 分布式系统设计策略
分布式系统设计策略
分布式系统本质是通过低廉的硬件攒在一起以获得更好的吞吐量、性能以及可用性等。
在分布式环境下,有几个问题是普遍关心的,我们称之为设计策略:
如何检测当前节点还活着?
如何保障高可用?
容错处理
负载均衡
# 1 心跳检测
在分布式环境中,我们提及过存在非常多的节点(Node),其实质是这些节点分担任务的运行、计算或者程序逻辑处理。那么就有一个非常重要的问题,如何检测一个节点出现了故障乃至无法工作了?
通常解决这一问题是采用心跳检测的手段,如同通过仪器对病人进行一些检测诊断一样。
心跳顾名思义,就是以固定的频率向其他节点汇报当前节点状态的方式。收到心跳,一般可以认为一个节点和现在的网络拓扑是良好的。当然,心跳汇报时,一般也会携带一些附加的状态、元数据信息,以便管理
如图所示,Client请求Server,Server转发请求到具体的Node获取请求结果。Server需要与三个Node节点保持心跳连接,确保Node可以正常工作。
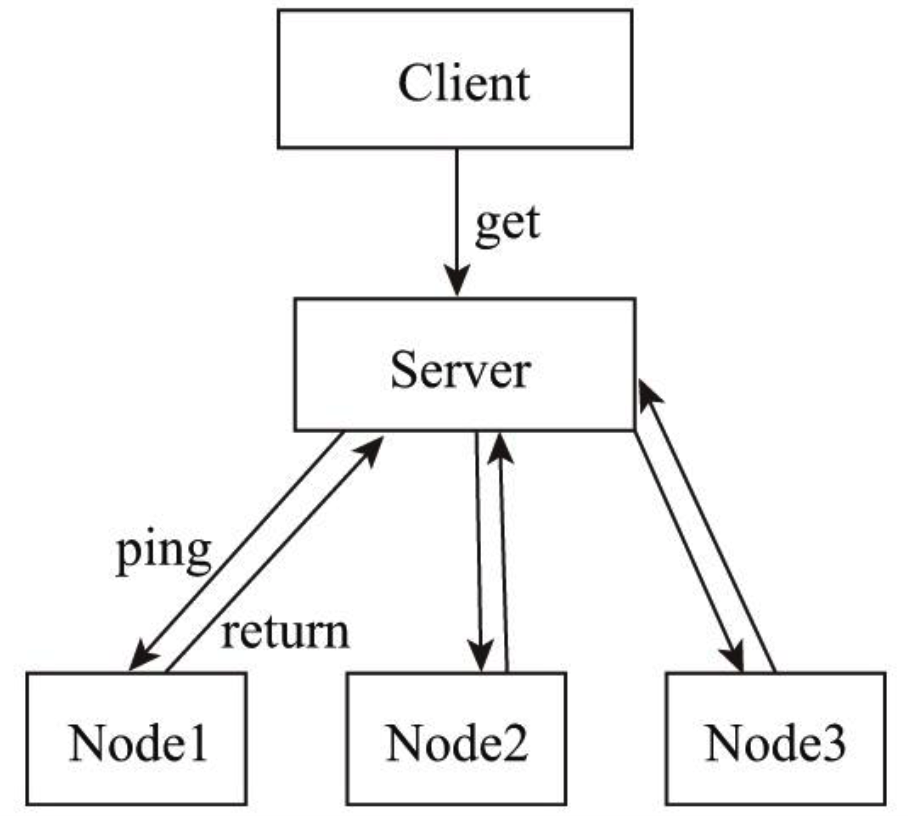
若Server没有收到Node3的心跳时,Server认为Node3失联。但是失联是失去联系,并不确定是否是Node3故障,有可能是Node3处于繁忙状态,导致调用检测超时;也有可能是Server与Node3之间链路出现故障或闪断。所以心跳不是万能的,收到心跳可以确认节点正常,但是收不到心跳也不能认为该节点就已经宣告“死亡”。此时,可以通过一些方法帮助Server做决定: 周期检测心跳机制、累计失效检测机制。
周期检测心跳机制
Server端每间隔 t 秒向Node集群发起监测请求,设定超时时间,如果超过超时时间,则判断“死亡”。
