使用分布式定时任务
将一个任务拆分成多个独立的分片项,由分布式系统的服务执行其中一个或者多个分片项。(简单来说就是可以将任务再次拆分);
分布式定时任务的优势。
eg:我们有一个任务需要处理10000万条数据,如果使用Quartz,处理10000万数据的任务将来会落在一个服务上。如果使用elastic-job,我们就可以将10000万条数据拆分成10个分片。将来每个服务处理一个分片数据,这样每个服务只需要处理10分之一的数据,大大降低服务的压力。
# 2 Elastic-Job的简介
Elastic-Job是当当网资深架构师张亮老师研发的分布式定时任务的框架。分为2个子项目Elastic-Job-lite,Elastic-Job-cloud;我们以Elastic-Job-lite为主。
**Elastic-Job-lite:**使用jar包的形式提供最轻量级的分布式任务的协调服务;
依赖zookeeper: 分布式协调和任务信息管理;
分片:分片是Elastic-job最核心的概念,学习Elastic-Job,分片的概念必须搞清楚。
任务要以分布式的方式运行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
例如:有一个遍历数据库某张表的任务,现有2台服务器。为了快速的执行任务,那么每台服务器应执行任务的50%。 为满足此需求,可将任务分成2片,每台服务器执行1片。任务遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。 如果分成10片,服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,处理数据服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据。
2
3
4
Elastic-Job不提供数据的处理能力。数据的处理逻辑他是不提供的。
Elastic-Job提供将分片项分配到各服务中;至于这些分片项处理那些业务逻辑ELastic-Job是不负责的,是由开发人员决定。
开发人员自己决定分片项的数据处理逻辑。
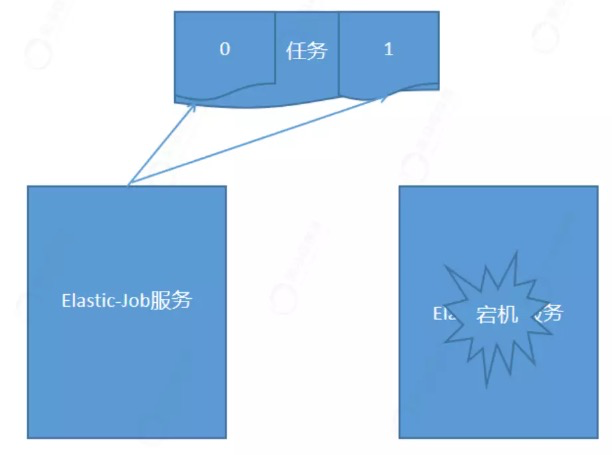
作业高可用和弹性扩容
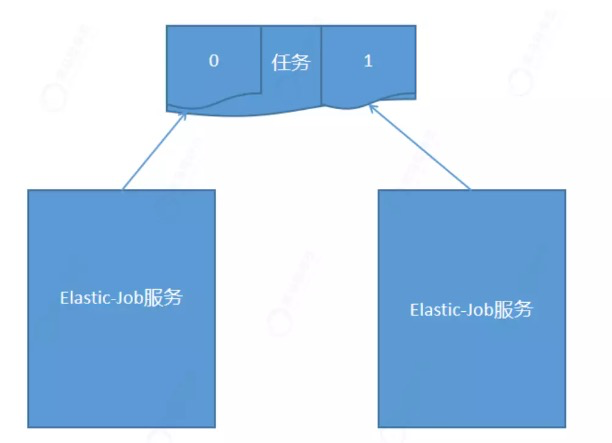
eg:将一个任务分成2个分片,0分片分配在第一个服务上,1分片分配在第二个服务上。假如第二个服务宕机。1分片重新分配到其他服务上。
# 3 Elastic-Job的作业任务类型
Simple作业:用于定义简单的定时任务,需要实现SimpleJob接口重写execute方法。
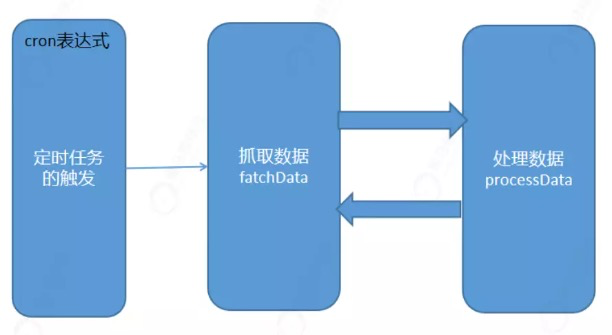
DataFlow作业:流式作业,相比Simple作业的特点是,Simple作业是将所有的任务逻辑都写在execute
方法中。而DataFlow作业处理数据的时候分为2步。数据的抓取(fetchData),数据处理
(processData).
