 源码剖析-分区消费模式
源码剖析-分区消费模式
# 4.16 Kafka源码剖析之分区消费模式
在分区消费模式,需要手动指定消费者要消费的主题和主题的分区信息。
可以设置从分区的哪个偏移量开始消费。
典型的分区消费:
Map<String, Object> configs = new HashMap<>();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
configs.put(ConsumerConfig.CLIENT_ID_CONFIG, "mycsmr" +System.currentTimeMillis());
configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 设置消费组id
// configs.put(ConsumerConfig.GROUP_ID_CONFIG, "csmr_grp_01");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs);
TopicPartition tp0 = new TopicPartition("tp_demo_01", 0);
TopicPartition tp1 = new TopicPartition("tp_demo_01", 1);
TopicPartition tp2 = new TopicPartition("tp_demo_01", 2);
/*
* 如果不设置消费组ID,则系统不会自动给消费者分配主题分区
* 此时需要手动指定消费者消费哪些分区数据。
*/
consumer.assign(Arrays.asList(tp0, tp1, tp2));
consumer.seek(tp0, 0);
consumer.seek(tp1, 0);
consumer.seek(tp2, 0);
ConsumerRecords<String, String> records = consumer.poll(1000);
records.forEach(record -> {
System.out.println(record.topic() + "\t"
+ record.partition() + "\t"