累计失效检测机制
在周期检测心跳机制的基础上,统计一定周期内节点的返回情况(包括超时及正确返回),以此计算节点的“死亡”概率。另外,对于宣告“濒临死亡”的节点可以发起有限次数的重试,以作进一步判断。
通过周期检测心跳机制、累计失效检测机制可以帮助判断节点是否“死亡”,如果判断“死亡”,可以把该节点踢出集群
# 2 高可用设计
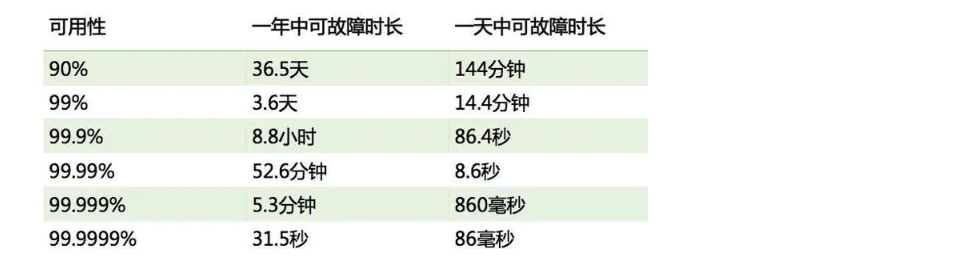
高可用(High Availability)是系统架构设计中必须考虑的因素之一,通常是指,经过设计来减少系统不能提供服务的时间
系统高可用性的常用设计模式包括三种:主备(Master-SLave)、互备(Active-Active)和集群(Cluster)模式。
1.主备模式 主备模式就是Active-Standby模式,当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动(热备)或手动(冷备)方式将服务切换到主机上运行。在数据库部分,习惯称之为MS模式。
MS模式即Master/Slave模式,这在数据库高可用性方案中比较常用,如MySQL、Redis等就采用MS模式实现主从复制。保证高可用,如图所示。
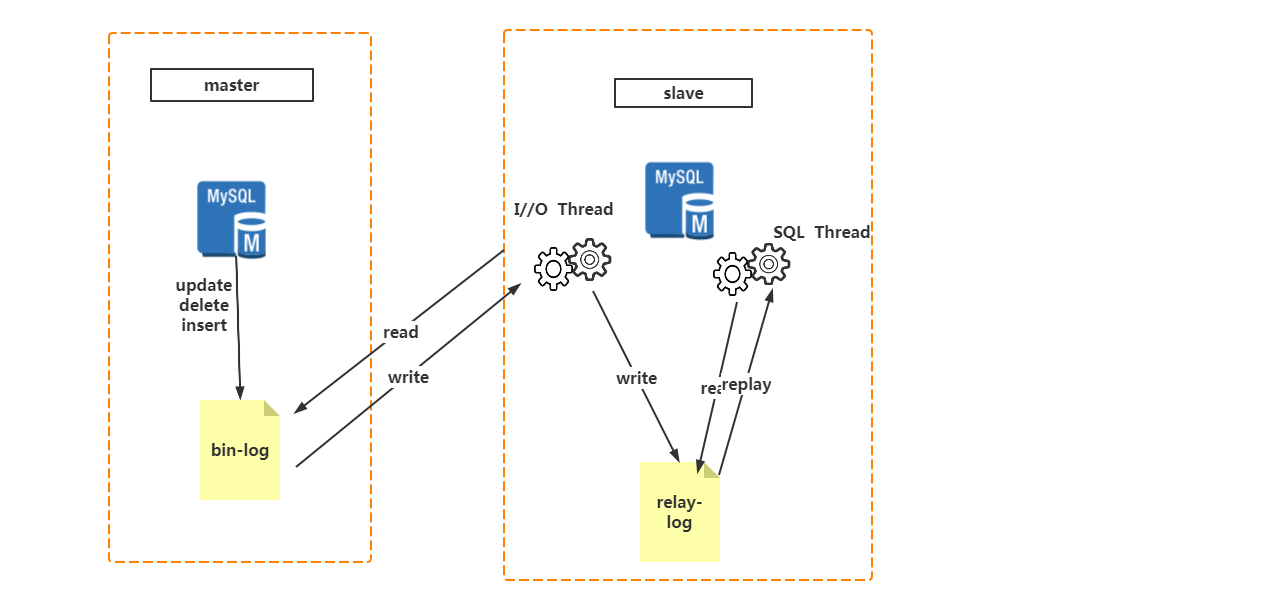
MySQL之间数据复制的基础是二进制日志文件(binary log file)。