流程:
定时任务的触发。
数据抓取。
数据处理。
处理完毕后再次进行抓取,如果数据存在继续处理,如果数据不存在本次任务执行完毕。等待下次触发。
Script作业:脚本类型的作业。有时候我们写了一些脚本(shell,python脚本),需要定期执行,就可以使用这种作业类型。在Linux环境中使用crontab也可以,但是crontab是不支持分片的、如果脚本执行的任务量比较大,希望进行分片,就可以使用这种作业类型;
# 4 Spring整合Elastic-Job开发不同类型的作业
# 4.1 Zookeeper环境准备
docker pull zookeeper:3.4.14
docker run -id --name zookeeper -p 2181:2181 --privileged=true zookeeper:3.4.14
2
# 4.2 Spring整合Elastic-Job开发Simple类型作业
# (一)创建web项目,引入相关依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spring.verion>5.0.5.RELEASE</spring.verion>
<elastic.job.version>2.1.5</elastic.job.version>
</properties>
<dependencies>
<!--spring依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.verion}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>${spring.verion}</version>
</dependency>
<!--elastic-job依赖-->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${elastic.job.version}</version>
</dependency>
<!--elastic-job和spring整合依赖-->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>${elastic.job.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.16</version>
<scope>provided</scope>
</dependency>
<!--slf4j整合log4j的依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--tomcat插件-->
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<port>8080</port>
<path>/</path>
<uriEncoding>UTF-8</uriEncoding>
</configuration>
</plugin>
</plugins>
</build>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
## 配置根Logger
log4j.rootLogger=info, ServerDailyRollingFile, stdout
## 配置输出到控制台
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH\:mm\:ss} %p [%c] %m%n
2
3
4
5
6
# (二)创建Simple类型的作业
@Slf4j
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
//shardingContext分片上下文(获取作业任务分片总数,当前分片)
int item = shardingContext.getShardingItem();
int totalCount = shardingContext.getShardingTotalCount();
log.info("作业被执行了" + new Date() +"分片总数:" + totalCount + "当前分片:" + item);
}
}
2
3
4
5
6
7
8
9
10
# (三) 在spring的配置文件中配置作业的信息和Zookeeper的连接信息
引入ELastic-job的schema约束的名称空间。
reg:配置Zookepper
job:配置作业
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:reg="http://www.dangdang.com/schema/ddframe/reg"
xmlns:job="http://www.dangdang.com/schema/ddframe/job"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.dangdang.com/schema/ddframe/reg
http://www.dangdang.com/schema/ddframe/reg/reg.xsd
http://www.dangdang.com/schema/ddframe/job
http://www.dangdang.com/schema/ddframe/job/job.xsd">
</beans>
<!--配置zookeeper id唯一标识,地址列表,作业信息存储在zk的那个节点下-->
<reg:zookeeper id="zk" server-lists="192.168.200.128:2181" namespace="elastic-job"></reg:zookeeper>
<!--配置作业-->
<job:simple id="mySimpleJob" registry-center-ref="zk" cron="0/10 * * * * ?" sharding-total-count="3" class="cn.itcast.MySimpleJob" overwrite="true"></job:simple>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# (四)测试:当前作业被分成3片,分配在一个服务上
2020-06-27 13:43:40 INFO [cn.itcast.MySimpleJob] 作业被执行了...分片总数:3当前分片:
1
2020-06-27 13:43:40 INFO [cn.itcast.MySimpleJob] 作业被执行了...分片总数:3当前分片:
0
2020-06-27 13:43:40 INFO [cn.itcast.MySimpleJob] 作业被执行了...分片总数:3当前分片:
2
2
3
4
5
6
# (五)测试:启动2个服务,分片会分配在不同的服务上
-Dmaven.tomcat.port=8088 tomcat:run -f pom.xml