+ record.offset() + "\t"
+ record.key() + "\t"
+ record.value());
}
);
// 最后关闭消费者
consumer.close();
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
上面代码中的assign方法的实现:
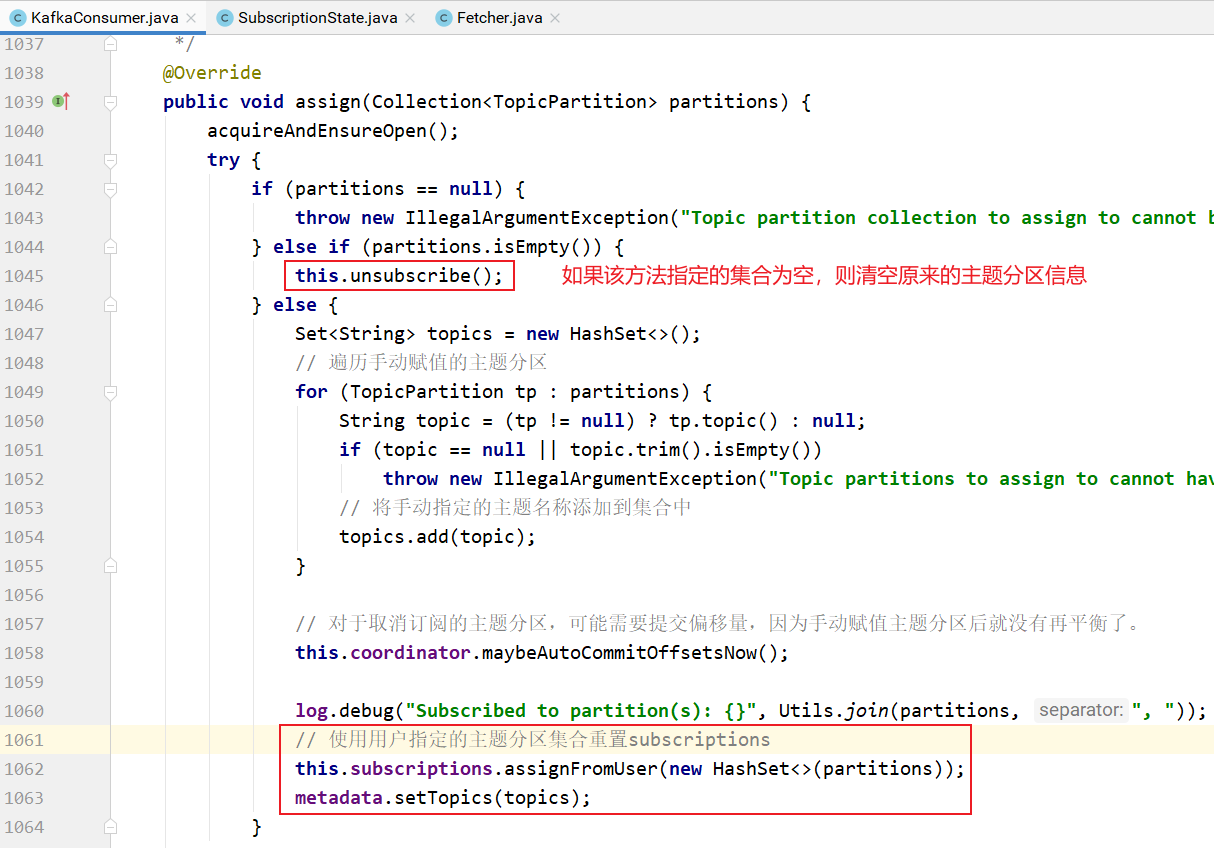
assignFromUser的实现:
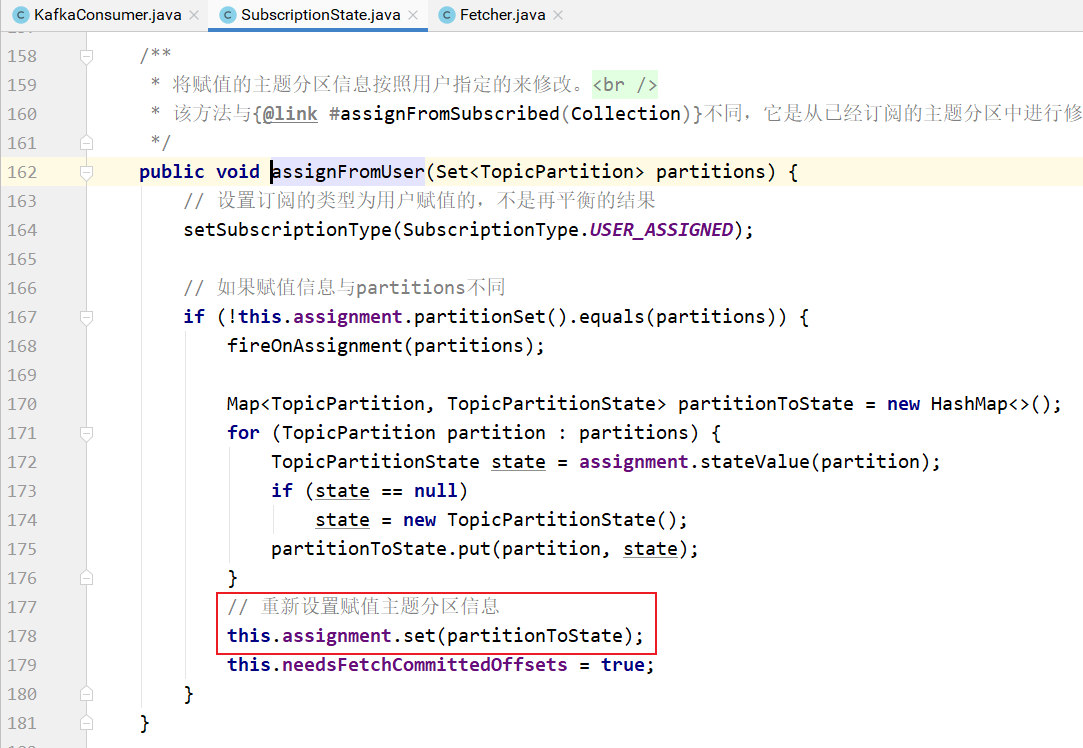
调用seek方法指定各个主题分区从哪个偏移量开始消费:
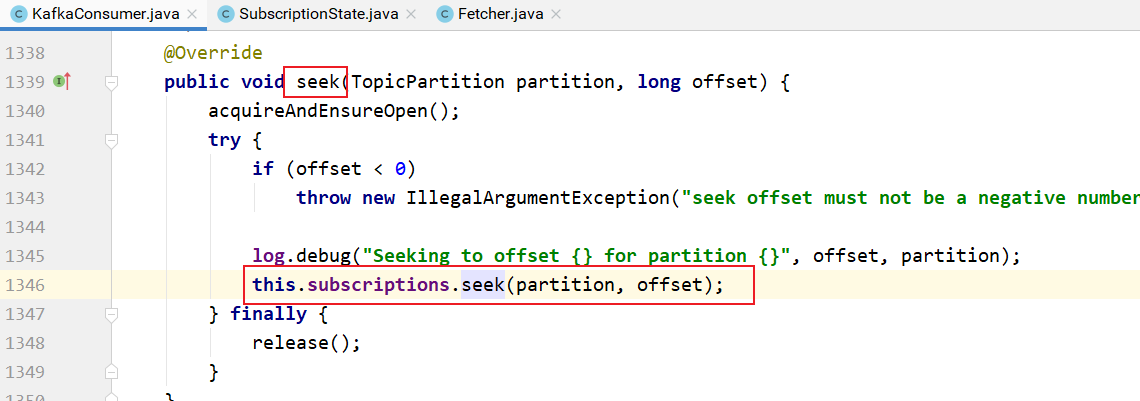
