 源码剖析-ReplicaManager
源码剖析-ReplicaManager
# 4.10 Kafka源码剖析之ReplicaManager
# 4.10.1 副本管理器的启动和ISR的收缩和扩展
在启动KafkaServer的时候,运行KafkaServer的startup方法。在该方法中实例化ReplicaManager,并调用ReplicaManager的startup方法:

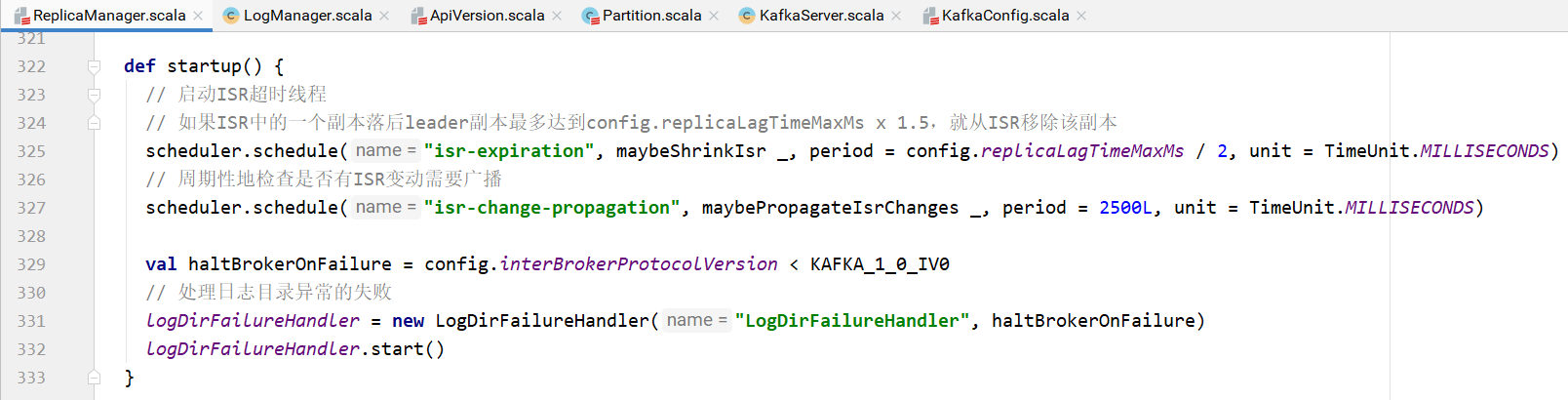
ReplicaManager的startup方法:
处理ISR收缩的情况:

def maybeShrinkIsr(replicaMaxLagTimeMs: Long) {
val leaderHWIncremented = inWriteLock(leaderIsrUpdateLock) {
leaderReplicaIfLocal match {
case Some(leaderReplica) =>
// 获取ISR中的不同步副本
val outOfSyncReplicas = getOutOfSyncReplicas(leaderReplica,replicaMaxLagTimeMs)
// 如果该集合不为空,则需要收缩ISR
if(outOfSyncReplicas.nonEmpty) {
// 从ISR中除去非同步副本
val newInSyncReplicas = inSyncReplicas -- outOfSyncReplicas
assert(newInSyncReplicas.nonEmpty)
info("Shrinking ISR from %s to %s".format(inSyncReplicas.map(_.brokerId).mkString(","),
newInSyncReplicas.map(_.brokerId).mkString(",")))
// 在缓存和zk中更新ISR
updateIsr(newInSyncReplicas)
// 标记ISR收缩事件
replicaManager.isrShrinkRate.mark()
// 由于ISR可能发生变化,变为1,如果ISR发生变化,需要增加HW
maybeIncrementLeaderHW(leaderReplica)
} else {
false
}
// 如果leader不在当前broker,则什么都不做
case None => false
}
}
// 当更新HW之后,尝试完成因ISR收缩而阻塞的操作。
if (leaderHWIncremented)
tryCompleteDelayedRequests()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
对于在ISR集合中的副本,检查有没有需要从ISR中移除的:
两种情况需要从ISR中移除:
卡主的Follower:如果副本的LEO经过maxLagMs毫秒还没有更新,则Follower卡主了,需要从ISR移除
慢Follower:如果副本从maxLagMs毫秒之前到现在还没有读到leader的LEO,则Follower落后,需要从ISR移除。
处理ISR变动事件广播:
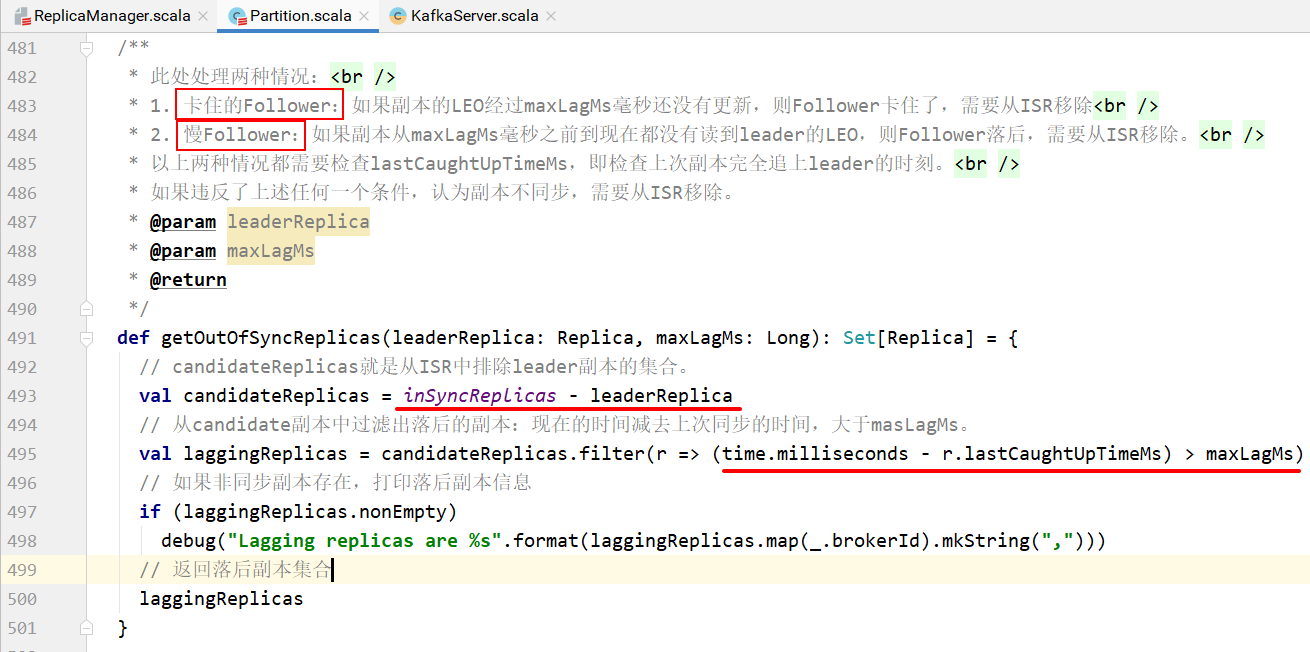
同时startup方法中周期性地调用maybePropagateIsrChanges()方法:
该函数周期性运行,检查ISR是否需要扩展。两种情况发生ISR的广播:
- 有尚未广播的ISR变动
- 最近5s没有发生ISR变动,或者上次ISR广播已经过去60s了。
该方法保证在ISR偶尔发生变动时,几秒之内即可将ISR变动广播出去。
避免了当发生大量ISR变更时压垮controller和其他broker。
处理日志目录异常的失败:

# 4.10.2 follower副本如何与leader同步消息
副本管理器类:
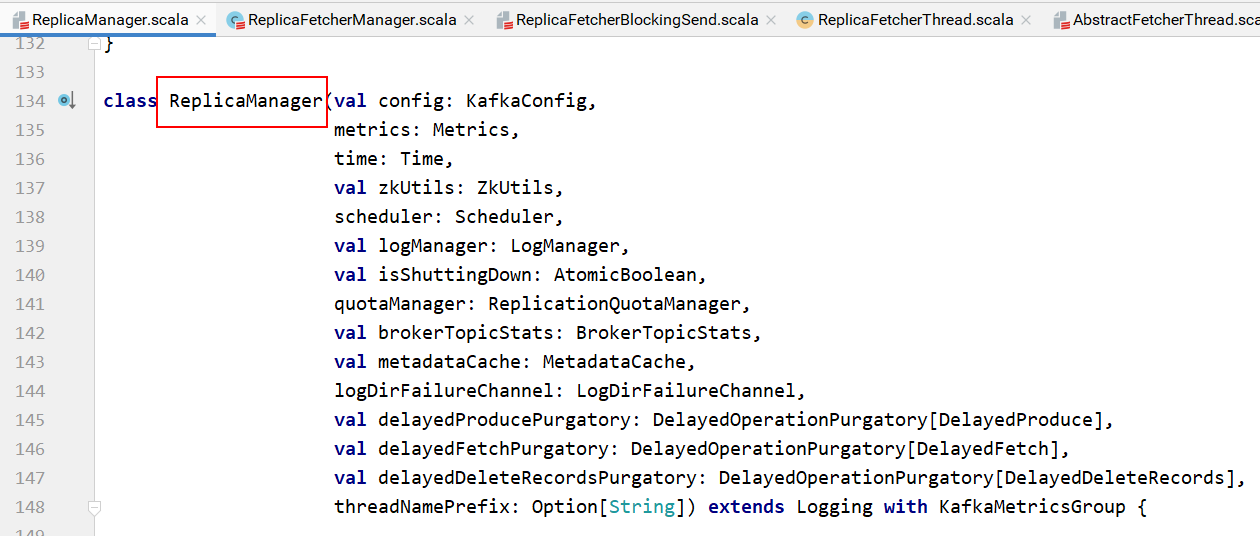
副本管理器类在实例化的时候创建ReplicaFetcherManager对象,该对象是负责从leader拉取消息与leader保持同步的线程管理器:

方法的具体实现:
创建负责从leader拉取消息与leader保持同步的线程管理器:

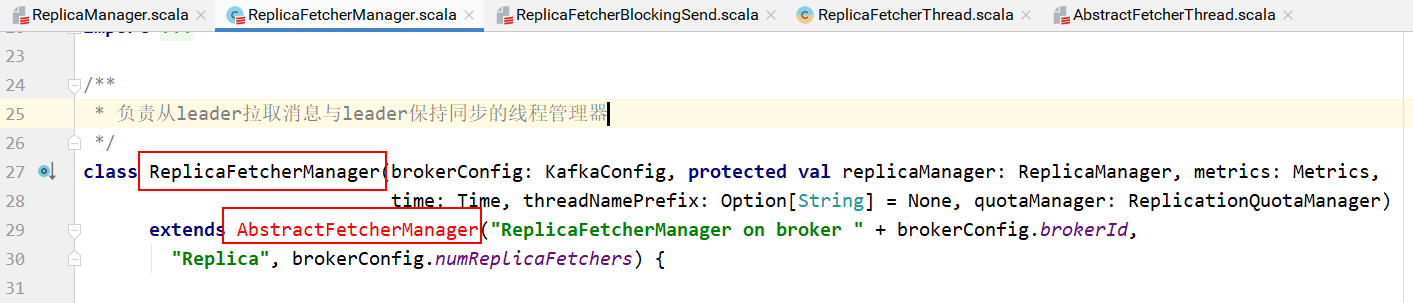
副本拉取管理器中实现了createFetcherThread方法,该方法返回ReplicaFetcherThread对象:

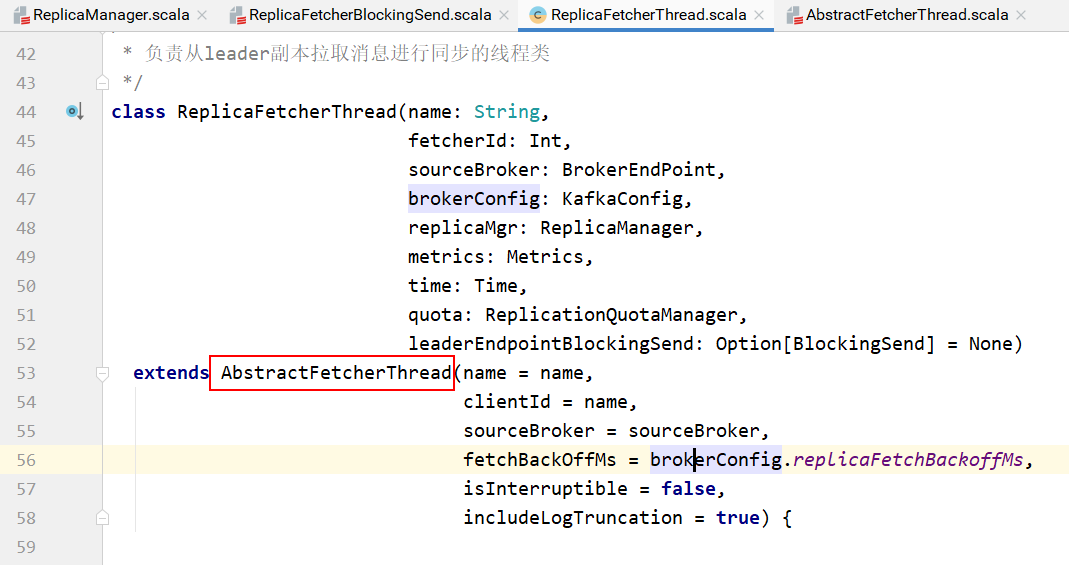
ReplicaFetcherThread线程负责从Leader副本拉取消息进行同步。
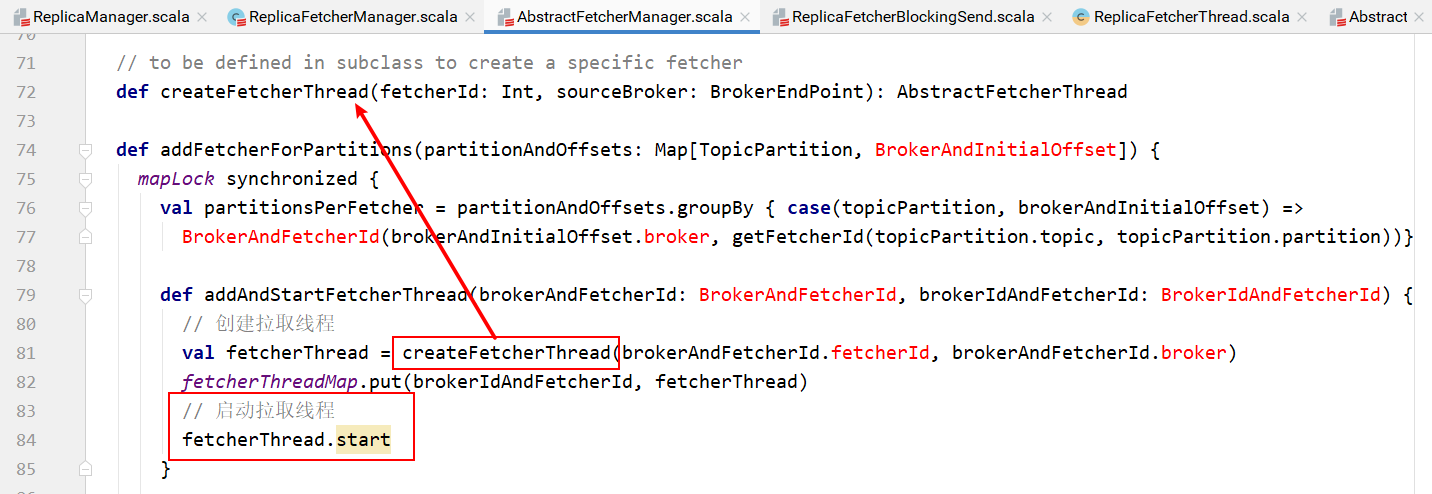
AbstractFetcherManager中的addFetcherForPartitions方法中的嵌套方法addAndStartFetcherThread创建并启动拉取线程:
而其中用到的createFetcherThread方法便是在AbstractFetcherManager的实现类ReplicaFetcherManager中实现的。
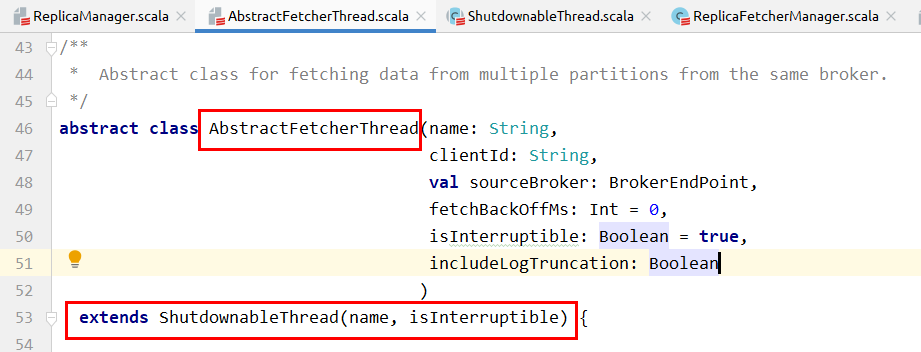
抽象类AbstractFetcherThread从同一个远程broker上为当前broker上的多个分区follower副本拉取消息。
即,在远程同一个broker上有多个leader副本的follower副本在当前broker上。
ReplicaFetcherThread的start方法实际上就是AbstractFetcherThread中的start方法。
在AbstractFetcherThread中没有start方法,在其父类ShutdownableThread也没有start方法:

但是ShutdownableThread继承自Thread,Thread中有start方法,并且start方法要调用run方法,在ShutdownableThread中有run方法:

该run方法重复调用doWork方法进行数据的拉取。
doWork方法是抽象方法,没有实现。其实现在ShutdownableThread的实现类AbstractFetcherThread中:

上图中的doWork方法会反复调用,上图中的方法创建拉取请求对象,然后调用processFetchRequest方法进行请求的发送和结果的处理。


fetch方法的实现在AbstractFetcherThread的子类ReplicaFetcherThread中:
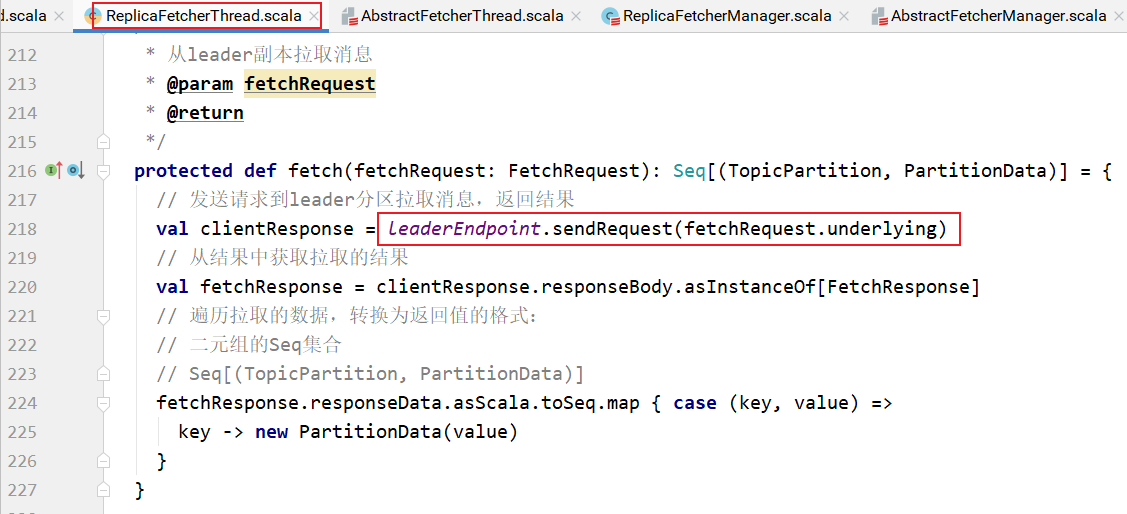
sendRequest方法在ReplicaFetcherBlockingSend中:

通过NetworkClientUtils发送请求,并等待请求的响应:

KafkaApis对Fetch的处理:


该方法中,Leader从本地日志读取数据,返回:

总结:
当KafkaServer启动的时候,会实例化副本管理器

副本管理器实例化的时候会实例化副本拉取器管理器:

副本管理器中有实现createFetcherThread方法,创建副本拉取器对象

拉取线程启动起来之后不断地从leader副本所在的broker拉取消息,以便Follower与leader保持消息的同步。