# 4.2 Spring整合Elastic-Job开发Dataflow类型作业
需求:某个任务需要处理10000个数据,需要将任务分为2个分片来处理,第一个分片处理偶数,第二个分片处理奇数。每个分片每次抓取100个数据进行处理,直到处理完毕;
# (一)定义DataflowJob类型的作业
@Slf4j
public class MyDataflowJob implements DataflowJob<Integer> {
private static List<Integer> dataEvent; //偶数
private static List<Integer> dataOld; //奇数
static {
dataEvent = new ArrayList<>();
dataOld = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
if (i % 2 == 0) {
dataEvent.add(i);
} else {
dataOld.add(i);
}
}
}
@SneakyThrows
@Override
public List<Integer> fetchData(ShardingContext shardingContext) {
//0号分片
List<Integer> integers = null;
if (shardingContext.getShardingItem() == 0) {
if(dataEvent.size() >= 100) {
integers = dataEvent.subList(0, 100); //从偶数集合中获取100个数据
}else {
integers = dataEvent.subList(0, dataEvent.size());
}
}else {
if(dataOld.size() >= 100) {
integers = dataOld.subList(0, 100); //从偶数集合中获取100个数据
}else {
integers = dataOld.subList(0, dataOld.size());
}
}
return integers;
}
@SneakyThrows
@Override
public void processData(ShardingContext shardingContext, List<Integer> list)
{
log.info(shardingContext.getShardingItem() + "号分片处理数据" + list);
if (shardingContext.getShardingItem() == 0) {
dataEvent.removeAll(list);
} else if (shardingContext.getShardingItem() == 1) {
dataOld.removeAll(list);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# (二)在spring的配置文件中配置作业信息
<job:dataflow id="myDataflow" class="cn.itcast.MyDataflowJob" registry-center-ref="zk" cron="0/10 * * * * ?" sharding-total-count="2" streaming-process="true"/>
# 4.2 Spring整合Elastic-Job开发Script类型作业
Script类型作业意为脚本类型作业,支持shell,python,perl等所有类型脚本。
# (一)编写脚本
%*:获取分片参数
echo hello %*
# (二)在spring的配置文件中配置作业信息
<job:script id="myScriptJob" registry-center-ref="zk" cron="0/5 * * * * ?" sharding-total-count="2" script-command-line="d:/hello.bat">
</job:script>
2
# 5 Spring Boot整合Elastic-Job开发不同类型的作业
# 5.1 spring boot整合Elastic-Job开发Simple类型的作业
# (一)创建spring boot的服务,引入相关的依赖
<!--继承spring-boot-starter-parent-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
</parent>
<properties>
<elastic.job.version>2.1.5</elastic.job.version>
</properties>
<dependencies>
<!--web的起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--elastic-job的依赖-->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${elastic.job.version}</version>
</dependency>
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>${elastic.job.version}</version>
</dependency>
<!--lombok的依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# (二) 将Zookeeper注册中心的Bean交由spring管理
在spring的配置文件中,我们是通过xml文件配置。在springboot的项目中需要通过配置类配置;并且将相关信息配置到yml文件中,约定的配置
elasticjob:
zoookepper:
serverLists: 192.168.200.128
namespace: elactic_job_test
2
3
4
2.1 声明Zookeeper的属性配置类,定义Zookeeper相关属性.声明好属性配置类后,就可以在
application.yml中设置属性,使用属性配置类进行封装;
@ConfigurationProperties(prefix = "elasticjob.zoookepper")
@Data
public class ZookeeperProperties {
private String serverLists;
private String namespace;
}
2
3
4
5
6
2.2 在配置类中声明Zookeeper的Bean
https://shardingsphere.apache.org/elasticjob/legacy/lite-2.x/01-start/quick-start/