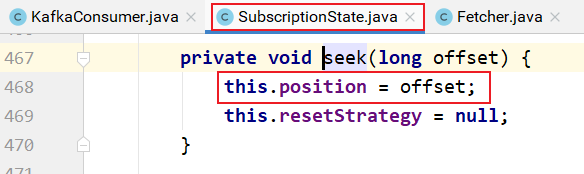
subscriptions的seek方法实现:
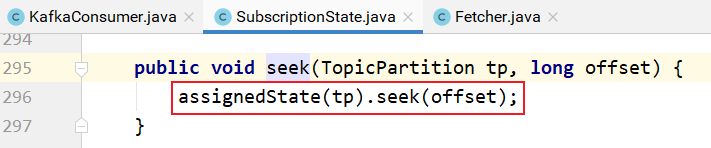
上图中seek的实现:
此时poll方法的调用为:


pollOnce方法的实现:
发起请求:

该方法的实现:
创建需要发送的请求对象并发起请求:
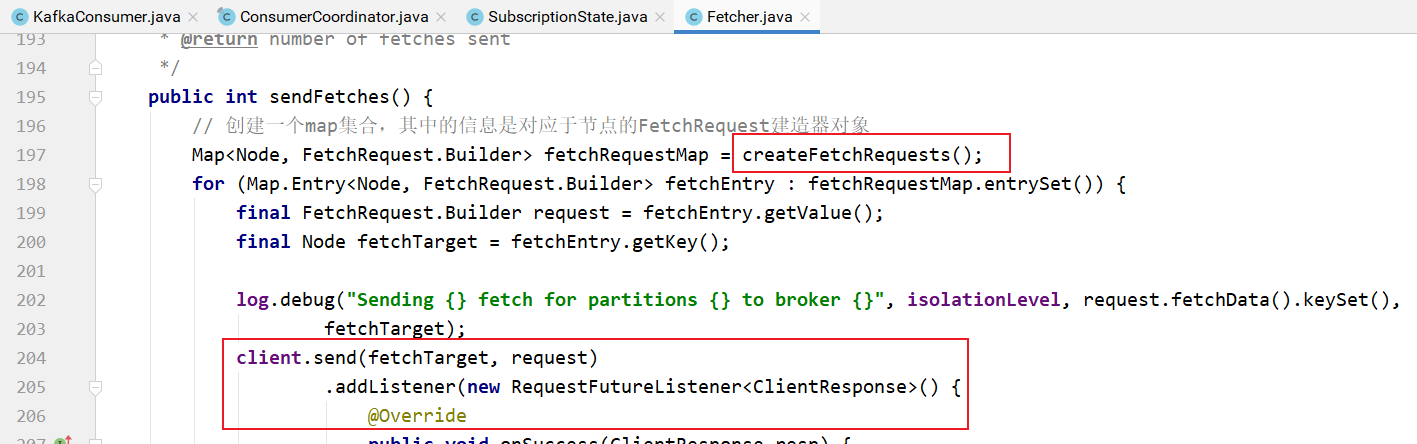
client.send方法添加监听器,等待broker端的响应:
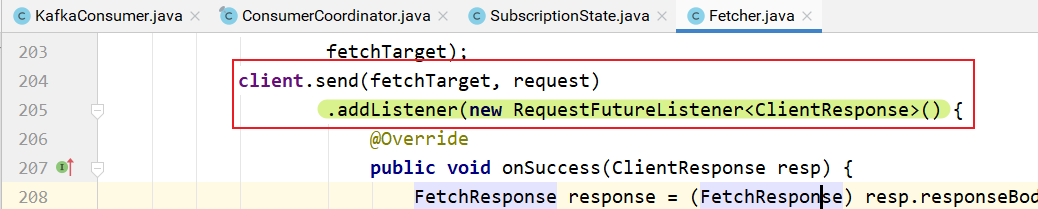
监听的逻辑:
上面方法中createFetchRequests用于创建需要发起的请求:
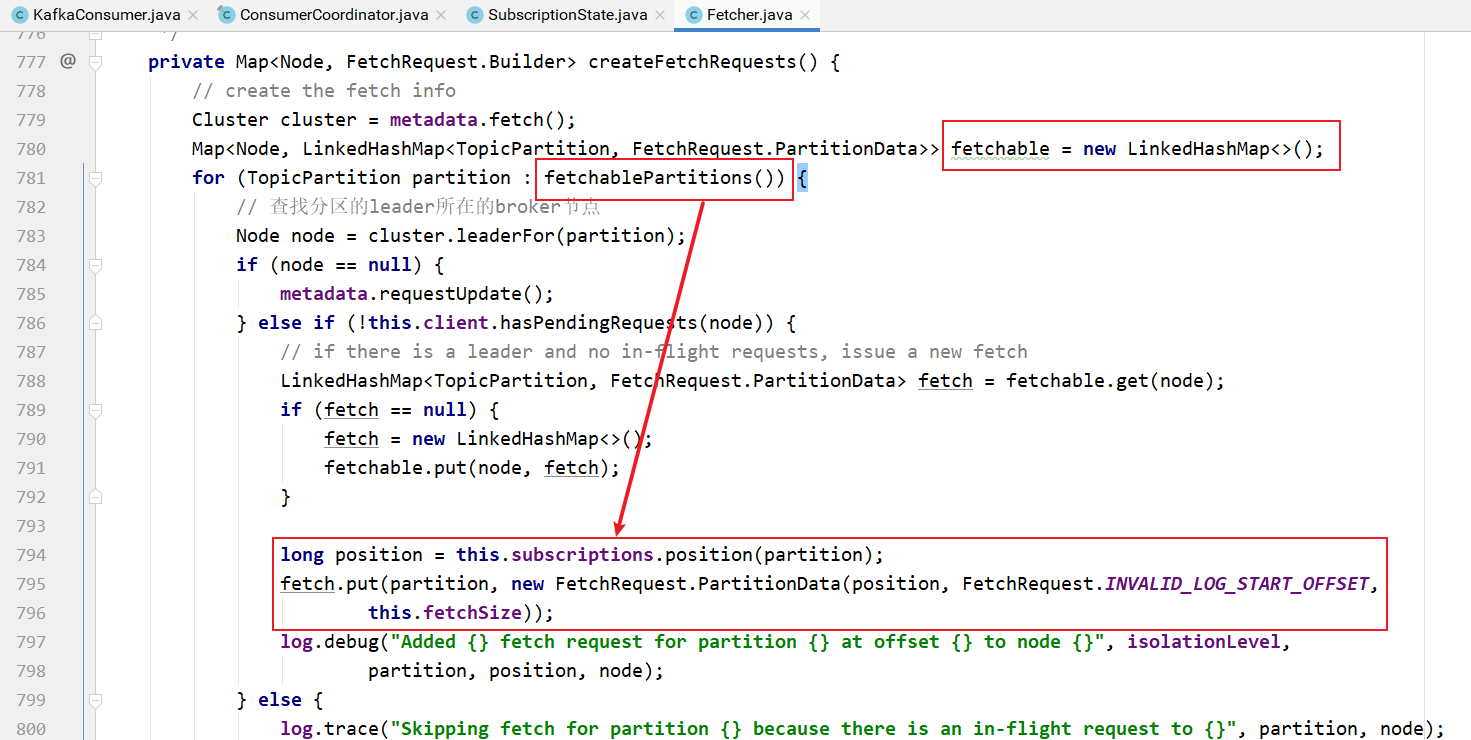
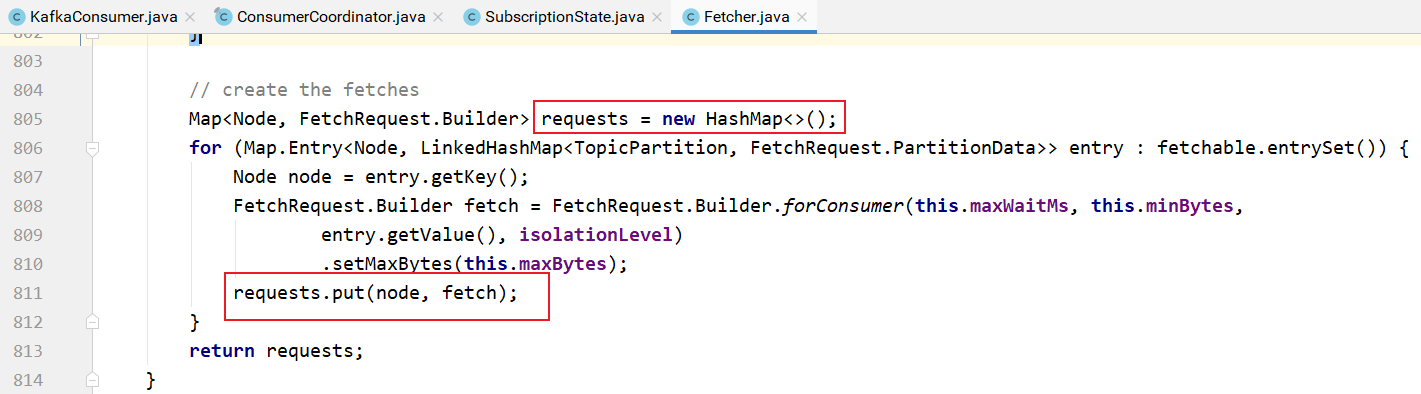
fetchablePartitions方法的实现:
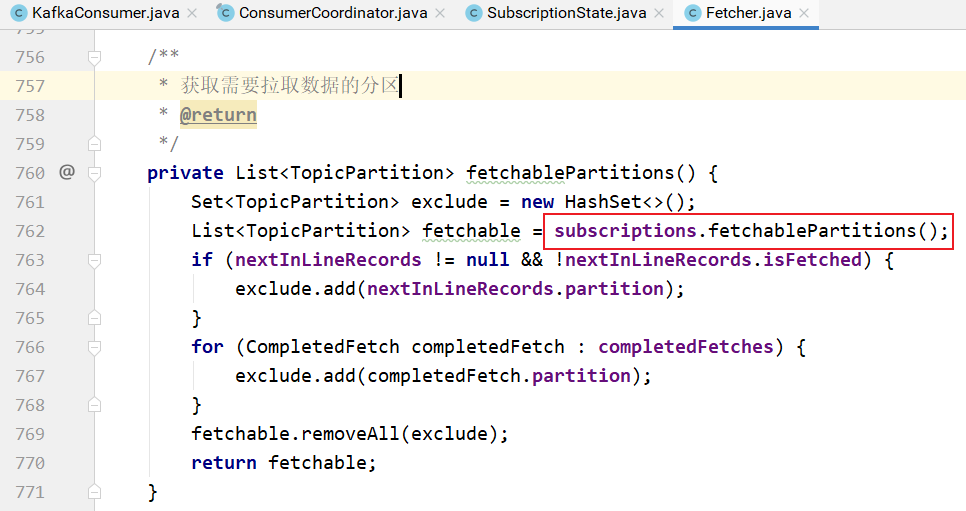
subscriptions.fetchablePartitions()方法的实现:

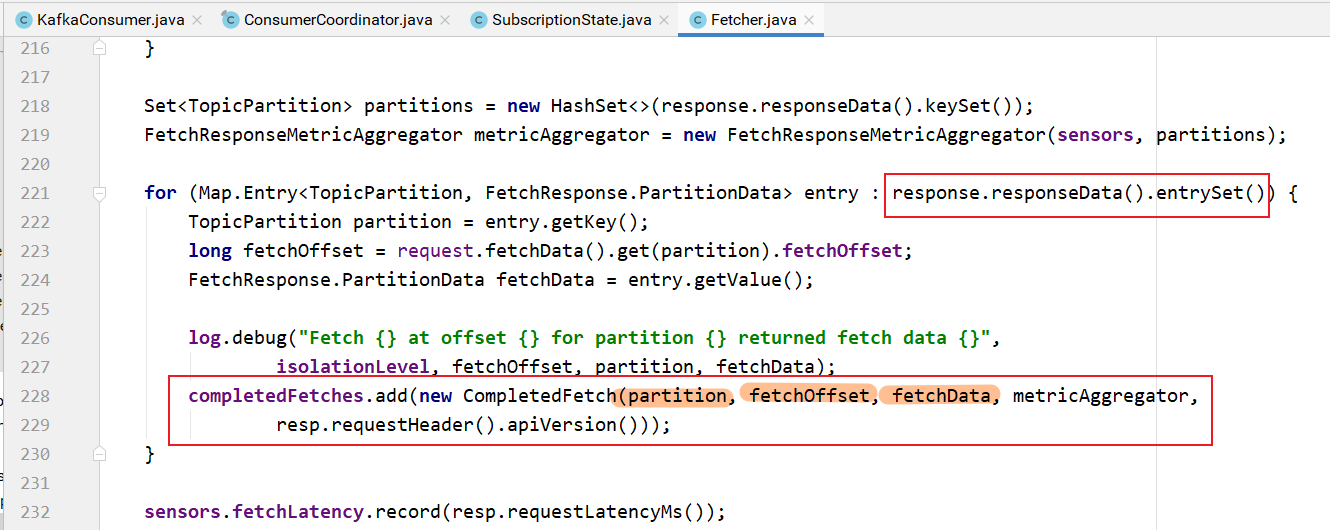
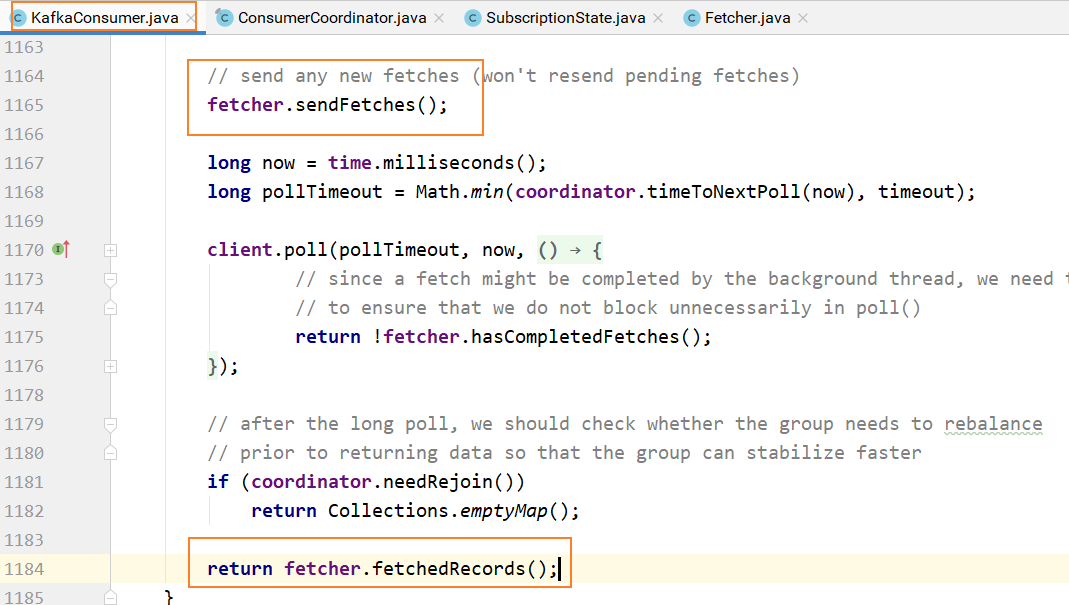
最终,pollOnce方法返回拉取的结果:
上次更新: 2025/04/03, 11:07:08