一台MySQL数据库一旦启用二进制日志后,作为master,它的数据库中所有操作都会以“事件”的方式记录在二进制日志中,其他数据库作为slave通过一个I/O线程与主服务器保持通信,并监控master的二进制日志文件的变化,如果发现master二进制日志文件发生变化,则会把变化复制到自己的中继日志中,然后slave的一个SQL线程会把相关的“事件”执行到自己的数据库中,以此实现从数据库和主数据库的一致性,也就实现了主从复制。
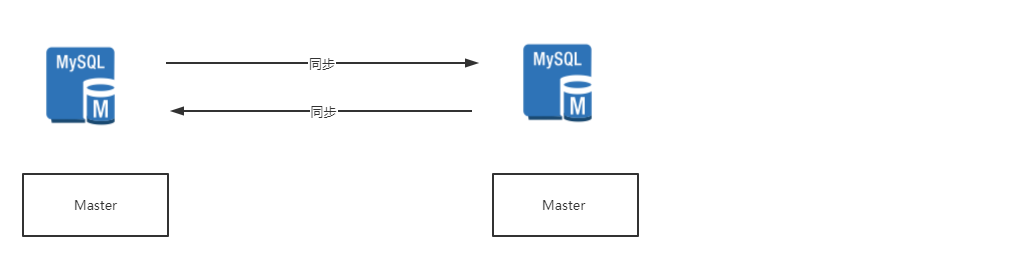
2.互备模式 互备模式指两台主机同时运行各自的服务工作且相互监测情况。在数据库高可用部分,常见的互备是MM模式。MM模式即Multi-Master模式,指一个系统存在多个master,每个master都具有read-write能力,会根据时间戳或业务逻辑合并版本。
我们使用过的、构建过的MySQL服务绝大多数都是Single-Master,整个拓扑中只有一个Master承担写请求。比如,基于Master-Slave架构的主从复制,但是也存在由于种种原因,我们可能需要MySQL服务具有Multi-Master的特性,希望整个拓扑中可以有不止一个Master承担写请求
3.集群模式
集群模式是指有多个节点在运行,同时可以通过主控节点分担服务请求。如Zookeeper。集群模式需要解决主控节点本身的高可用问题,一般采用主备模式。
# 3 容错性
容错顾名思义就是IT系统对于错误包容的能力
容错的处理是保障分布式环境下相应系统的高可用或者健壮性,一个典型的案例就是对于缓存穿透 问题的解决方案。
我们来具体看一下这个例子,如图所示
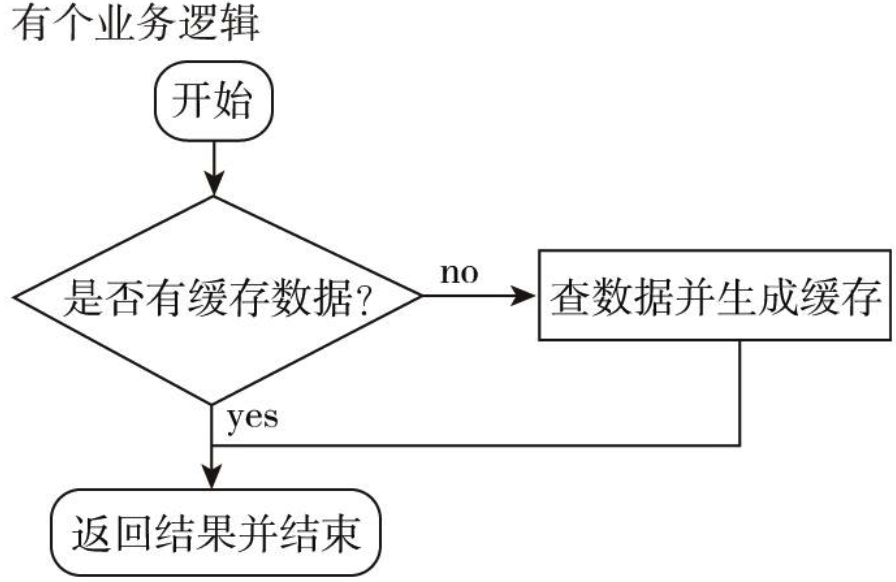
问题描述:
我们在项目中使用缓存通常都是先检查缓存中是否存在,如果存在直接返回缓存内容,如果不存在就直接查询数据库然后再缓存查询结果返回。这个时候如果我们查询的某一个数据在缓存中一直不存在,就会造成每一次请求都查询DB,这样缓存就失去了意义,在流量大时,或者有人恶意攻击
如频繁发起为id为“-1”的条件进行查询,可能DB就挂掉了。
那这种问题有什么好办法解决呢?
一个比较巧妙的方法是,可以将这个不存在的key预先设定一个值。比如,key=“null”。在返回这个null值的时候,我们的应用就可以认为这是不存在的key,那我们的应用就可以决定是否继续等待访问,还是放弃掉这次操作。如果继续等待访问,过一个时间轮询点后,再次请求这个key,如果取到的值不再是null,则可以认为这时候key有值了,从而避免了透传到数据库,把大量的类似请求挡在了缓存之中。
# 4 负载均衡
负载均衡:其关键在于使用多台集群服务器共同分担计算任务,把网络请求及计算分配到集群可用的不同服务器节点上,从而达到高可用性及较好的用户操作体验。
如图,不同的用户User1、User2、User3访问应用,通过负载均衡器分配到不同的节点。
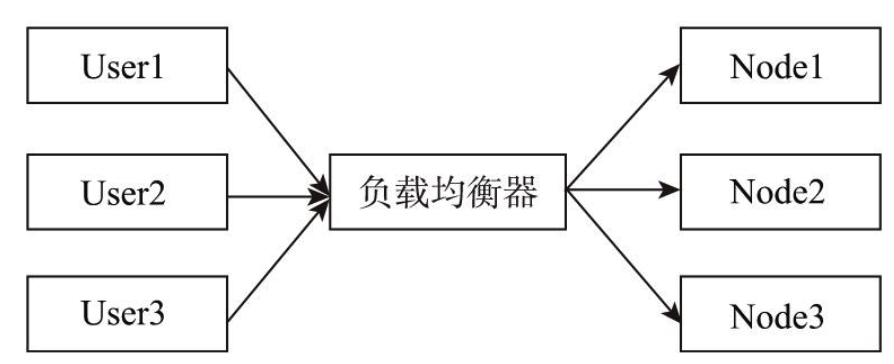
负载均衡器有硬件解决方案,也有软件解决方案。硬件解决方案有著名的F5,软件有LVS、HAProxy、Nginx等。
以Nginx为例,负载均衡有以下几种策略:
轮询:即Round Robin,根据Nginx配置文件中的顺序,依次把客户端的Web请求分发到不同的后端服务器。
最少连接:当前谁连接最少,分发给谁。
IP地址哈希:确定相同IP请求可以转发给同一个后端节点处理,以方便session保持。
基于权重的负载均衡:配置Nginx把请求更多地分发到高配置的后端服务器上,把相对较少的请求分发到低配服务器。