@Configuration
@EnableConfigurationProperties(ZookeeperProperties.class)
@ConditionalOnProperty(prefix = "elasticjob.zoookepper",name="serverLists")
public class ElasticJobZookeeperConfig {
@Autowired
private ZookeeperProperties zookeeperProperties;
/**
* 将注册中心的Bean交由spring管理
*/
@Bean
public CoordinatorRegistryCenter createRegistryCenter() {
String serverLists = zookeeperProperties.getServerLists();
String namespace = zookeeperProperties.getNamespace();
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverLists, namespace));
regCenter.init();
return regCenter;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2.3 配置类不生效的原因(配置类没有在启动类下)
配置类不应该放在启动类下,原因是将来这个代码将来打成jar后,可能还需要让别人使用。别人在使用的时候这个配置类就有可能没有在启动类下;
https://docs.spring.io/spring-boot/docs/2.0.3.RELEASE/reference/htmlsingle/#boot-features-locating-auto-configuration-candidates
创建META-INF/spring.factories
配置配置类
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
cn.itcast.config.ElasticJobZookeeperConfig
2
3
4
# (三) 开发SimpleJob作业任务类
@Slf4j
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
log.info("任务执行了,分片项:" + shardingContext.getShardingItem() + "总分片:" + shardingContext.getShardingTotalCount());
}
}
2
3
4
5
6
7
# (四)作业配置
和spring整合的时候,在xml文件中配置;
<job:simple id="mySimpleJob" registry-center-ref="zk" cron="0/10 * * * * ?" sharding-total-count="3" class="cn.itcast.MySimpleJob" overwrite="true"></job:simple>
和spring boot整合的时候,需要使用javaAPI;
https://shardingsphere.apache.org/elasticjob/legacy/lite-2.x/01-start/dev-guide/
// 定义作业核心配置
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder("demoSimpleJob", "0/15 * * * * ?", 10).build();
// 定义SIMPLE类型配置
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, SimpleDemoJob.class.getCanonicalName());
// 定义Lite作业根配置
JobRootConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).build();
2
3
4
5
6
自定义注解方式完成
写完作业类以后,加一个注解@Component @ElasticSimpleJob 就可以完成以上操作;
@Target(ElementType.TYPE) //注解定义位置
@Retention(RetentionPolicy.RUNTIME) //源码 编译 运行都有效
public @interface ElasticSimpleJob {
String name(); //作业名称
String cron(); //cron表达式
int shardingTotalCount(); //分片数量
boolean overwrite(); //是否覆盖注册中心中的作业信息
}
2
3
4
5
6
7
8
使用注解
@Component
@ElasticSimpleJob(name = "simpleJob", cron = "0/10 * * * * ?", shardingTotalCount = 2, overwrite = true)
2
定义配置类,解析注解使用JavaAPI完成配置和启动
获取spring容器中,标记有@ElasticSimpleJob注解的Bean
判断Bean是否实现了SimpleJob接口
获取Bean上面@ElasticSimpleJob注解
读取注解中的属性信息
使用Java的API启动任务
@Configuration
@ConditionalOnClass(CoordinatorRegistryCenter.class)
public class ElasticSimpleJobConfiguration {
@Autowired
private ApplicationContext applicationContext;
@Autowired
private CoordinatorRegistryCenter coordinatorRegistryCenter;
@PostConstruct
public void initJob() {
//1.获取spring容器中加了ElasticSimpleJob注解的类
Map<String, Object> beans = applicationContext.getBeansWithAnnotation(ElasticSimpleJob.class);
for (String id : beans.keySet()) {
Object o = beans.get(id);
//判断bean是否是SimpleJob的实例
if (o instanceof SimpleJob) {
SimpleJob bean = (SimpleJob)o;
//解析注解值
ElasticSimpleJob annotation = bean.getClass().getAnnotation(ElasticSimpleJob.class);
String cron = annotation.cron();
int shardingTotalCount = annotation.shardingTotalCount();
boolean overwrite = annotation.overwrite();
String name = annotation.name();
// 定义作业核心配置
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder(name, cron, shardingTotalCount).build();
// 定义SIMPLE类型配置
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, bean.getClass().getCanonicalName());
// 定义Lite作业根配置
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(overwrite).build();
new SpringJobScheduler(bean,coordinatorRegistryCenter, simpleJobRootConfig).init();
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
(五)思考:除了可以整合简单类型作业外,也可以整合DataFlow和Script类型作业。如何完成就交给大家作一个思考题;
@Target(ElementType.TYPE) //注解定义位置
@Retention(RetentionPolicy.RUNTIME) //源码 编译 运行都有效
public @interface ElasticDataFlowJob {
String name();
String cron();
int shardingTotalCount() default 1;
boolean streamingProcess() default false;
boolean overwrite() default false;
}
2
3
4
5
6
7
8
9
@Configuration
@ConditionalOnClass(CoordinatorRegistryCenter.class)
public class ElasticDataFlowJobConfiguration {
@Autowired
private ApplicationContext applicationContext;
@Autowired
private CoordinatorRegistryCenter coordinatorRegistryCenter;
@PostConstruct
public void initJob() {
//1.获取spring容器中加了ElasticDataFlowJob注解的对象
Map<String, Object> beans = applicationContext.getBeansWithAnnotation(ElasticDataFlowJob.class);
//2.迭代
for (String id : beans.keySet()) {
Object o = beans.get(id);
if(o instanceof DataflowJob) {
DataflowJob bean = (DataflowJob) o;
ElasticDataFlowJob annotation = bean.getClass().getAnnotation(ElasticDataFlowJob.class);
String name = annotation.name();
String cron = annotation.cron();
boolean overwrite = annotation.overwrite();
int shardingTotalCount = annotation.shardingTotalCount();
boolean streamingProcess = annotation.streamingProcess();
// 定义作业核心配置
JobCoreConfiguration dataflowCoreConfig = JobCoreConfiguration.newBuilder(name, cron, shardingTotalCount).build();
// 定义DATAFLOW类型配置
DataflowJobConfiguration dataflowJobConfig = new DataflowJobConfiguration(dataflowCoreConfig, bean.getClass().getCanonicalName(),streamingProcess);
// 定义Lite作业根配置
LiteJobConfiguration dataflowJobRootConfig = LiteJobConfiguration.newBuilder(dataflowJobConfig).overwrite(true).build();
new SpringJobScheduler(bean,coordinatorRegistryCenter,
dataflowJobRootConfig).init();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
cn.itcast.config.ElasticJobZookeeperConfig,\
cn.itcast.config.ElasticSimpleJobConfiguration,\
cn.itcast.config.ElasticDataFlowJobConfiguration
2
3
4
# 6 Elastic-Job在电商项目中的使用
# 场景1
# 6.1 业务场景和分析
需求:用户下单成功后,如果10分钟内未支付,需要自动将订单进行取消。
业务意义:用户电商网站下单后会减少商品库存。如果用户迟迟不肯支付,会占用库存资源。所以在指定的时间内没有支付,我们就可以进行订单取消,库存的回退。
实现的方案:
方案1:消息中间件-死信队列
死信队列也成为延迟消息队列,生产者发送消息到死信队列,消费者不能立即来消费,需要等待一定时间才能获取消息进行消息处理;
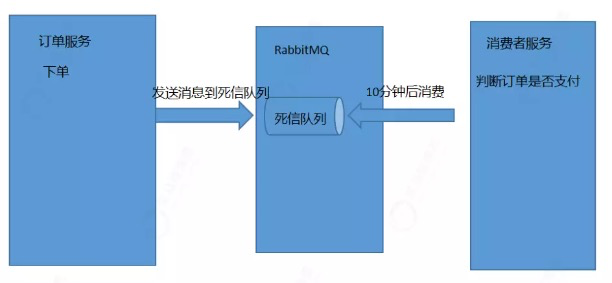
流程:
订单服务下单完成后,向死信队列发送一个消息。
消息需要等待10分钟后才能消费。
消费者服务中我们就可以获取下单超过10分钟的订单。
方案2:使用定时任务,每隔10s查询订单表,获取下单超过10分钟,且未支付的订单,然后进行订单取消。
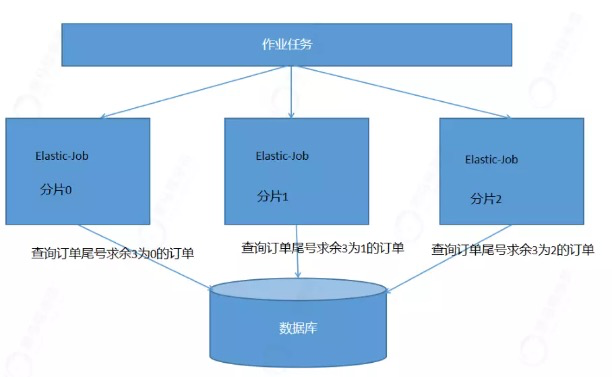
流程:
作业任务,我们分为3个分片。分别是分片项0,分片项1,分片项2。
每个分片项只处理一部分的超时未支付订单,这样可以大大降低服务的压力,也可以提高处理的速度,并且分片项也可以进行动态扩容。
# 6.2 环境准备
技术选项:Spring Boot + Elastic-Job + tk_mybatis
(一)准备订单表
CREATE TABLE `tb_order` (
`id` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '订单id',
`total_num` int(11) DEFAULT NULL COMMENT '数量合计',
`total_money` decimal(10,2) DEFAULT NULL COMMENT '金额合计',
`pre_money` decimal(10,2) DEFAULT NULL COMMENT '优惠金额',
`post_fee` decimal(10,2) DEFAULT NULL COMMENT '邮费',
`pay_money` decimal(10,2) DEFAULT NULL COMMENT '实付金额',
`pay_type` varchar(1) COLLATE utf8_bin DEFAULT NULL COMMENT '支付类型,1、在线支付、0 货到付款',
`create_time` datetime DEFAULT NULL COMMENT '订单创建时间',
`update_time` datetime DEFAULT NULL COMMENT '订单更新时间',
`pay_time` datetime DEFAULT NULL COMMENT '付款时间',
`consign_time` datetime DEFAULT NULL COMMENT '发货时间',
`end_time` datetime DEFAULT NULL COMMENT '交易完成时间',
`close_time` datetime DEFAULT NULL COMMENT '交易关闭时间',
`shipping_name` varchar(20) COLLATE utf8_bin DEFAULT NULL COMMENT '物流名称',
`shipping_code` varchar(20) COLLATE utf8_bin DEFAULT NULL COMMENT '物流单号',
`username` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '用户名称',
`buyer_message` varchar(1000) COLLATE utf8_bin DEFAULT NULL COMMENT '买家留言',
`buyer_rate` char(1) COLLATE utf8_bin DEFAULT NULL COMMENT '是否评价',
`receiver_contact` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '收货人',
`receiver_mobile` varchar(12) COLLATE utf8_bin DEFAULT NULL COMMENT '收货人手机',
`receiver_address` varchar(200) COLLATE utf8_bin DEFAULT NULL COMMENT '收货人地址',
`source_type` char(1) COLLATE utf8_bin DEFAULT NULL COMMENT '订单来源:1:web,2:app,3:微信公众号,4:微信小程序 5 H5手机页面',
`transaction_id` varchar(40) COLLATE utf8_bin DEFAULT NULL COMMENT '交易流水号',
`order_status` char(1) COLLATE utf8_bin DEFAULT NULL COMMENT '订单状态 0:未支付,1:已支付,2:已发货,3已收货,4已关闭',
`pay_status` char(1) COLLATE utf8_bin DEFAULT NULL COMMENT '支付状态 0:未支付 1:已支付',
`consign_status` char(1) COLLATE utf8_bin DEFAULT NULL COMMENT '发货状态 0:未发货 1:已发货 2:已送达',
`is_delete` char(1) COLLATE utf8_bin DEFAULT NULL COMMENT '是否删除',
PRIMARY KEY (`id`) USING BTREE,
KEY `create_time` (`create_time`) USING BTREE,
KEY `status` (`order_status`) USING BTREE,
KEY `payment_type` (`pay_type`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin ROW_FORMAT=DYNAMIC;
我们需要关注订单表的5个字段
1.id主键,通过雪花生成算法生成。
2.create_time订单的创建时间,通过这个时间可以确定订单是否超过10分钟;
3.update_time订单的更新时间,每次订单状态发生改变,需要修改时间
4.order_status订单状态
5.pay_status 支付状态
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
(二)删除springboot_elasticjob_starter中启动类和yml将其制作成模块,将来被别的服务使用。
(三)创建案例服务添加依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
</parent>
<dependencies>
<!--web的起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--elastic-job的起步依赖-->
<dependency>
<groupId>cn.itcast</groupId>
<artifactId>springboot_elasticjob_starter</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<!--通用mapper起步依赖-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>2.0.4</version>
</dependency>
<!--MySQL数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
(四) yml文件中指定MyBatis的连接信息
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/changgou_order?
useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: 123
elasticjob:
zoookepper:
serverLists: 192.168.200.128
namespace: elactic_job_example
2
3
4
5
6
7
8
9
10
11
12
(五) 编写实体类并且建立和表的映射关系
@Table(name="tb_order")
@Data
public class Order implements Serializable {
@Id
private Long id;//订单id
private Integer totalNum;//数量合计
private BigDecimal totalMoney;//金额合计
private BigDecimal preMoney;//优惠金额
private BigDecimal postFee;//邮费
private BigDecimal payMoney;//实付金额
private String payType;//支付类型,1、在线支付、0 货到付款
private java.util.Date createTime;//订单创建时间
private java.util.Date updateTime;//订单更新时间
private java.util.Date payTime;//付款时间
private java.util.Date consignTime;//发货时间
private java.util.Date endTime;//交易完成时间
private java.util.Date closeTime;//交易关闭时间
private String shippingName;//物流名称
private String shippingCode;//物流单号
private String username;//用户名称
private String buyerMessage;//买家留言
private String buyerRate;//是否评价
private String receiverContact;//收货人
private String receiverMobile;//收货人手机
private String receiverAddress;//收货人地址
private String sourceType;//订单来源:1:web,2:app,3:微信公众号,4:微信小程序 5 H5手机页面
private String transactionId;//交易流水号
private String orderStatus;//订单状态
private String payStatus;//支付状态
private String consignStatus;//发货状态
private String isDelete;//是否删除
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
(六)编写Mapper
public interface OrderMapper extends Mapper<Order> {
}
2
(七)启动类@MapperScan("指定dao接口所在包")
@MapperScan("cn.itcast.elasticjob.mapper")
# 6.3 定时任务逻辑编写
思路:
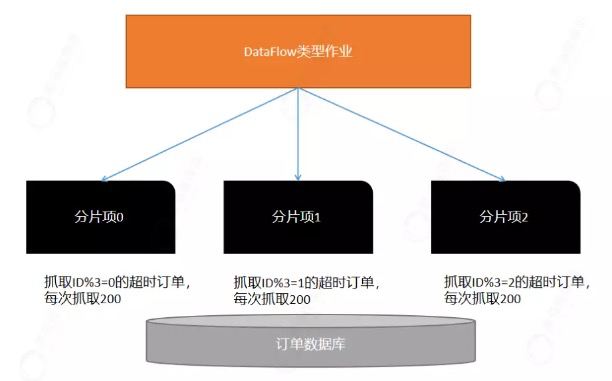
(一)编写Service,获取超时未支付订单,及更新订单状态
引入PageHelper的分页插件的starter
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>
2
3
4
5
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
public static final int ORDER_TIME_OUT = 10;
public static final int PAGE = 1;
public static final int SIZE = 100;
@Override
public List<Order> fetchTimeoutOrder(int item, int totalSharingCount) {
Example example = new Example(Order.class);
Example.Criteria criteria = example.createCriteria(); //封装条件
//订单状态0,支付状态0 ,下单时间超过10分钟 ID % totalSharingCount = item;
criteria.andEqualTo("orderStatus","0");
criteria.andEqualTo("payStatus","0");
//下单时间 < 当前时间 - 10
Date date = DateUtils.addMinutes(new Date(), -ORDER_TIME_OUT);
criteria.andLessThan("createTime",date);
criteria.andCondition("id % " + totalSharingCount+ "=" + item);
example.orderBy("createTime").asc();
PageHelper.startPage(PAGE,SIZE);
List<Order> orders = orderMapper.selectByExample(example);//根据条件查询订单数据
return orders;
}
@Override
public void timeoutOrder(Order order) {
Long id = order.getId();
String orderStatus = order.getOrderStatus();
order.setOrderStatus("4");//订单取消
order.setUpdateTime(new Date()); //设置订单更新时间
Example example = new Example(Order.class);
Example.Criteria criteria = example.createCriteria();
criteria.andEqualTo("id",id);
criteria.andEqualTo("orderStatus",orderStatus);
orderMapper.updateByExample(order,example);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
(二)编写作业完成调度
@Component
@ElasticDataFlowJob(name = "orderTimeoutJob",cron = "0/10 * * * * ?",
overwrite = true,shardingTotalCount = 3,streamingProcess = true)
public class OrderTimeoutJob implements DataflowJob<Order> {
@Autowired
private OrderService orderService;
//基于分片项,每次抓取100个超时订单。
//0号-------->ID % 3 = 0
//1号-------->ID % 3 = 1
//2 号------->Id % 3 = 2
@Override
public List<Order> fetchData(ShardingContext shardingContext) {
int item = shardingContext.getShardingItem();
int totalCount = shardingContext.getShardingTotalCount();
List<Order> orders = orderService.fetchTimeoutOrder(item, totalCount);
return orders;
}
@Override
public void processData(ShardingContext shardingContext, List<Order> list) {
//System.out.println(shardingContext.getShardingItem() + "抓取的数据" +list );
for (Order order : list) {
orderService.timeoutOrder(order);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 场景2
# 6.4 业务场景和分析
需求:每天凌晨需要对前一天不同时间段的商品销售数量和支付金额进行统计。
业务意义:对于电商网站的运营人员来说,他们是比较关注每天系统不同时间段交易额、成交量,便于进行数据分析,在电商网站中,会按照很多维度进行统计。我们本次维度是时间,每1小时销售的商品数量和总金额。
流程:
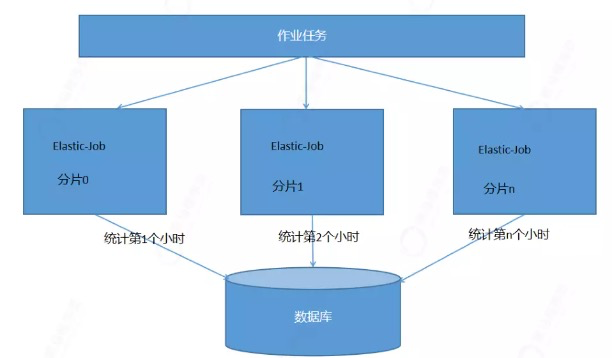
流程:
定义作业任务,我们分为24个分片。分布式分片项0,分片项1,分片项n。
每个分片项只统计一个小时销售的商品数量和总金额
# 6.5 环境准备
(一)导入资料中订单数据;
(二)创建销售统计表
CREATE TABLE `tb_order_log` (
`id` varchar(100) NOT NULL,
`startDate` datetime DEFAULT NULL,
`endDate` datetime DEFAULT NULL,
`totalNum` int(11) DEFAULT NULL,
`totalMoney` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2
3
4
5
6
7
8
(三)编写销售统计表的Pojo
@Table(name="tb_order_log")
@Data
public class OrderLog {
@Id
@Column(name="id")
private Long id;
@Column(name="startDate")
private Date startDate;
@Column(name="endDate")
private Date endDate;
@Column(name="totalNum")
private Integer totalNum;
@Column(name="totalMoney")
private BigDecimal totalMoney;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
(四) 编写销售统计表的Mapper
public interface OrderLogMapper extends Mapper<OrderLog> {
}
2
# 6.6 定时任务逻辑编写
(一) 编写作业任务
@Component
@ElasticSimpleJob(name="orderSummarySimpleJob",cron = "0 0 0 * * ?",shardingTotalCount = 24,overwrite = true)
public class OrderSummarySimpleJob implements SimpleJob {
@Autowired
private OrderService orderService;
@Override
public void execute(ShardingContext shardingContext) {
//1.获取前一天的时间
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DAY_OF_MONTH,-1);
//2.将前一天的时间划分为24个时间段 00 01 02 ...23
List<Date> dateMenus = DateUtil.getDateMenus(calendar.getTime());
//3.不同的时间片统计不同时间段的订单
//0号分片 00 01
//1号分片 01 02
//23号分片 23 ..
int shardingItem = shardingContext.getShardingItem();
Date startDate = dateMenus.get(shardingItem);
Date endDate = DateUtil.addDateHour(startDate, 1);
orderService.countOrder();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
(二)编写持久层
@Select("SELECT SUM(total_num) totalnums ,SUM(pay_money) totalmoneys FROM tb_order WHERE create_time >= #{startDate} AND create_time < #{endDate}" + "AND order_status=1 AND pay_status=1")
Map<String, Double> countOrder(@Param("startDate") Date startDate,@Param("endDate") Date endDate);
2
(三) 编写业务层
/**
* 根据时间段统计该时间段,销售的商品数量,金额
*/
public void countOrder(Date startDate,Date endDate) {
//根据时间段进行统计
Map<String, Object> countOrder = orderMapper.countOrder(startDate,
endDate);
Integer totalnums = (Integer) countOrder.get("totalnums");
BigDecimal totalmoneys = (BigDecimal) countOrder.get("totalmoneys");
//保存统计结果
OrderLog orderLog = new OrderLog();
orderLog.setId(idWorker.nextId());
orderLog.setStartDate(startDate);
orderLog.setEndDate(endDate);
orderLog.setTotalNum(totalnums);
orderLog.setTotalMoney(totalmoneys);
orderLogMapper.insert(orderLog);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
